IT问题越来越复杂,为什么最后总是没人负责?



在很多企业中,一个越来越常见的现象是:问题发生之后,大家都在处理,但最后却很难明确“到底谁负责”。
例如,一个系统故障可能涉及网络、数据库、中间件、业务系统甚至第三方接口。问题出现后,不同团队都会参与排查,但随着时间推移,沟通越来越多,责任却越来越模糊。
很多时候,问题最终虽然被解决,但整个过程却伴随着大量“责任漂移”:
- “这个问题不属于我们系统”
- “我们这里只是受到影响”
- “需要等其他团队确认”
- “根因还在进一步分析”
从表面上看,这是协作问题。但从更深层来看,这其实是复杂 IT 环境中的一种典型现象:随着系统关系越来越复杂,责任开始变得越来越难以定义。
很多企业已经上线 ITSM系统,也建立了事件与问题流程,但问题依然存在。因为流程可以定义“步骤”,却未必能够真正定义“责任边界”。
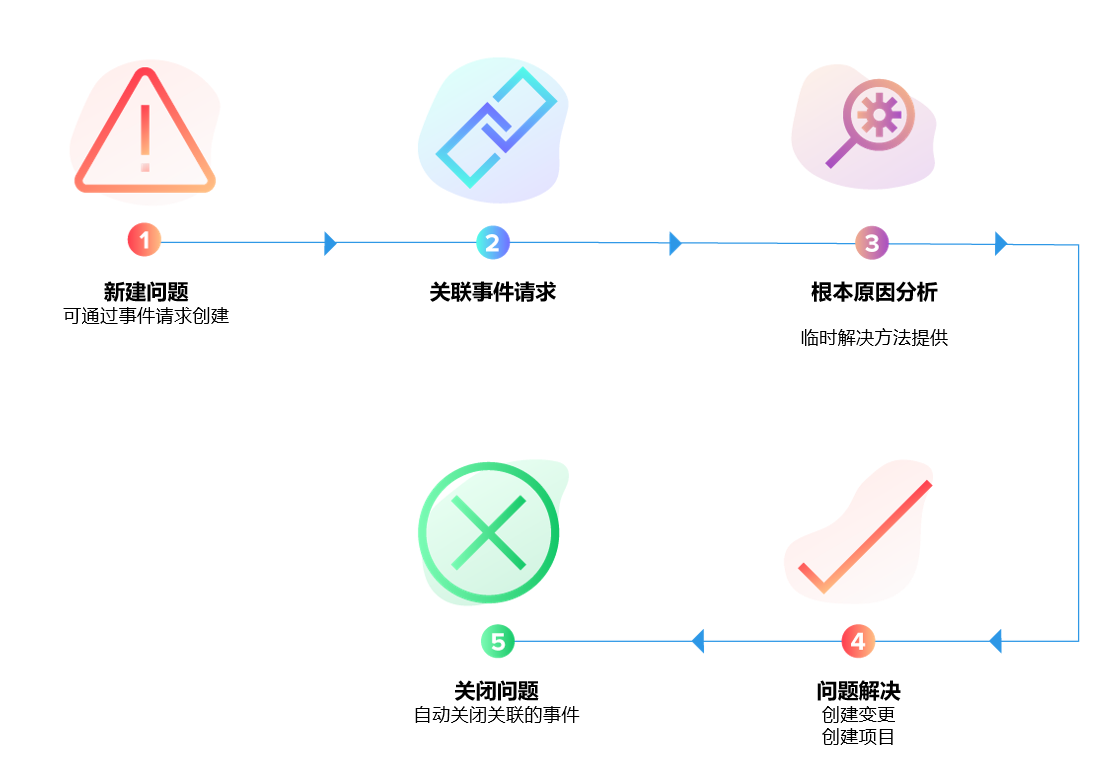
为什么系统越复杂,责任越容易“漂移”
在早期 IT 环境中,系统边界通常比较清晰。一个应用对应一个团队,一个问题也往往能够快速找到责任方。
但随着企业数字化深入,系统之间开始形成复杂依赖关系。很多业务流程已经不再由单一系统完成,而是由多个系统协同运行。
这意味着,一个问题可能并不存在“单一责任方”。
例如,一个用户无法完成支付,可能涉及:
- 前端系统请求异常
- 中间件延迟
- 数据库锁等待
- 第三方支付接口超时
- 网络抖动导致数据丢失
在这种环境中,责任会天然变得“分散化”。因为每个团队都只掌握系统中的一部分信息。
当组织缺乏统一视图时,问题就会逐渐从“技术故障”演变成“责任协调问题”。
真正导致责任漂移的,并不是“没人做事”
很多管理者在面对问题时,第一反应通常是:“是不是大家缺乏责任心?” 但在复杂 IT 环境中,责任漂移往往并不是因为没人愿意做事,而是因为系统复杂度已经超过了单一团队的理解范围。
也就是说,问题的核心并不是“态度问题”,而是“认知问题”。
在现代企业中,一个业务流程可能跨越多个系统、多个团队甚至多个外部供应商。每个人看到的,往往只是整体链路中的一小部分。
因此,当问题发生时,团队会自然从自己的视角出发进行判断:
- 数据库团队认为数据库运行正常
- 网络团队认为链路没有中断
- 应用团队认为代码没有改动
- 第三方供应商认为接口状态正常
从各自角度来看,大家都没有“明显问题”。但整体业务却已经受到影响。
这种情况会导致一个非常典型的结果:每个团队都在解释“自己为什么不是问题源头”,但却没有人真正掌握完整链路。
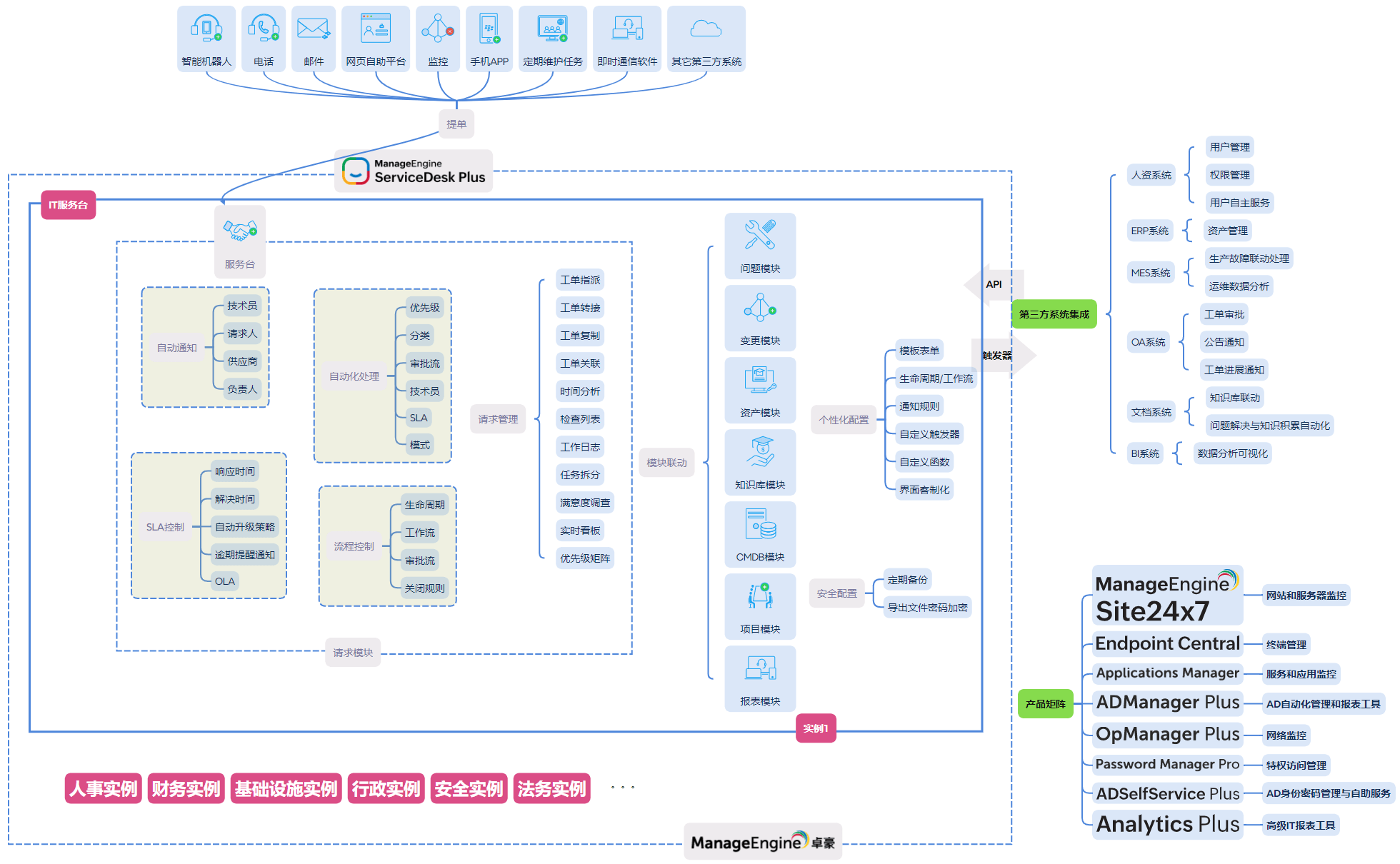
为什么流程越复杂,责任边界越模糊
很多企业在问题频发之后,会继续增加流程,希望通过更严格的管理减少责任不清。例如增加审批、增加记录、增加汇报机制。
这些动作在短期内确实能够增强“可追溯性”,但它们未必能够真正解决责任问题。
因为随着流程越来越复杂,组织中的“参与者”也会越来越多。而参与者越多,责任就越容易被“平均化”。
例如,一个问题如果只涉及一个团队,那么责任通常很明确;但如果同时涉及五个团队,那么组织会逐渐从“明确负责人”转向“集体协调”。
一旦进入这种状态,责任就会开始漂移。因为每个人都在参与,但又很难有人真正拥有“全局责任”。
最终,问题虽然会被处理,但整个过程会越来越依赖沟通协调,而不是结构化管理。
为什么“责任不清”会逐渐演变成组织低效
责任漂移带来的影响,并不仅仅是沟通变多。
更深层的问题在于:组织会逐渐进入一种“低决策效率”状态。
因为当责任边界不清晰时,团队会自然倾向于:
- 减少主动决策
- 等待更多确认
- 依赖跨团队会议
- 避免承担最终判断责任
久而久之,组织会越来越依赖“协调机制”,而不是“清晰结构”。
这也是为什么很多企业在系统规模扩大之后,会感觉 IT 问题处理越来越慢。因为真正消耗时间的,往往已经不是技术处理,而是“责任确认”。
因此,很多 IT 问题的本质,已经不只是技术问题,而是“复杂组织中的责任治理问题”。
真正的问题,不是“谁背锅”,而是“谁拥有全局”
很多企业在面对责任漂移时,会本能地加强问责。例如要求明确负责人、强化事故复盘、增加责任追踪机制。
这些动作当然重要,但如果组织结构本身缺乏“全局可见性”,那么责任问题仍然会持续出现。
因为在复杂系统环境中,真正稀缺的并不是“执行者”,而是能够理解整体链路的人。
也就是说,组织真正需要建立的,不只是“责任归属”,而是“全局 ownership(整体拥有感)”。
只有当某些角色能够从业务整体视角理解问题时,组织才不会陷入无限协调与责任漂移。
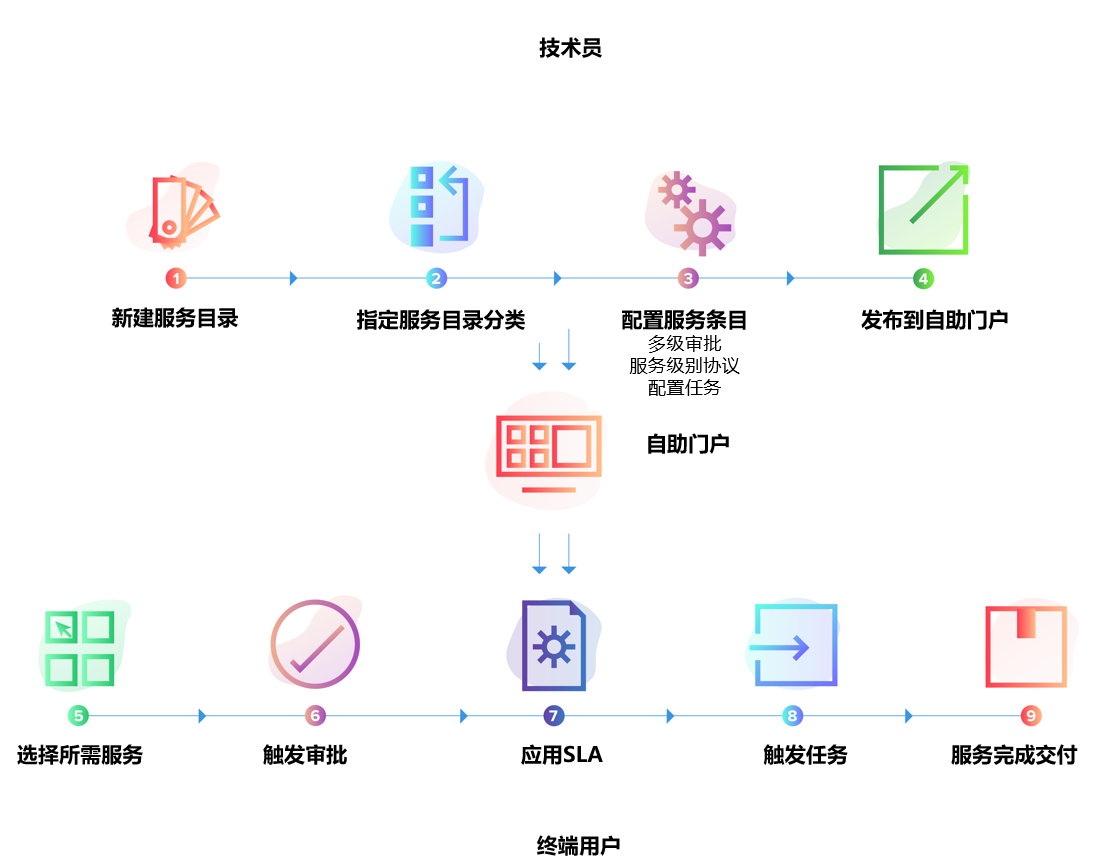
案例:为什么有些企业问题越来越多,却始终找不到负责人
A 公司在业务扩张后,系统数量迅速增加。不同系统由不同团队维护,组织也建立了完整的 IT 服务流程。
但随着系统复杂度上升,问题处理开始越来越困难。一次业务故障往往需要多个团队共同参与排查,会议越来越多,沟通越来越频繁,但问题恢复速度却越来越慢。
更严重的是,很多问题在复盘时依然无法明确根因。因为从单一团队视角来看,每个系统都“基本正常”。
最终,组织开始形成一种典型状态:问题有人处理,但没人真正“拥有问题”。
相比之下,B 公司在推进 IT服务管理 时,并没有单纯增加流程,而是重点建设“全链路责任视图”。
例如,他们会明确业务链路 owner,而不是只定义系统 owner;在问题处理中,系统会自动关联影响范围、资产依赖与历史问题,从而帮助团队快速形成整体视角。
这种方式使 B 公司即使面对复杂问题,也能够快速确定整体责任与处理路径,而不是长期陷入跨团队协调。
这说明:真正高效的组织,并不是“每个人负责自己的部分”,而是始终有人能够理解整个系统如何协同运行。
如何从“责任漂移”转向“责任治理”
企业如果想真正解决责任问题,需要改变一个核心逻辑:IT 问题管理 不只是流程流转,而是“系统级协同治理”。
这意味着,组织不仅需要定义“谁处理”,还需要建立“谁理解整体”的能力。
在实践中,这通常意味着几个关键变化:
- 建立统一资产与依赖关系视图
- 明确业务链路级 owner,而不只是系统 owner
- 让问题影响范围能够自动关联
- 减少跨团队信息断层
- 通过历史问题数据形成整体认知能力
在这一过程中,ServiceDesk Plus可以通过资产关系、问题管理与变更联动能力,帮助企业建立统一 ITSM 视图,使问题不再停留在“单点排查”,而能够从整体结构层面进行治理。
当组织真正拥有“全局视角”时,责任才不会继续漂移。
写在最后:未来企业真正重要的,是“系统级协同能力”
未来企业的 IT 环境只会越来越复杂。系统数量持续增加、跨部门协作持续增强、业务依赖关系也会越来越深。
在这样的环境中,问题已经很难再由单一团队独立解决。
因此,IT 服务管理 的下一阶段,核心不再只是“流程是否规范”,而是组织是否具备真正的系统级协同能力。
只有能够建立统一视图与整体 ownership 的企业,才能真正避免责任漂移,并在复杂环境中保持高效运行。
常见问题(FAQ)
- 为什么 IT 问题越来越难明确责任?
因为系统之间的依赖关系越来越复杂,单一团队很难掌握完整链路。 - 为什么大家都在处理问题,却还是效率低?
因为大量时间被消耗在跨团队协调与责任确认上。 - 企业如何减少责任漂移?
通过建立统一视图与全链路 ownership 机制提升整体协同能力。 - ITSM系统如何帮助责任治理?
通过资产关系、问题关联与统一流程提升全局可见性。
