服务韧性(Service Resilience):打造高可用、可恢复的企业 IT 工单管理体系



在过去很长一段时间里,企业对 IT 服务的核心期待只有一个:不要出事。然而随着业务数字化程度不断加深,这个目标本身已经不再现实。系统会出问题、网络会抖动、人员会变动、需求会激增——真正的差异不在于“是否出事”,而在于“出事之后,组织能否迅速恢复并保持服务连续性”。
这正是“服务韧性(Service Resilience)”概念的由来。它关注的不是绝对稳定,而是在不确定环境下的承压能力、恢复能力与持续交付能力。对于 IT 服务管理而言,韧性不再只是基础设施层面的高可用设计,而是贯穿工单、流程、人员与决策机制的系统能力。
在这一背景下,IT 工单管理体系的角色正在发生变化:它不再只是“问题记录工具”,而逐渐成为服务中断、风险暴露与恢复能力的核心载体。本文将从服务韧性的视角出发,深入解析企业如何通过工单体系构建高可用、可恢复、可治理的 IT 服务管理架构,并探讨 ServiceDesk Plus 在其中的实践价值。
一、为什么“稳定运行”已经不足以衡量 IT 服务能力
许多企业已经部署了 IT 工单管理系统, 也建立了基础的 ITSM 系统 流程,但当业务规模扩大、服务链路拉长时,这些体系往往暴露出一个共同问题:它们更擅长“处理已发生的问题”,而不擅长“承受持续的不确定性”。
在高度耦合的数字化环境中,单点故障往往会被迅速放大。如果 IT 服务管理仍停留在“关单即完成”的思维模式中,组织就很难识别潜在风险,更谈不上系统性恢复能力。这也是为什么越来越多企业开始将关注点从稳定性转向韧性。
1)稳定性关注结果,韧性关注过程
稳定性通常通过指标来衡量,例如可用率、宕机时间等。这些指标固然重要,但它们只能反映结果,而无法解释过程。当系统短时间内恢复,指标看似合格,但背后可能隐藏着高强度人工干预和不可复制的经验。
2)韧性强调“可恢复性”与“可预测性”
韧性关注的是:当问题发生时,组织是否有清晰的应对路径;当风险累积时,是否能够提前感知;当服务被打断时,是否可以在可控时间内恢复。这些能力的基础,恰恰体现在工单体系是否具备完整的流程、数据与责任链条。
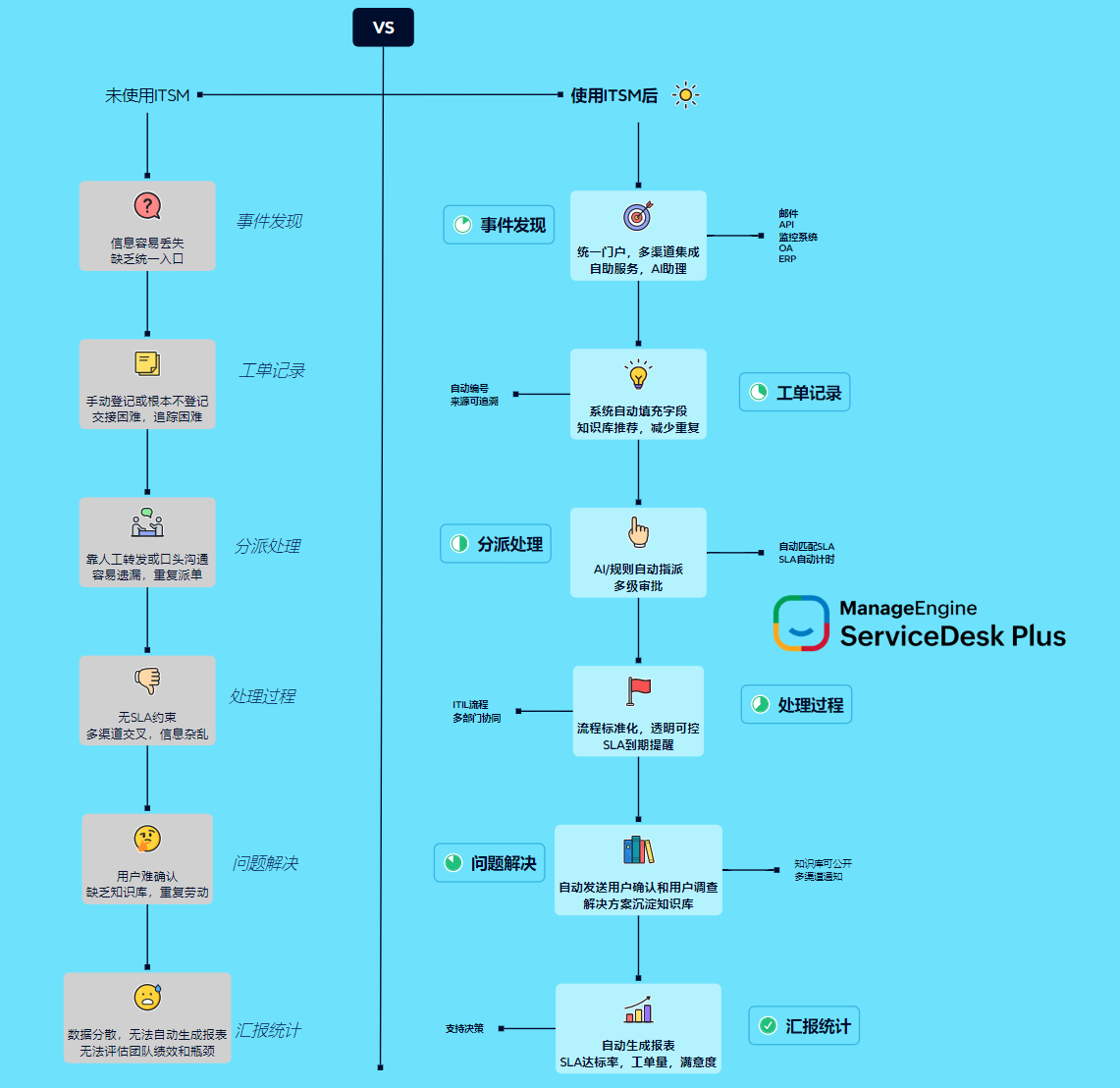
二、服务韧性的底层支撑:工单体系为什么是关键
在众多 IT 管理系统中,工单体系往往最贴近真实运行状态。无论是事件、问题还是变更,最终都会以工单的形式被记录、处理与复盘。这使得工单系统天然具备承载服务韧性信息的能力。
一个成熟的工单体系,不仅记录“发生了什么”,还应记录“是谁在什么条件下、以什么方式处理了问题”,以及“处理结果对服务产生了怎样的影响”。这些信息一旦结构化,就可以被用于评估服务的承压能力与恢复能力。
1)事件、问题与变更构成韧性闭环
服务韧性并不是靠单一流程实现的,而是通过事件管理、问题管理与变更管理的协同运作来构建。事件反映当下冲击,问题揭示结构性风险,变更则是改善与修复的手段。缺失任何一环,韧性都会被削弱。
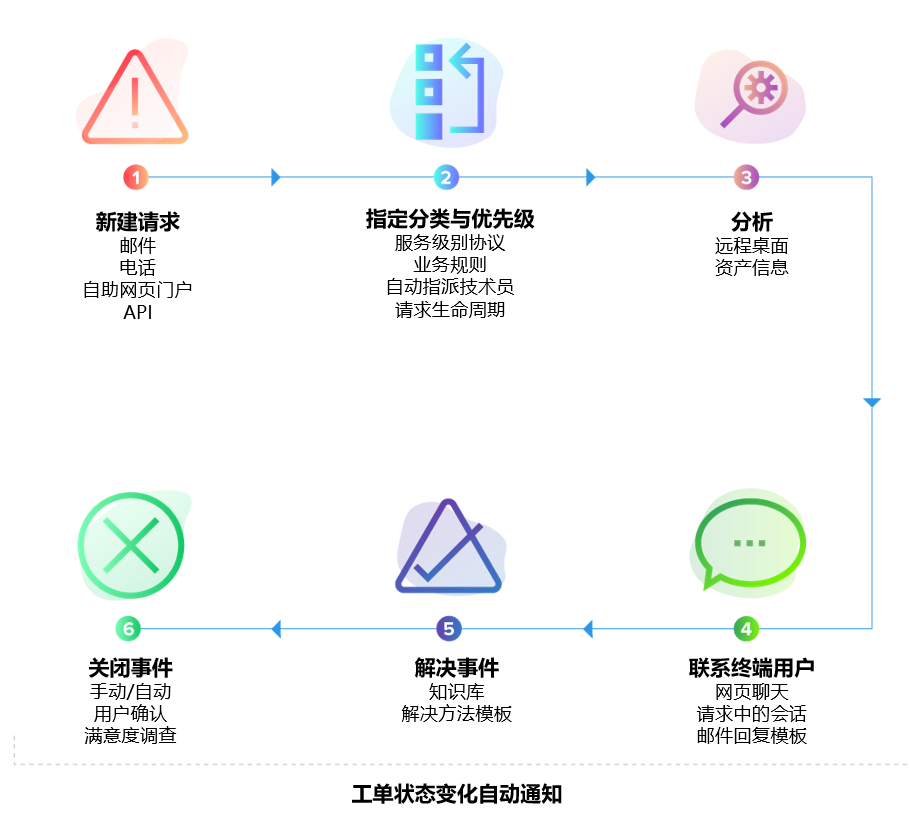
2)SLA 不只是承诺,而是恢复能力指标
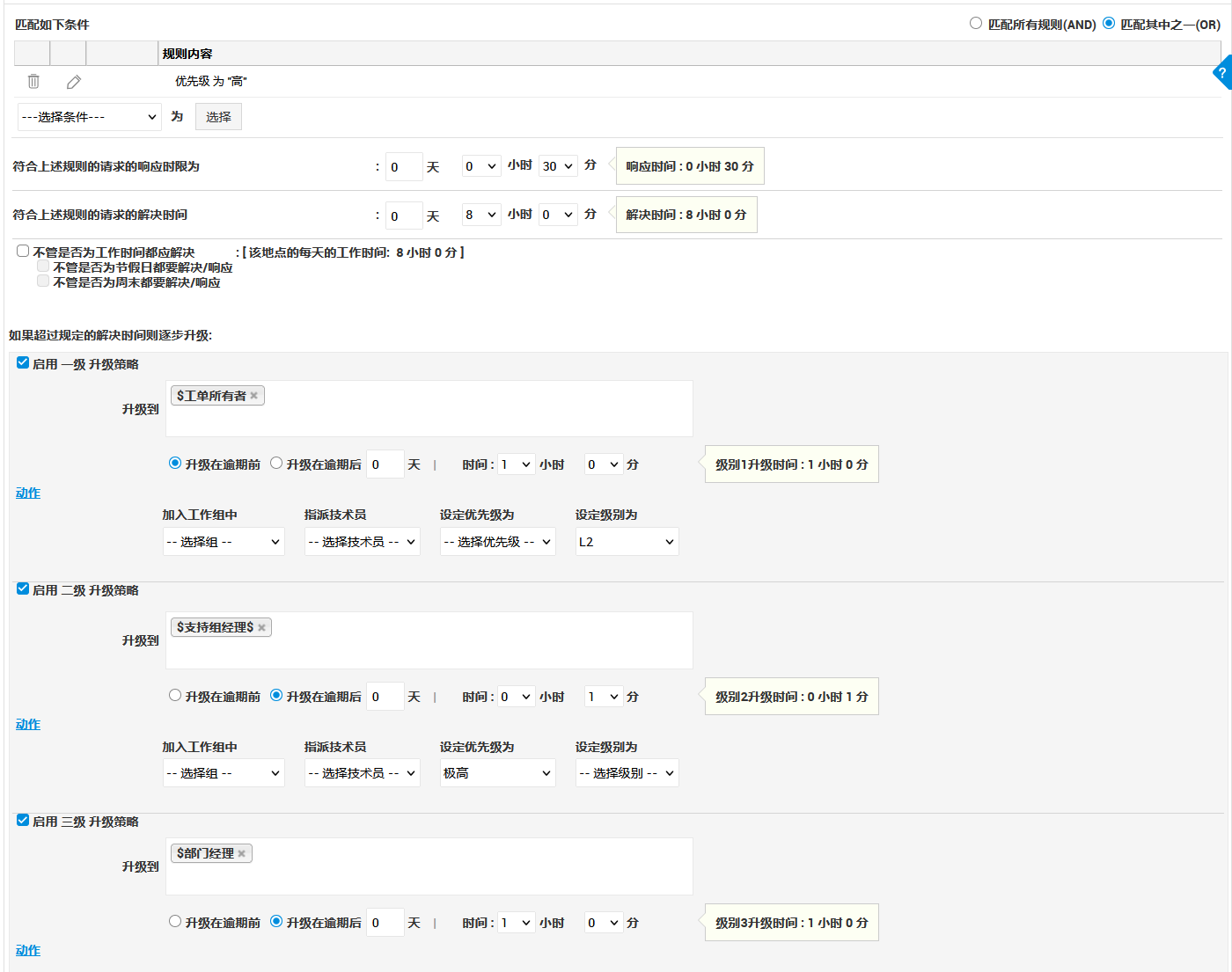
在韧性视角下,SLA 的意义发生了变化。它不再只是对业务的时间承诺,而是衡量组织在压力条件下的响应与恢复能力。当 SLA 与自动化、升级机制结合时,它可以成为提前暴露风险的重要信号。
三、构建高韧性 IT 工单体系的设计原则
将服务韧性落地到工单管理,并不意味着堆叠更多流程。相反,高韧性的体系往往遵循少而清晰的设计原则。本章将从流程结构、责任划分与信息完整性三个角度,探讨如何设计一个既稳定又灵活的工单体系。
让工单体系具备“承压与恢复”的结构能力
在高韧性组织中,工单体系并不会因为异常流量或突发事件而失效。相反,它会通过清晰的分层结构、自动化机制和责任映射,将冲击吸收并转化为可控流程。这种能力并非源自单一技术,而是源自整体设计。
首先,工单分类与优先级体系必须具备“动态调整能力”。当某一类事件在短时间内集中爆发时,系统应能够自动调整其优先级策略,确保关键业务不被淹没在大量低价值请求中。这种机制,是韧性体系中“止血”的第一步。
其次,工单体系需要具备“快速重组流程”的能力。高韧性并不意味着流程复杂,而是意味着流程可以根据风险等级和影响范围被临时重构。例如,在重大故障期间,审批节点可以被自动跳过,升级链路可以被压缩,以保障恢复效率。
四、真实案例:一家多地点企业如何构建服务韧性
某全国性集团企业在多个城市设有办公地点与数据中心。随着业务扩张,其 IT 团队逐渐发现一个问题:单次故障的影响范围越来越大,而恢复时间却难以稳定控制。传统“救火式”工单处理方式已经无法满足连续性要求。
在重构 IT 服务管理体系时,该企业并未一开始就追求“零故障”,而是明确提出目标:即使发生故障,也要在可预测时间内恢复核心服务。这一目标,直接推动了工单体系的韧性化设计。
阶段一:统一入口,消除信息延迟
该企业首先通过统一服务门户,将分散在电话、邮件、即时通讯工具中的请求集中到工单系统中。此举并未立刻减少工单数量,但显著缩短了信息收集时间,为后续自动化与分析打下基础。
阶段二:建立分级响应与恢复路径
在此基础上,团队为关键系统建立专属流程与 SLA。当高优先级事件出现时,系统会自动触发升级规则,通知跨部门负责人并启动预案。这使得恢复过程从“临场指挥”转变为“按图执行”。
阶段三:用数据复盘提升长期韧性
每次重大事件结束后,系统会自动生成分析视图,帮助团队评估恢复耗时、资源投入与流程有效性。这些数据被用于优化后续流程,使组织在每一次冲击后都“更强一点”。
五、从服务韧性到服务治理:形成持续改进闭环
韧性并不是孤立目标,它最终应服务于治理。当工单体系能够稳定承载冲击并记录恢复路径时,组织就获得了进行系统性治理的基础。
治理的关键在于闭环:事件 → 分析 → 改进 → 验证。没有数据支持的改进往往流于形式,而没有流程承载的改进则难以持续。工单体系正是连接这两个维度的枢纽。
六、ServiceDesk Plus 如何支撑高韧性 IT 服务管理
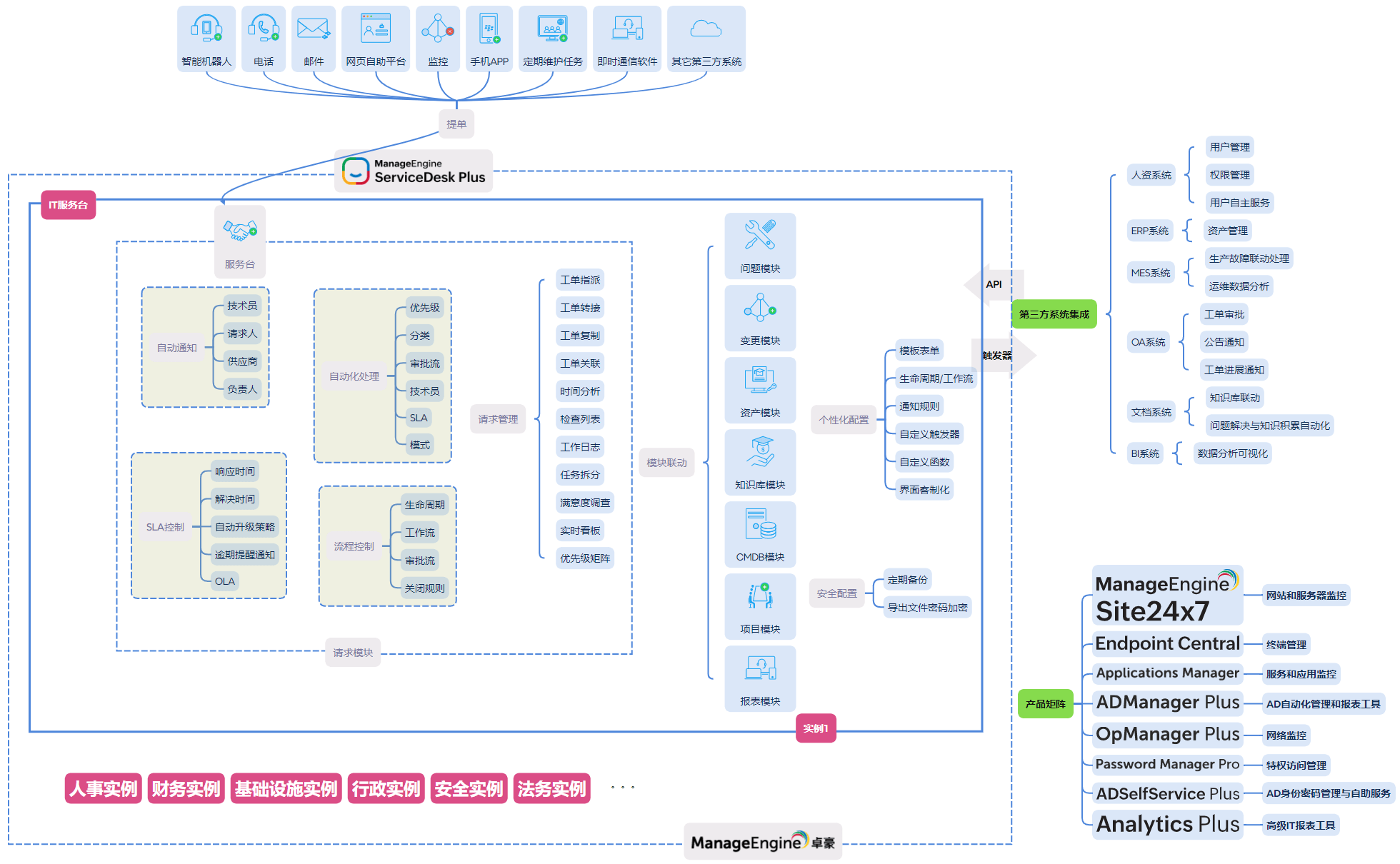
ServiceDesk Plus 通过统一平台,将工单、流程、资产、自动化与报表整合在一起,为企业构建服务韧性提供了完整工具集。企业无需额外搭建复杂系统,即可逐步增强服务的承压与恢复能力。
无论是通过 SLA 和升级规则确保响应可控,还是通过仪表板洞察服务趋势,ServiceDesk Plus 都让韧性成为可管理、可度量、可持续改进的能力,而非抽象目标。
常见问题
Q1:服务韧性是否只适合大型企业?
并非如此。规模越小,越需要通过体系化方式避免单点依赖,服务韧性同样重要。
Q2:构建韧性是否意味着流程变复杂?
恰恰相反,高韧性体系通常依赖清晰而非冗余的流程设计。
Q3:如何评估服务韧性是否在提升?
可从恢复时间、重复事件率、升级频率与业务满意度等维度综合评估。

立即体验ServiceDesk Plus。
- 更喜欢云版本?注册试用:点击注册免费试用ServiceDesk Plus(30天全功能);
- 希望本地部署?下载地址:下载ServiceDesk Plus本地版(5个技术员永久免费!);
- 预约专家:需要定制化演示?立即预约1对1方案产品讲解;
- 获取报价,联系销售:填写信息,获取专属报价
限时福利:本月下载注册的用户赠送1小时配置指导服务,助力快速上线!