构建面向不确定性的企业 ITSM 运行体系



在多数企业的 ITSM 实践中, IT 工单系统、IT 事件管理 与 SLA 服务级别协议 长期被视为“被动响应工具”——当问题发生时记录、分派、解决、关闭。
然而,随着业务系统复杂度的持续上升,这种“响应型 ITSM”正在暴露出明显瓶颈: 问题被解决了,但组织依然脆弱;工单被关闭了,但中断仍在反复发生。
越来越多 CIO 开始意识到,真正成熟的 IT 服务管理,不应只关注“恢复速度”, 而应关注系统在不确定环境下的持续运行能力与自我修复能力——也就是 IT 韧性。
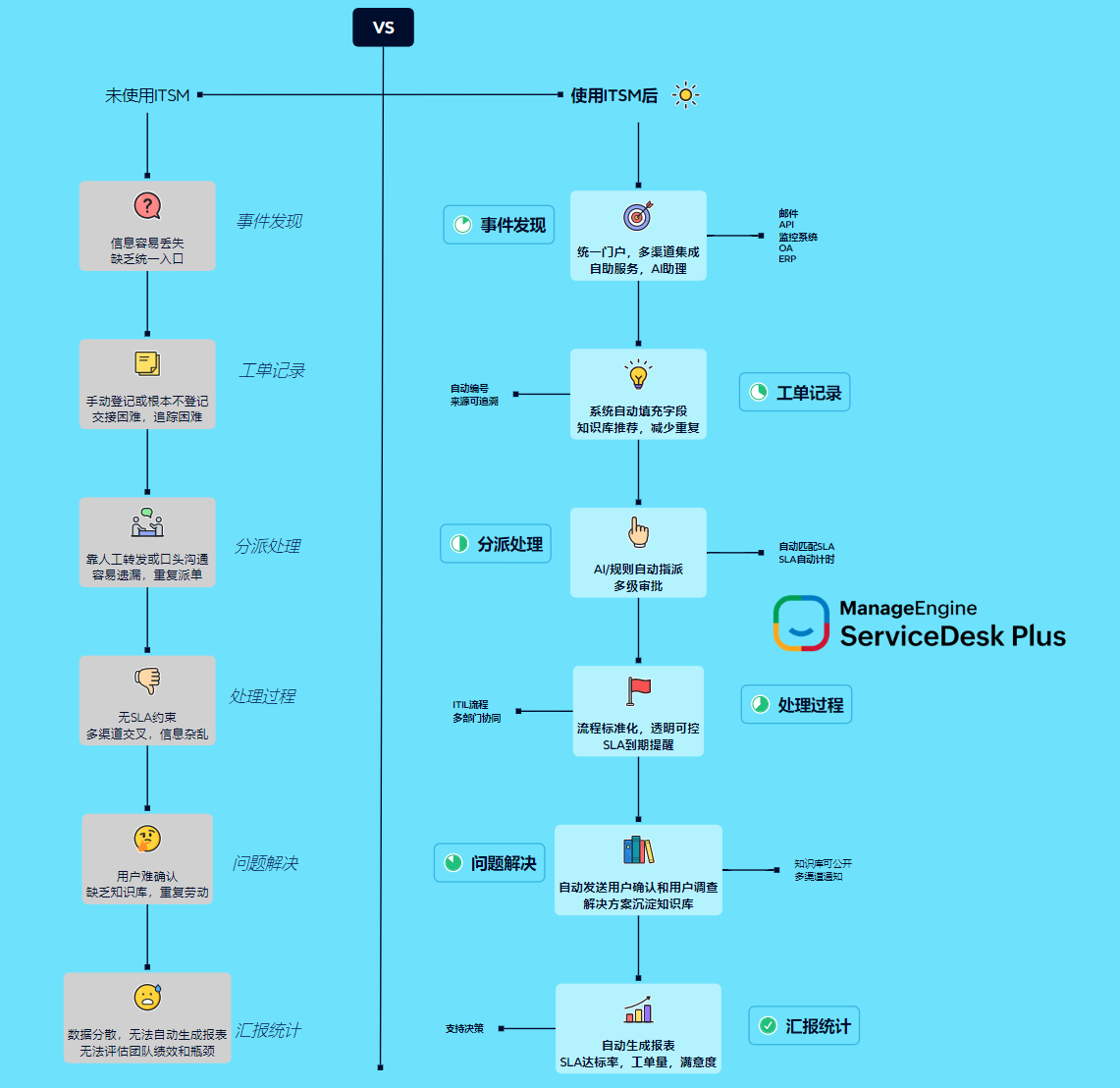
一、为什么“响应型 ITSM”正在失效
传统 ITSM 模型假设:故障是偶发的、可快速定位的、影响范围有限的。 但现实情况恰恰相反——
- 云与微服务架构放大了故障传播速度
- 跨部门流程让问题边界变得模糊
- 外部依赖(SaaS、API、第三方)不可控
在这种环境下,单纯追求“更快关闭工单”,往往只是在掩盖系统性风险。
常见失效表现
- 同类事件反复出现,却始终未进入问题管理
- SLA 达标,但业务满意度持续下降
- 变更后短期恢复,长期不稳定
二、IT 韧性导向的 ITSM 是什么
IT 韧性并不等同于“零故障”,而是指组织在面对不可避免的中断时, 能够快速吸收冲击、限制影响、并从中学习。
在 ITSM 体系中,这意味着服务管理的目标需要发生根本性转变:
- 从“事件是否解决”转向“事件是否可预测”
- 从“单点恢复”转向“系统级稳定性”
- 从“人工经验”转向“数据驱动决策”
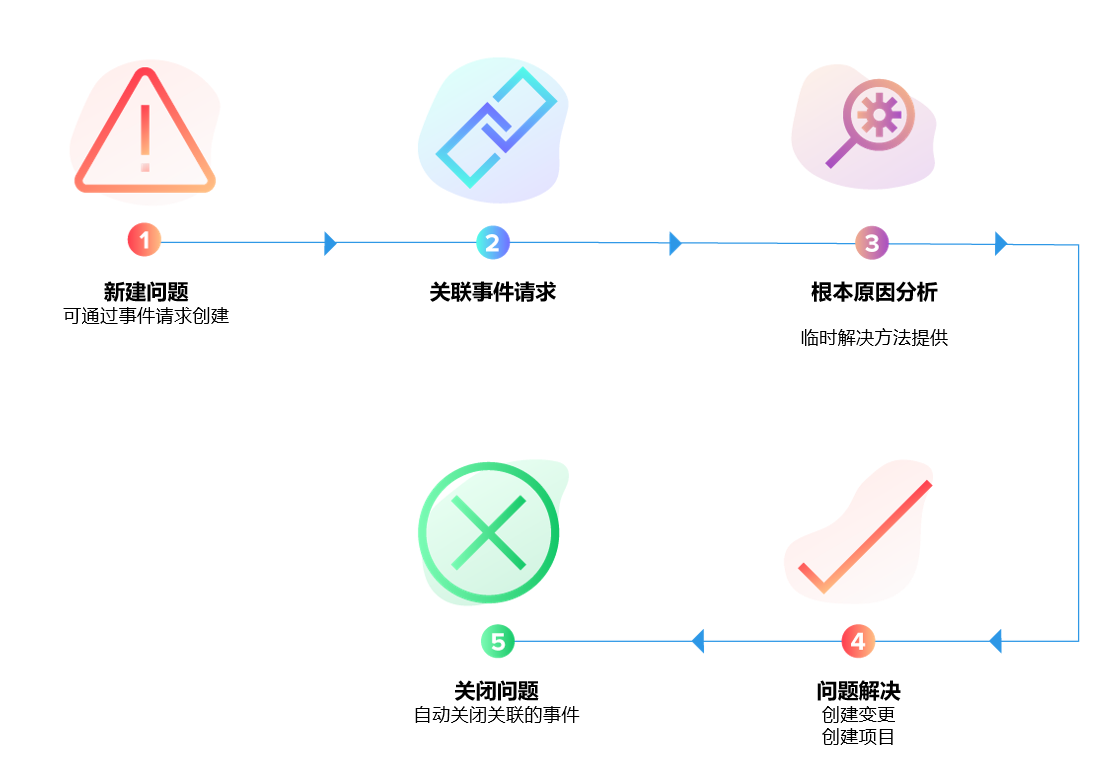
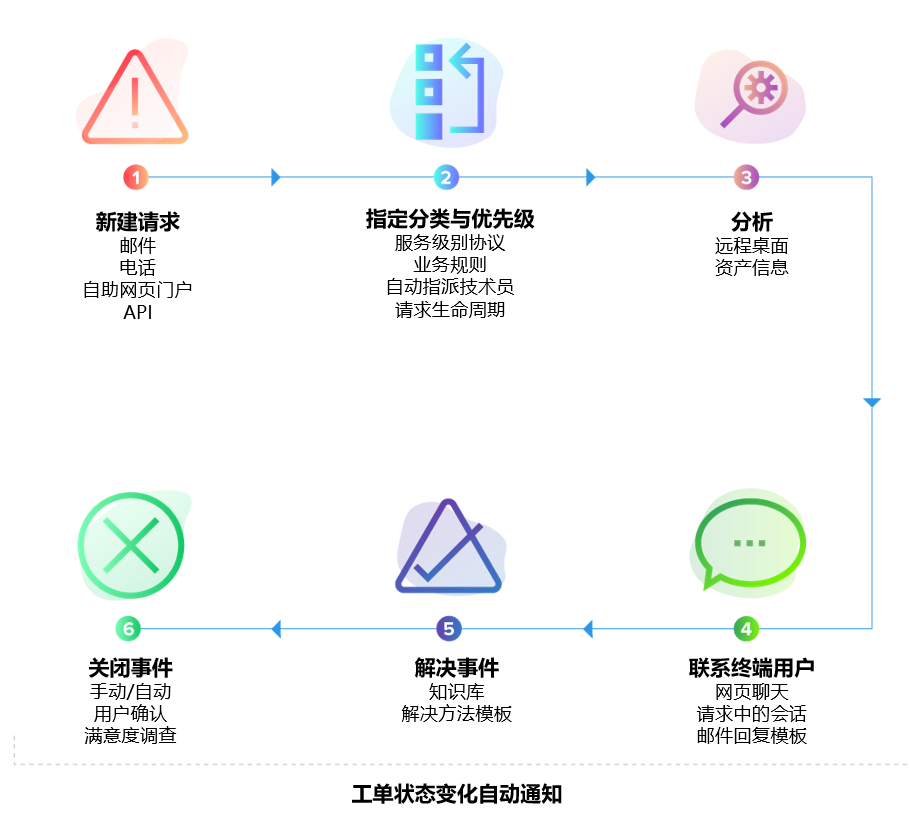
三、构建 IT 韧性的三层 ITSM 能力模型
第一层:可观测的运行数据
没有高质量数据,就不存在韧性。事件、变更、资产、配置项与用户行为, 必须在统一平台中形成可分析的数据基础。
第二层:跨流程关联分析
事件不应被孤立处理,而应与近期变更、资产状态、历史问题记录形成上下文关联。
第三层:持续反馈与自我修正
通过问题管理、变更评估与知识沉淀,让系统在每一次中断后变得更稳定。
四、让 ITSM 真正“有韧性”的治理机制
在多数组织中,ITSM 的失败并非源于工具能力不足,而是治理机制缺位。 没有清晰的责任边界、评估指标与复盘闭环,再先进的 IT 工单系统, 也只能停留在“救火队”角色。
韧性导向的 ITSM 治理,关注的不是单一流程是否合规, 而是系统是否具备自我纠偏能力。
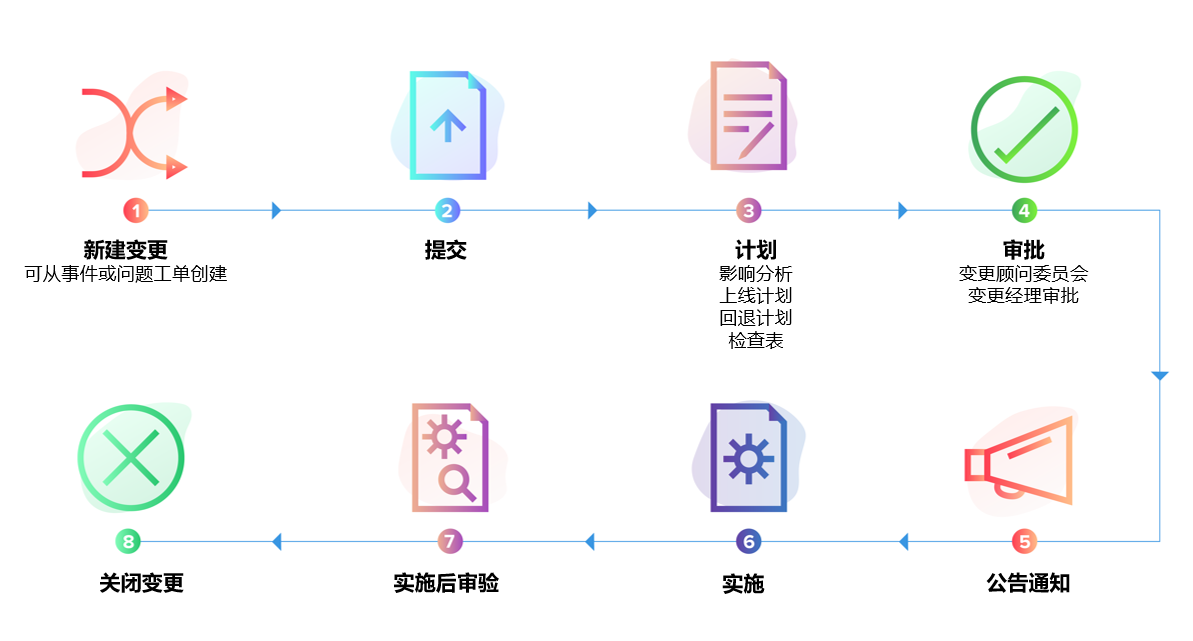
1. 明确“谁对稳定性负责”
在传统模式下,事件解决责任往往止步于技术员个人。 而在韧性模型中,问题与稳定性应上升为服务负责人层面的职责。
- 服务负责人对重复事件承担解释责任
- 问题管理必须有明确的关闭标准
- 高风险变更需绑定业务影响评估
2. 用指标衡量“是否更稳定”
SLA 只是底线,而非目标。真正衡量 IT 韧性的指标,通常包括:
- 重复事件发生率
- 问题转化率(事件 → 问题)
- 变更失败率与回滚率
- 平均恢复时间(MTTR)的趋势变化
五、IT 韧性落地路线图:从今天开始能做什么
构建韧性不是一次性项目,而是一条清晰的演进路径。 对大多数组织而言,可分为三个阶段:
阶段一:稳定现状
统一工单入口,规范事件分类与优先级, 确保所有中断都能被记录、被量化。
阶段二:减少重复
通过问题管理、知识库与变更评估, 降低“已知问题”的再次发生概率。
阶段三:提前预防
结合资产数据、历史事件与自动化规则, 在影响扩大前主动干预。
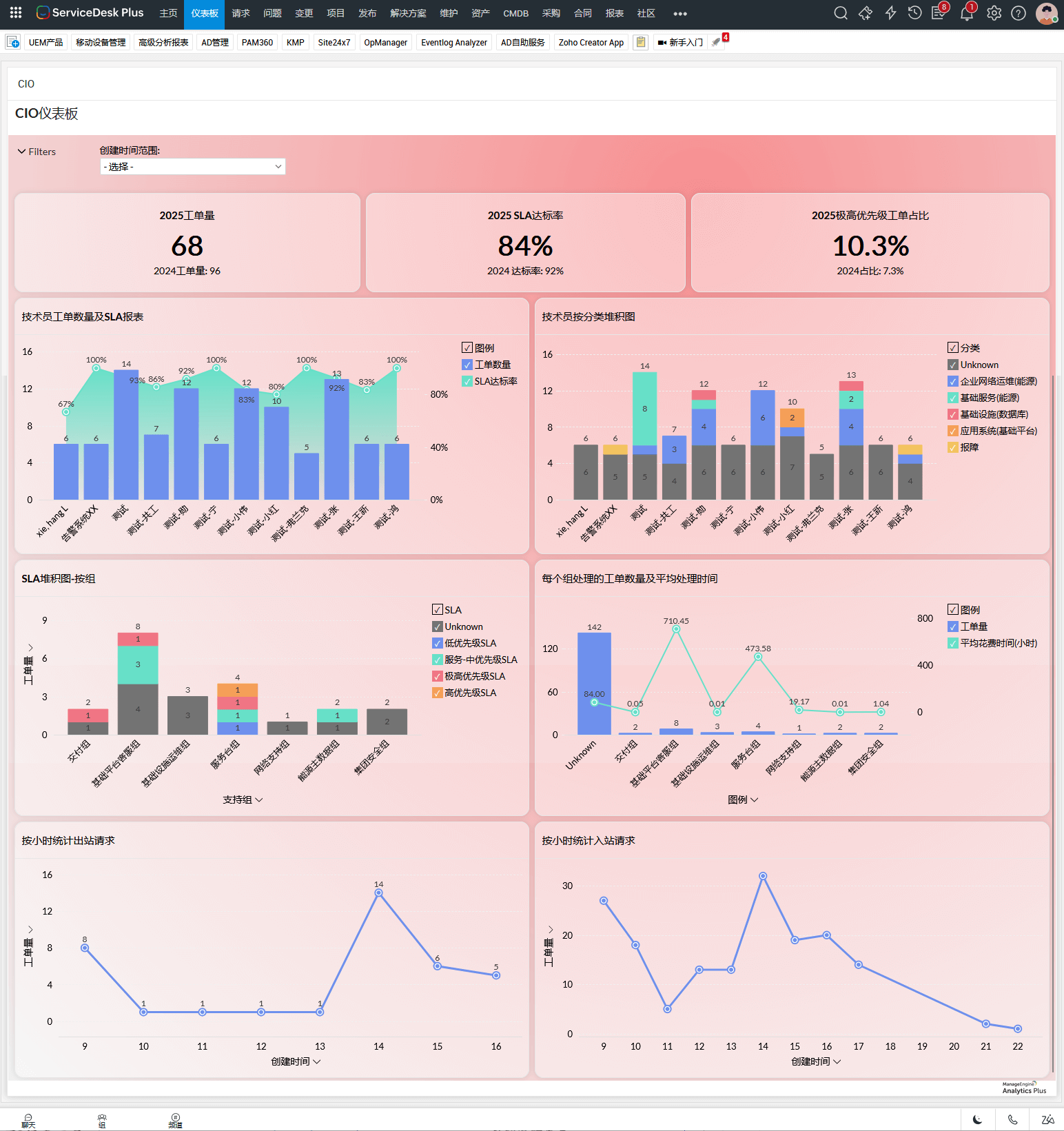
六、以 ServiceDesk Plus 为核心的韧性 ITSM 实践
当组织开始从“响应”走向“韧性”, ServiceDesk Plus 可以作为统一枢纽,将事件、问题、变更、资产与知识沉淀在同一平台中。
通过流程关联、自动化规则、报表分析与跨系统集成, IT 团队能够持续降低中断风险,而非反复处理相同问题。
FAQ:关于 IT 韧性与 ITSM 的常见问题
1. IT 韧性是否意味着更高成本?
恰恰相反。通过减少重复事件与失败变更,长期可显著降低运维成本。
2. 中小企业是否需要关注 IT 韧性?
规模越小,单次中断的业务冲击往往越大,越需要体系化管理。
3. 是否必须引入复杂工具才能实现?
关键在于流程与数据整合,而非工具数量。

立即体验更具韧性的 IT 服务管理
- 免费试用 ServiceDesk Plus(30 天全功能): 立即注册
- 下载本地部署版(5 技术员永久免费): 立即下载
- 预约 1 对 1 产品演示: 预约专家讲解