服务可观测性:让 IT 工单管理从“被动响应”走向主动治理



在许多企业中,IT 服务团队每天都在“解决问题”:工单不断进来,技术员不断处理,系统不断恢复,看似一切都在运转。然而,当你从更高的视角审视这些活动时,往往会发现一个耐人寻味的现象——团队非常忙,但组织对 IT 服务的“掌控感”却并不强。问题解决了,却不知道为什么会反复出现;工单关闭了,却无法判断服务质量是否真的在提升;SLA 达成了,却依旧频繁收到业务侧的抱怨。
这种矛盾的根源,并不在于技术能力不足,而在于服务本身“不可观测”。当 IT 服务只在问题发生后被动响应,组织就只能看到结果,而无法洞察过程;只能看到个体工单,而无法理解系统性趋势;只能靠经验判断风险,而无法用数据提前预警。久而久之,IT 团队会陷入一种被动循环:问题出现 → 紧急处理 → 暂时恢复 → 再次出现。
近年来,“可观测性(Observability)”这一概念在应用监控、云原生与 AIOps 领域被频繁提及,其核心并不是“看得见指标”,而是“能够理解系统的内在状态,并据此做出正确决策”。当这一思想被引入 IT 服务管理领域时,会带来一种根本性的转变:IT 工单不再只是响应载体,而是服务状态、流程健康度与组织协作质量的观测窗口。
本文将围绕“服务可观测性”这一视角,系统性拆解企业如何通过工单体系实现从被动响应到主动治理的跃迁。我们将讨论为什么传统工单管理难以支撑治理目标,服务可观测性需要哪些核心要素,以及如何借助 ManageEngine ServiceDesk Plus 构建一个可观测、可分析、可持续改进的 ITSM 平台。
一、为什么大多数 IT 工单管理体系“忙而不治”
从表面看,许多企业已经部署了 IT 工单管理系统, 也引入了基本的 ITSM 系统 流程。但在实际运行中,这些系统更多承担的是“事务处理”职能,而非“治理工具”。工单被创建、分派、解决、关闭,却很少被用于洞察服务模式、识别结构性问题或预测潜在风险。
这类体系通常存在三个共性问题:第一,数据是割裂的,只服务于单个工单;第二,流程是静态的,难以反映真实复杂度;第三,指标是滞后的,只能复盘而不能预警。结果就是,组织虽然“看得到工单”,却“看不懂服务”。
1)工单视角过窄:只关注事件,不理解系统行为
传统工单管理往往以“单次事件”为最小单元:一次报障、一次请求、一次变更。每个工单都被独立处理,成功与否的判断标准是“是否关闭”。但在真实环境中,服务质量是连续的、累积的结果,而非单点事件的简单叠加。忽略事件之间的关联性,就意味着无法识别重复模式、共因问题与系统性风险。
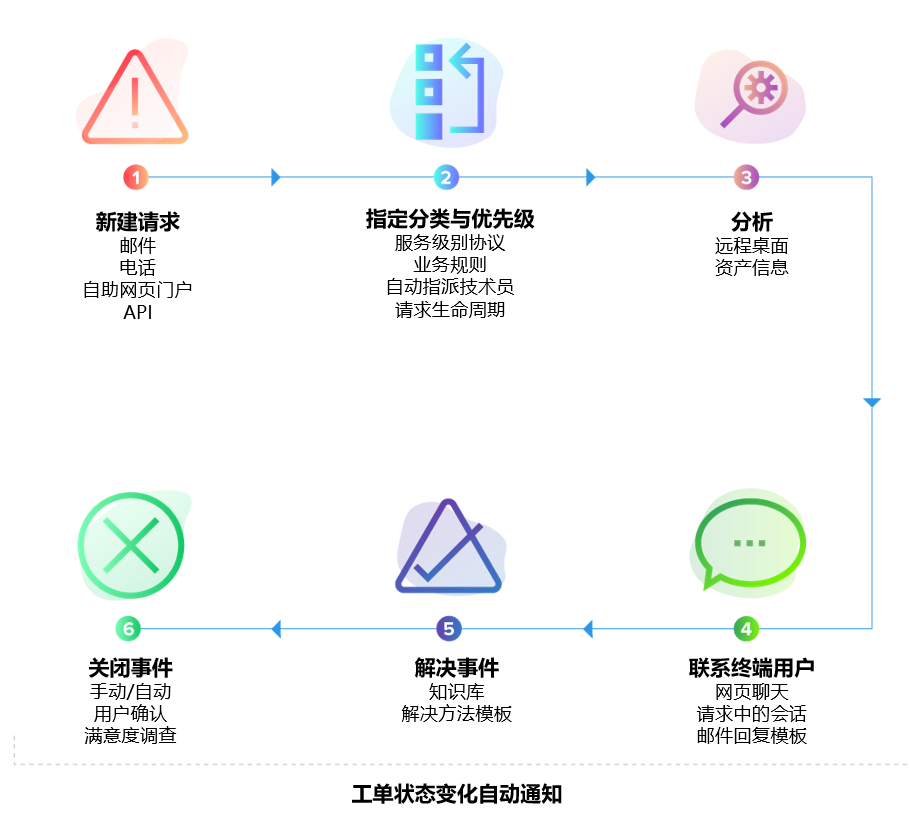
2)流程不可观测:协作黑箱削弱治理能力
当工单在多个团队之间流转时,如果缺乏清晰的状态、责任与时间维度记录,流程就会变成黑箱。管理者只能看到“当前在哪一步”,却无法判断“是否合理”“是否存在瓶颈”“是否需要干预”。久而久之,治理只能依赖人工经验,而非系统能力。
3)指标滞后:SLA 成了事后总结,而不是提前信号
在许多组织中,SLA 只是一个合规指标:月底看报表、季度做总结。真正的问题在于,SLA 数据并未被用来驱动实时决策。没有趋势分析、没有预测模型、没有与资源负载的联动,SLA 就只能告诉你“哪里已经失败”,而不能告诉你“哪里即将失败”。
二、什么是服务可观测性:从“看见工单”到“理解服务”
服务可观测性并不是简单地“加几个报表”,而是一种体系化能力。它关注的不是单个指标,而是通过多维数据还原服务运行的真实状态。在 IT 工单管理场景中,这意味着你不仅要知道“发生了什么”,还要知道“为什么发生”“会不会再次发生”“如果不干预会带来什么影响”。
一个具备服务可观测性的工单体系,通常需要同时具备三类能力:状态可观测、流程可观测与影响可观测。这三者相互补充,共同构成从操作层到管理层的认知闭环。
状态可观测:服务当前是否健康?
状态可观测关注的是“现在发生了什么”。通过实时工单状态、优先级分布、SLA 剩余时间、资源负载情况,团队可以快速判断服务是否处于稳定区间。这类能力解决的是“反应速度”问题,是避免小问题演变为大事故的第一道防线。
流程可观测:问题是如何被处理的?
流程可观测关注的是“事情是怎么发生的”。通过对转派路径、等待时间、审批节点与人工介入点的分析,组织可以识别流程瓶颈与协作摩擦。这为流程优化提供了数据基础,而不是凭感觉调整。
影响可观测:服务对业务意味着什么?
影响可观测关注的是“如果不解决会怎样”。它要求工单体系与业务系统、资产、用户群体建立关联,从而评估影响范围与风险等级。只有当 IT 服务与业务影响建立映射关系,治理决策才真正有意义。
三、构建可观测工单体系的核心支柱(前半)
将服务可观测性落地,并不意味着一次性重构所有系统。相反,它更像是一种能力叠加:在既有工单体系之上,引入新的数据维度、关联关系与分析视角。实践中,有三大支柱决定了可观测性的成熟度:统一数据模型、资产与配置关联、以及标准化流程事件。
把数据“连起来”,可观测性才会真正成立
仅仅采集更多数据,并不会自动带来可观测性。真正的关键在于“关联”:工单与资产是否有关联、事件与问题是否有关联、流程节点与时间消耗是否有关联、服务中断与业务影响是否有关联。没有关联,数据只是零散记录;有了关联,数据才会形成叙事能力。
在实践中,最容易被忽视但价值极高的一步,是将工单与配置项(CI)进行绑定。当事件、问题、变更都指向明确的资产或系统时,组织就可以回答一系列过去难以回答的问题:哪些系统最不稳定?哪些资产变更风险最高?哪些问题正在被“反复掩盖”?这些问题的答案,正是主动治理的起点。
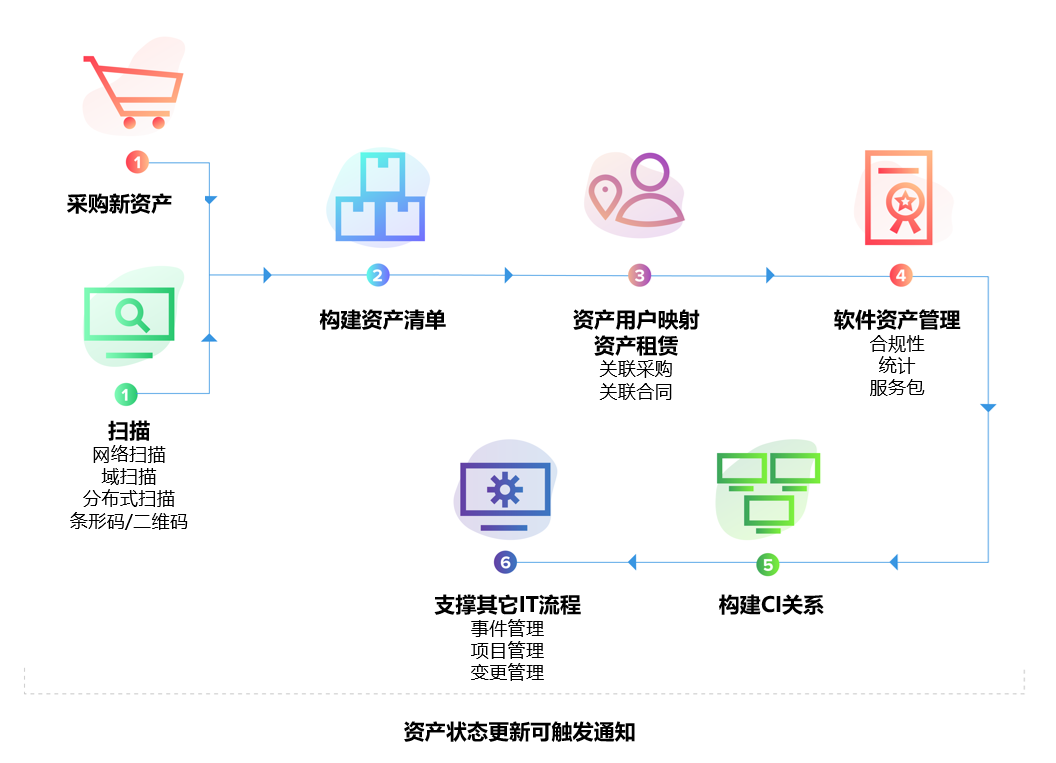
进一步来看,当问题管理与事件管理形成闭环,可观测性会从“当下状态”延伸到“未来趋势”。例如,通过分析某类事件在一段时间内的频率变化,系统可以提示潜在的结构性问题;通过将问题与变更记录关联,可以评估哪些修复措施真正起效,哪些只是短期缓解。
四、案例方法论:一家成长型企业如何建立服务可观测体系
为了更直观地理解服务可观测性如何落地,我们以一家快速扩张的制造与研发型企业为例。该企业在三年内员工规模翻倍,IT 系统数量迅速增长,原有工单体系逐渐暴露出响应慢、重复问题多、业务侧不信任等问题。
阶段一:先让服务“被看见”
该企业的第一步并不是重构所有流程,而是统一入口。所有 IT 相关请求被引导至统一服务门户,并通过表单强制采集关键字段。短短数周内,工单信息完整度显著提升,误派单与补信息次数明显下降。
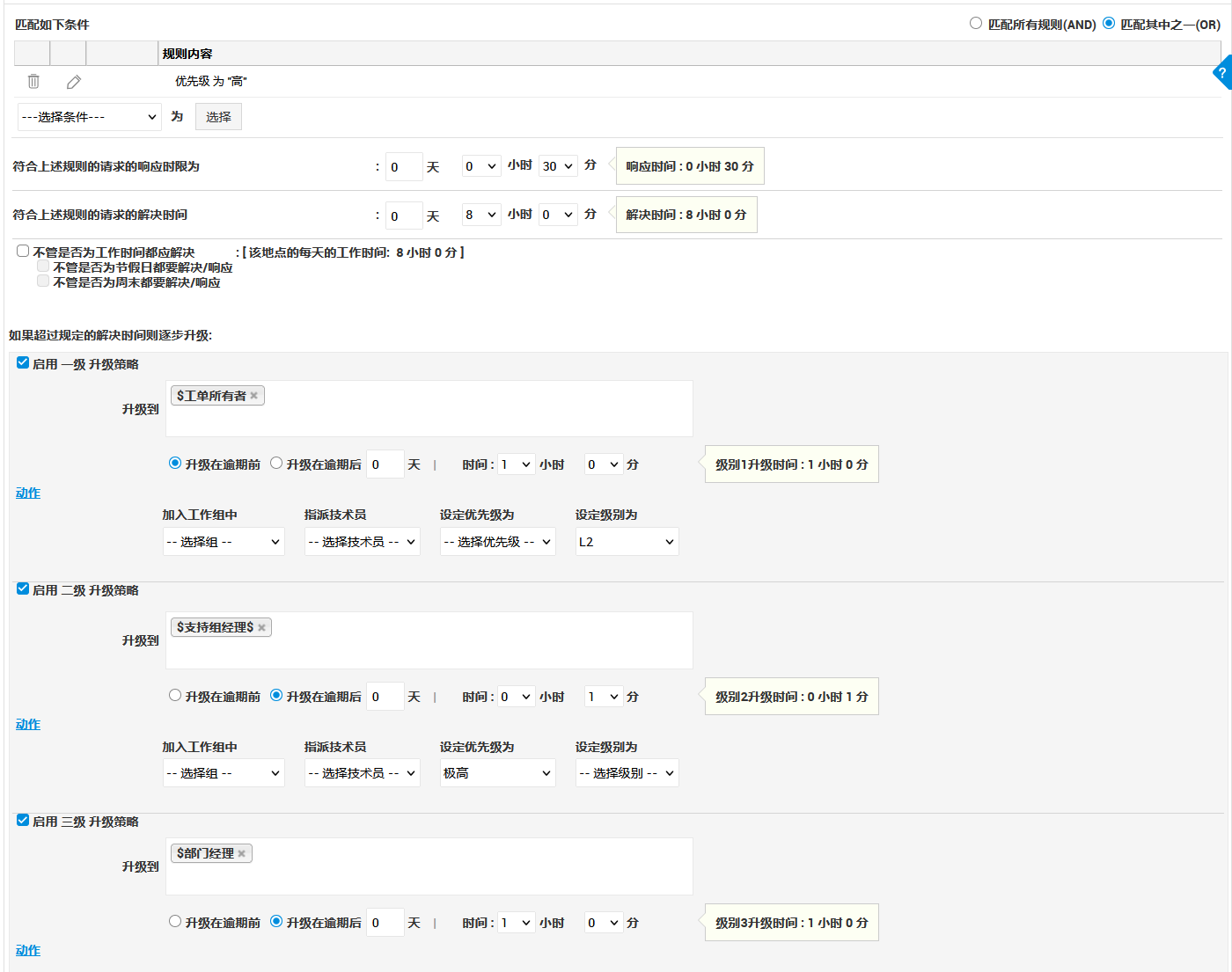
阶段二:用流程与 SLA 建立“预警机制”
在入口稳定后,团队引入分层流程与 SLA 规则。高优先级事件被设置为自动升级,系统会在即将超时时主动提醒相关负责人。与过去“事后追责”不同,管理者开始在问题演变前获得信号。
阶段三:用数据驱动持续改进
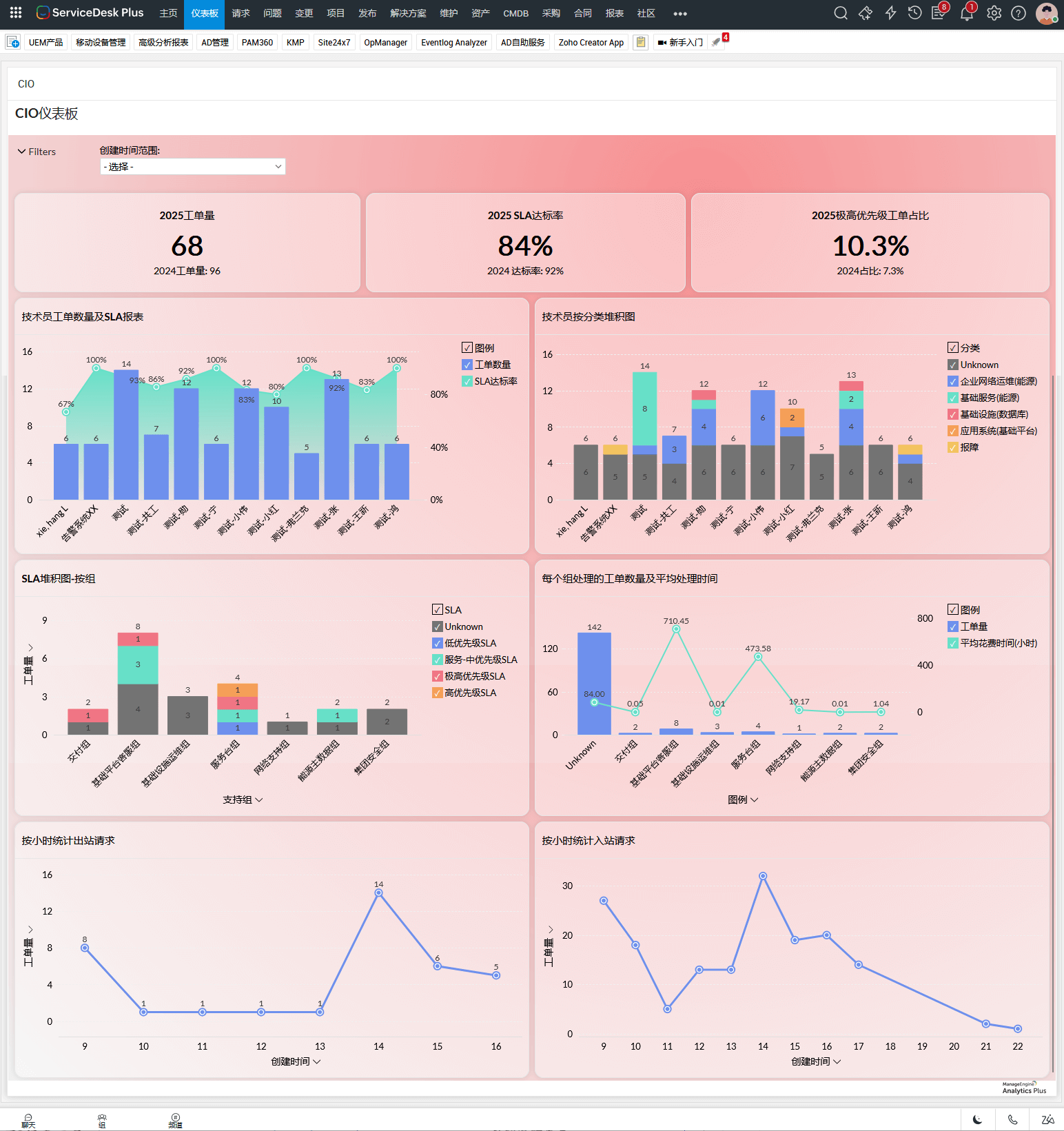
当基础数据积累到一定规模后,该企业开始定期分析问题趋势与流程瓶颈。部分重复事件被转化为标准服务请求,部分高风险系统被纳入重点监控清单。工单数量并未显著下降,但服务稳定性和业务满意度却持续提升。
五、从可观测到可治理:形成真正的服务闭环
可观测性的终点不是“看清楚”,而是“能改变”。当数据、流程与责任形成闭环,组织才能把洞察转化为行动。这通常体现在三个层面:策略调整、资源配置与流程优化。
例如,当数据表明某类事件持续占用大量资源,管理者可以选择通过自动化、知识库或服务目录进行分流;当某条流程长期成为瓶颈,可以通过简化审批或重新分配职责进行优化。治理不再依赖感觉,而是基于证据。
六、ServiceDesk Plus 如何支撑可观测 ITSM 的落地
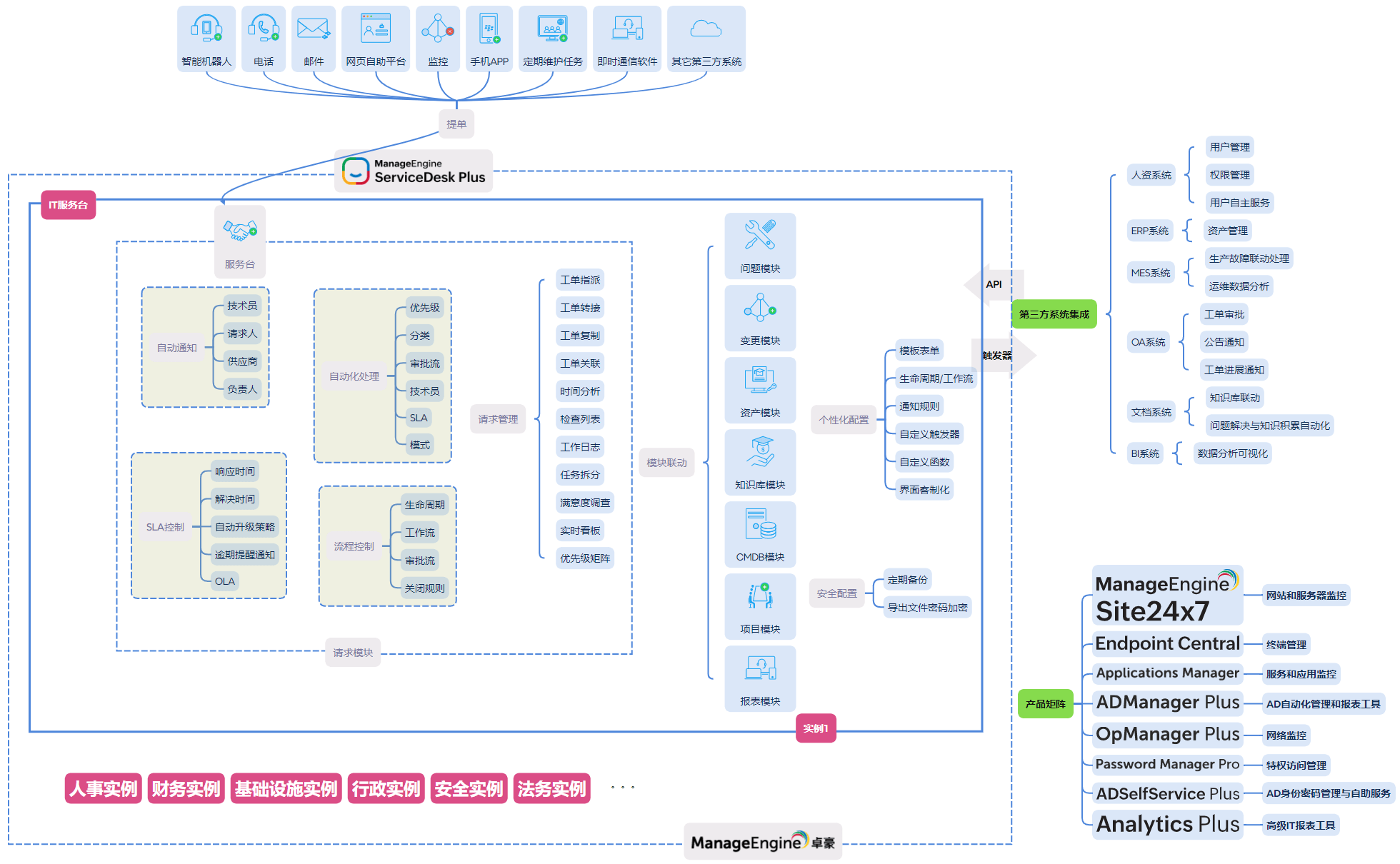
ServiceDesk Plus 通过将工单、资产、流程、自动化与报表整合在统一平台中,为服务可观测性提供了天然载体。企业无需额外搭建复杂的数据管道,即可在日常服务管理中逐步建立可观测能力。
从统一服务门户、ITIL 流程支持,到 SLA、仪表板、API 与低代码规则,ServiceDesk Plus 让组织可以根据自身成熟度逐步演进,而不是被迫一次性完成所有转型。
常见问题
Q1:服务可观测性是否只适合大型企业?
并非如此。可观测性的价值在于“提前发现问题”,越早建立,扩张成本越低。
Q2:需要引入额外监控系统才能实现吗?
不一定。很多可观测能力可以直接通过工单、流程与资产数据实现。
Q3:如何衡量可观测性是否成熟?
关键在于是否能提前预警、是否能用数据指导改进、是否能持续降低重复问题。

立即体验 ServiceDesk Plus,构建可观测、可治理、可持续演进的 IT 服务管理体系。
- 云版本试用:30 天全功能免费体验
- 本地部署:下载 ServiceDesk Plus(5 个技术员永久免费)
- 专家演示:预约 1 对 1 产品讲解