用“知识库增长模型”把 IT 服务台从救火变成自助与复用的增长飞轮



很多团队在部署 ITSM 系统 与 ITIL 流程 之后会发现一个非常现实的矛盾:工单更规范了、流程更清晰了,但服务台依然忙到喘不过气;高峰期依然爆仓;同一类问题依然反复出现;技术员仍然在重复回答同样的问题。根因通常不在“工单做得不够好”,而在“知识没有形成复用”。当知识无法沉淀、无法被检索、无法被自助使用,IT 服务台 就会天然变成“无限人力黑洞”——工单越多,越忙越乱;越乱越难沉淀;越难沉淀越依赖人,形成典型的恶性循环。
要打破这个循环,你需要的不是“再多写几篇知识库”,而是一套可持续的“知识库增长模型”:用运营的方法把知识当作服务能力来建设,让知识从“文档仓库”升级为“增长引擎”——既能提升终端用户自助解决率,也能显著降低重复工单与返工,还能把技术员经验转化为组织资产,让服务质量越来越稳定。平台层面,本文将结合 ServiceDesk Plus 的典型落地方式,系统讲清楚:如何定义知识闭环、如何用数据驱动增长、如何把知识嵌入工单与门户、以及如何在 90 天内做出可见成果。
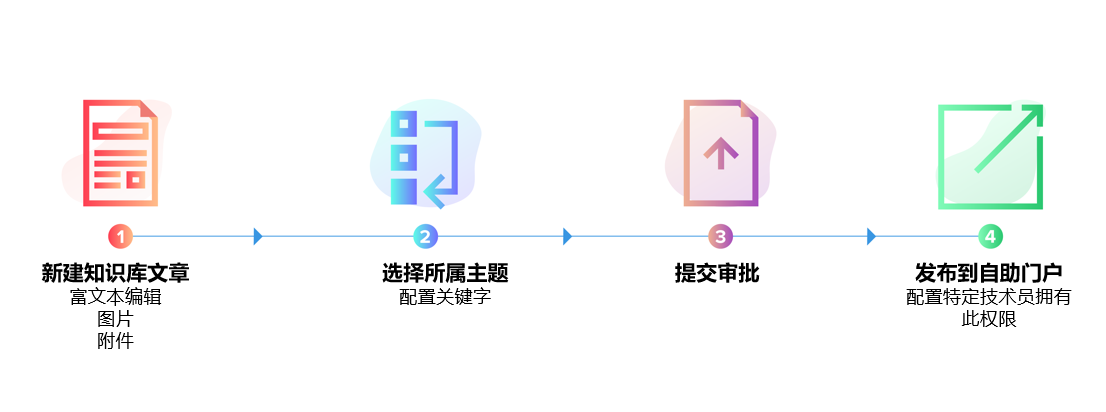
一、为什么知识库总是“写了没人看”:三类常见失败模式
知识库难,不是难在“写”,而是难在“用”。很多组织的知识库建设走着走着就变成了“写作 KPI”:要求每周产出几篇文章、要求每月更新一次、要求每个组提交数量。但数量并不等于复用,最终表现通常是:知识库越来越大,工单量却不下降;终端用户也很少主动搜索;技术员仍然依赖口口相传或个人笔记。归根结底,是知识库没有形成可增长的闭环。
失败模式 1:知识库与工单脱钩,写什么靠“想象”
如果知识库不以工单数据为输入,文章主题往往来自个人经验或临时想法:写得可能很专业,但未必解决高频问题。更关键的是,写作优先级无法用数据排序,导致“真正该写的没写、写了的没人用”。知识库增长模型强调:以高频工单、重复工单、长尾工单、SLA 超时工单作为写作源头,写“最能减少工单”的知识,而不是写“最像文档”的知识。
失败模式 2:知识结构像“文件夹”,用户找不到路径
很多知识库按产品/系统/部门建文件夹,这对 IT 内部可能直观,但对员工并不友好。员工的思维是“我现在遇到什么问题”“我想完成什么事情”,而不是“这个问题属于哪个系统模块”。如果分类与标签体系不以用户目标组织,搜索体验会非常差,用户自然不会使用。知识库增长模型的核心之一,就是把知识组织成“面向任务的路径”,让用户通过关键词、常见问题入口、服务目录页等方式快速到达答案。
失败模式 3:知识没有“生命周期”,更新成本越来越高
知识不是一次性产物。系统更新、权限策略变化、客户端版本变化都会让旧知识失效。若没有生命周期机制(有效期、版本、审阅、废弃),知识库就会不断积累“过期答案”,造成更大的体验伤害:用户照着做仍然失败,反而更焦虑,工单量上升。增长模型强调:知识必须有维护节奏,并且维护优先级也必须由数据驱动(哪些文章访问多、反馈差、相关工单仍高发,优先修)。
二、知识库增长模型:用“输入—生产—分发—反馈—优化”形成飞轮
把知识库做成增长引擎,需要像做产品一样做运营:明确输入来源、明确生产标准、明确分发渠道、明确反馈机制,并用数据驱动持续优化。你可以把知识库增长模型理解为一个飞轮:每多一篇“有效知识”,就能降低一部分重复工单;工单减少后,技术员释放更多时间去产出更高价值知识;知识质量提升又进一步提升自助解决率,形成正向循环。
1)输入:从工单与服务目录提炼“最值得写”的主题
优先级排序建议用四个信号:工单量(频次)、重复率(复发)、处理时长(复杂度/成本)、满意度(体验痛点)。把这四个信号结合起来,你就能得到一个非常清晰的“知识投资清单”:写哪几篇最能减工单、最能缩短处理时间、最能提升满意度。尤其要关注“高频 + 低复杂度”的问题,它们往往是自助化的最佳对象:只要提供清晰步骤与常见错误排查,用户就能自己解决。
2)生产:把文章写成“可执行步骤”,而不是“背景说明”
对终端用户而言,知识的价值不在于原理,而在于“我该怎么做”。建议每篇文章都采用一致的可执行结构:适用场景(我遇到什么)、前置条件(我需要什么权限/软件/网络)、步骤(按顺序操作)、验证方式(怎么确认成功)、失败排查(常见报错与解决)、升级路径(仍失败怎么办)。当文章结构稳定,用户阅读成本会大幅降低,自助成功率自然上升。
3)分发:把知识嵌入“用户正在做的事情”里
知识库最常见的问题是“放在那”,用户不会主动去找。更高效的分发是“嵌入式”:在提交服务请求时推荐相关知识;在工单创建后自动推送最可能的自助文章;在自助门户突出常见问题;在通知邮件/消息中附带步骤链接。核心理念是:把知识放到用户最需要的时候,而不是让用户去“记得去找知识库”。
4)反馈:用数据告诉你“哪些知识真的有用”
每篇文章都应有反馈机制:是否解决问题、哪里不清楚、是否过期、需要补充什么。反馈不仅用于改文章,更用于改“知识投资方向”:如果某类知识访问多但仍引发工单,说明文章不够可执行或场景覆盖不足;如果某类知识极少访问,可能是分类/标签/分发路径有问题。把反馈做成指标,你才能持续迭代而不是靠感觉维护。
三、把知识嵌入服务台:从“搜索”走向“自动推荐与复用”
知识复用能力的分水岭在于:是否仅依赖“人工搜索”。人工搜索的成本很高:用户不愿搜、技术员也未必有时间搜。更可持续的方法是:在关键流程节点做知识触发,让“找知识”变成“知识自己出现”。下面是三种最能立刻降低工单量的嵌入方式,你可以优先落地。
方式 1:在请求模板里做“提交前拦截”
当用户选择某个服务项(例如 VPN、邮箱、打印机、会议室设备)时,系统可以在提交前展示最相关的 2–3 篇知识文章,并让用户先尝试自助。对高频低复杂度问题,这种“提交前拦截”能显著减少工单量,同时不会伤害体验——因为用户更快得到答案。
方式 2:在工单创建后自动推送“下一步动作”
如果工单已经创建,也仍然可以通过自动回复推送自助步骤:让用户在等待响应期间先完成基础排查(如重启、网络检测、权限确认、版本检查)。这既能提升有效响应质量,也能让后续处理更快(信息更全、问题更清晰)。
方式 3:技术员侧“解决方案复用”与“知识一键沉淀”
技术员每天解决的问题里,有大量可复用步骤。若每次都靠个人记忆,组织永远无法积累。建议把“工单解决方案”与“知识文章”打通:当技术员写了解决步骤后,可以快速沉淀为知识草稿,进入审阅发布流程。这样知识生产不会变成额外负担,而是自然融入日常工作流。
四、指标体系:用 6 个指标把“知识是否在增长”说清楚
知识库最怕“写得很努力但效果不明”。你需要一套能直接反映价值的指标体系,让团队知道:哪些知识在帮你减工单、哪些知识在提升体验、哪些知识该更新、哪些服务包需要补齐。下面这 6 个指标几乎适用于所有组织,且能在 90 天内看出趋势。
指标 1:自助解决率(Self-service Resolution Rate)
衡量通过门户/知识文章直接解决问题的比例。它是增长飞轮的核心结果指标。建议以服务包为维度观察:哪些服务自助率提升最快,说明知识与路径有效;哪些长期上不去,说明要么太复杂不适合自助,要么知识结构不对。
指标 2:重复工单下降率(Repeat Ticket Reduction)
衡量同类问题在知识上线前后的工单量变化。这个指标最能向管理层证明价值:知识不是“写文章”,而是在减少支持成本、释放人力。
指标 3:知识触达率(Exposure)与点击率(CTR)
触达率高但点击率低,通常说明标题与摘要不匹配用户语言;触达率低则说明分发路径不对(用户根本看不到)。这组指标帮助你优化“分发”,而不仅是“内容”。
指标 4:文章有效性评分(Was this helpful?)
用户反馈能直接指出文章哪里不清晰、是否过期、步骤是否缺失。有效性评分低且访问高的文章,是最优先更新对象,因为它们正在制造体验损伤与额外工单。
指标 5:知识新鲜度(Freshness)与过期率(Staleness)
用审阅周期、更新频率衡量知识是否跟得上系统变化。过期知识比没有知识更糟糕:它会误导用户,造成反复失败与更强烈的负面体验。
指标 6:知识生产效率(从解决到沉淀的转化率)
衡量“已解决工单 → 知识草稿/文章”的转化能力。转化率越高,说明知识生产已被流程化,飞轮才可能长期转动;反之,知识永远依赖少数写作积极的人,无法规模化。
五、落地路线图:90 天做出“可见收益”,6–12 个月做成体系
知识库增长模型的正确落地方式,是“先做出收益,再做成体系”。下面这条路线能让你在 90 天内看到重复工单下降与自助率提升,同时为后续规模化打下结构基础。
第 1–30 天:选高频服务包 + 建最小知识闭环
从工单数据中挑选 10–20 个高频服务包(优先“高频+低复杂度”),为每个服务包产出 1–2 篇高可执行文章;同步建立基础结构:统一标题规范、步骤模板、常见错误排查模板;在自助门户与请求模板中设置最基础的知识推荐入口。此阶段目标:让知识可被找到、可被执行、可被反馈。
第 31–60 天:把推荐嵌入流程 + 建立更新机制
把知识推荐嵌入工单创建与自动通知:提交前拦截、创建后自动推送、关键节点提示;建立文章生命周期:审阅人、审阅周期、过期处理规则;上线反馈机制并每周做一次“高访问低评分文章”的专项修订。此阶段目标:让知识成为流程的一部分,而不是附属页面。
第 61–90 天:指标仪表板 + 复用机制 + 复盘节奏
上线 6 个核心指标仪表板;固化“解决方案一键沉淀”机制,让知识生产自然嵌入技术员日常;每两周做一次知识运营复盘:自助率、重复工单下降率、Top 访问文章、Top 负面反馈文章、待补齐服务包清单。此阶段目标:让知识增长从“活动”变成“节奏”,并能持续证明价值。
六、平台承接:ServiceDesk Plus 如何支撑知识复用与自助增长
要让知识库增长模型真正跑起来,平台必须同时支持“生产、分发、反馈、治理”。生产端需要知识草稿、审阅发布与版本管理;分发端需要门户入口、请求模板嵌入与通知推送;反馈端需要可量化的有效性评分与访问数据;治理端需要生命周期与审阅机制,避免过期知识伤害体验。以 ServiceDesk Plus 为例,它能把知识管理与服务台流程紧密联动,让知识不再是独立文档库,而是服务交付能力的一部分:减少重复工单、提升自助解决率、降低长尾压力,让服务台从“救火模式”逐步转向“复用增长模式”。
当知识库具备增长模型,它就不再是“写了放着”的文档仓库,而会成为服务台的增长引擎:减少重复工单、提升自助解决率、稳定交付质量、沉淀组织经验。你可以从 10–20 个高频服务包起步,用 90 天跑出收益,再逐步把知识生产、分发、反馈与治理固化为长期节奏,让服务台从“救火”走向“复用增长”。
- 更喜欢云版本?注册试用:点击注册免费试用 ServiceDesk Plus(30 天全功能);
- 希望本地部署?下载地址:下载 ServiceDesk Plus 本地版(5 个技术员永久免费);
- 需要定制化演示?立即预约 1 对 1 方案产品讲解。

常见问题
1)知识库要写多少篇才会有效果?
关键不在数量,而在覆盖高频服务包与可执行结构。通常 20–40 篇高质量文章就能对重复工单产生明显影响,尤其是高频低复杂度问题。
2)用户不爱看知识库怎么办?
不要指望用户主动找。要做“嵌入式分发”:提交前拦截、工单创建后推送、门户常见问题入口,并用标题与步骤模板降低阅读成本。
3)如何避免知识过期误导用户?
建立生命周期:审阅周期、版本与废弃机制。优先更新“高访问 + 低评分”的文章,因为它们最可能制造体验损伤与额外工单。
4)技术员没时间写知识怎么办?
把“解决 → 沉淀”流程化:从工单解决方案一键生成草稿,审阅发布;先从高频问题做小闭环,工单下降后自然释放时间。
5)怎么证明知识库真的在创造价值?
用 6 个指标:自助解决率、重复工单下降率、触达/点击、文章有效性评分、新鲜度与转化率。指标能清晰指向“哪里有效、哪里需要改”。