成本可视化与价值交付:用 IT 工单数据打造可度量的 ITSM 治理体系



许多企业已经上线了 IT 工单系统 或 ITSM 系统, 也在考虑把 ServiceDesk Plus 这样的服务管理平台当作“统一入口”来沉淀流程、资产与知识。 但当业务与财务开始追问:“今年 IT 投入到底换来了什么?哪些服务最耗成本?哪些问题反复发生、却一直没有根治?为什么扩张后 IT 团队越来越忙,用户体验反而变差?”——很多组织会发现:我们有系统、有工单、有流程,却缺少一套能把“工作量”翻译成“成本与价值”的方法。
这篇文章想解决的不是“如何把工单关得更快”这种局部问题,而是更底层的治理命题:当 IT 变成企业运营的基础设施之后,IT 服务管理应该如何像经营一条产品线一样被经营?如何让每一类服务、每一次请求、每一项变更都能被度量、被追踪、被改进,并最终在预算与价值之间形成闭环?答案的关键不只在于工具,而在于“数据结构 + 运营方法论 + 可落地的治理机制”三者的组合。
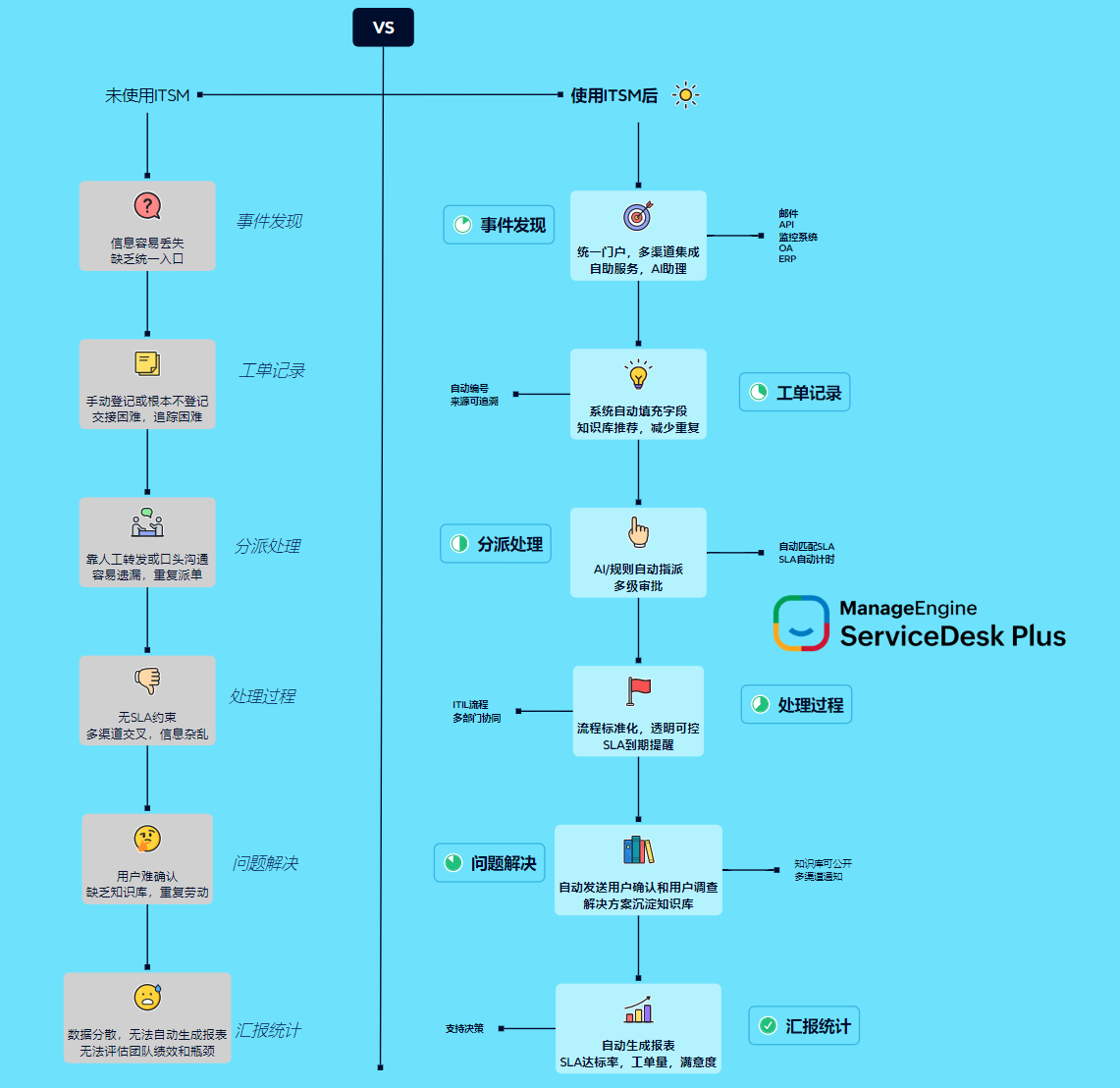
你可以把本文理解为一份“ITSM 经营化”的路线图:我们将从成本可视化的角度出发,拆解工单数据该怎么采、怎么连、怎么用;再把这些数据映射到可解释的指标体系(成本、效率、风险、体验),最后给出一套能在大多数企业落地的执行框架:从第一天就能做的“低门槛改造”,到三个月内能见效的“运营闭环”,再到一年周期可持续进化的“服务产品化”。
一、为什么 IT 工单越来越多,却越来越难解释“价值”
工单增多并不一定意味着 IT 做得更差。很多时候,它反而说明企业对 IT 的依赖更深、服务范围更广、业务节奏更快。问题出在:当工单量上升时,大多数团队仍然用“响应速度”“SLA 达标率”来对外沟通,而业务与财务真正关心的是另一组问题:这些工单背后代表什么样的成本结构?哪些是可预防的?哪些是重复性的?哪些需求本应被“服务化/标准化”,却因为没有产品化能力而变成了无尽的定制支持?
传统的工单视角强调“处理”:接单、分类、指派、解决、关闭。这套逻辑天然偏向过程合规,却不天然产生经营指标。你可以很认真地把每张工单都写得很完整,甚至严格执行审批与变更流程,但仍然回答不了:“今年 IT 成本上升 20% 是因为系统更复杂、业务更依赖,还是因为重复性问题没有被根治,导致人力被持续消耗?”
1)“忙”不等于“有效”:工单的价值需要被翻译
让人头疼的往往不是工单本身,而是工单背后的“不可解释性”。同样是 1,000 张工单:如果其中 60% 是标准请求(账号、权限、设备、软件安装),并且大多数可自助或自动履行,那代表服务成熟度在提升;但如果其中 60% 是重复故障(网络波动、应用不稳定、配置漂移、权限混乱),并且每次都要靠资深工程师救火,那代表服务系统存在结构性漏洞。两者的“忙”程度可能相当,但对组织的意义完全不同。
2)缺少“成本语言”的 ITSM,会失去预算谈判能力
当财务问“能不能降本”,IT 回答“我们已经很努力了”;当业务问“为什么这么慢”,IT 回答“我们人手不够”。这类对话之所以陷入僵局,本质是双方用的语言不同:财务在谈成本结构与投入产出,业务在谈体验与连续性,IT 在谈工作量与技术复杂度。要把这三种语言统一起来,需要一个共同媒介——工单数据,但前提是它必须被结构化、可关联、可度量。
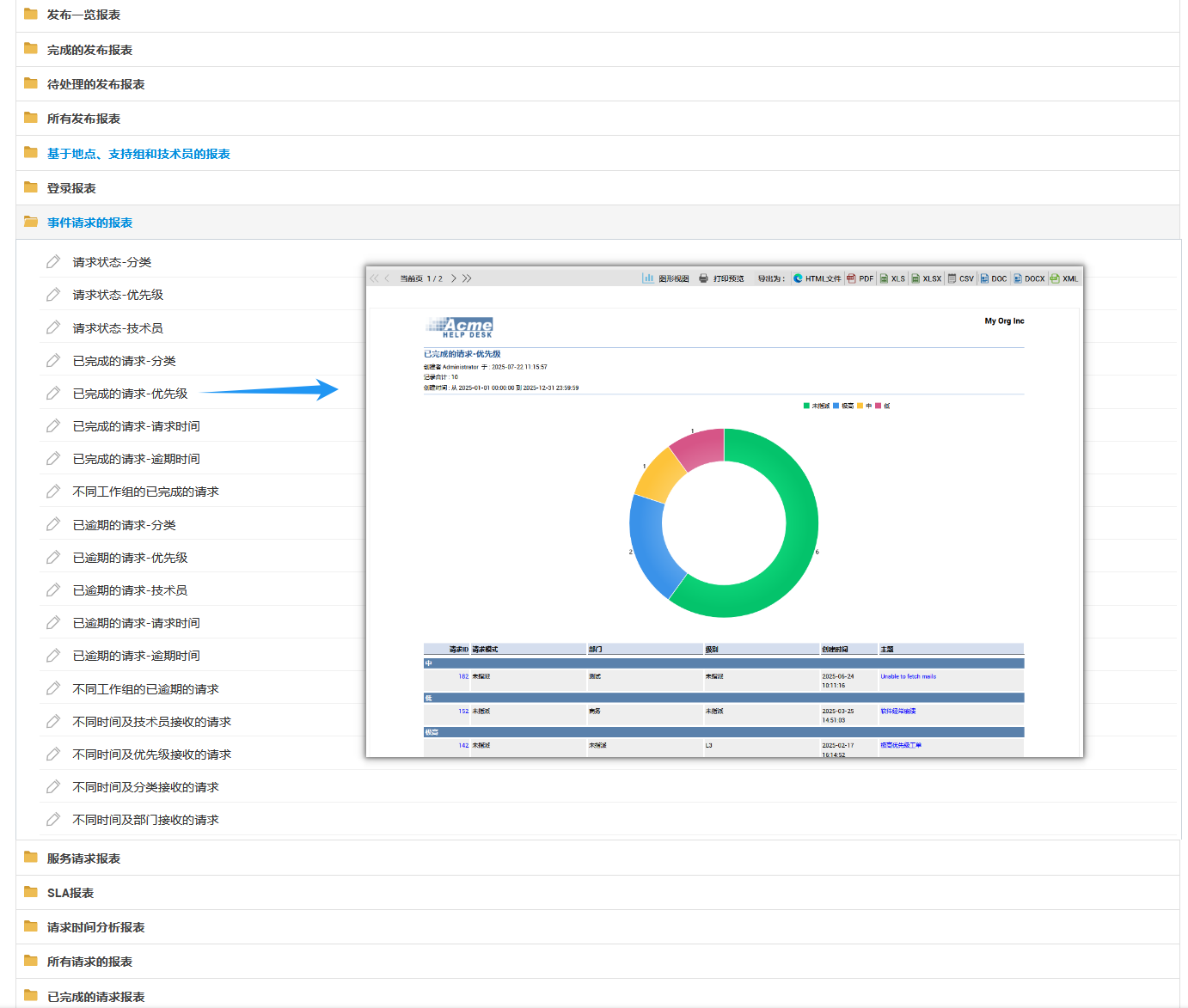
许多团队已经有报表,但报表经常停留在“数量统计”:每周多少张、各分类占比、平均处理时长。它们对内部管理有帮助,却难以驱动经营决策。真正能支撑治理的报表,需要把“工单—资产—服务—团队—成本中心—风险等级—业务影响”连成一张网,帮助你回答:投入在哪里、浪费在哪里、风险在哪里、机会在哪里。
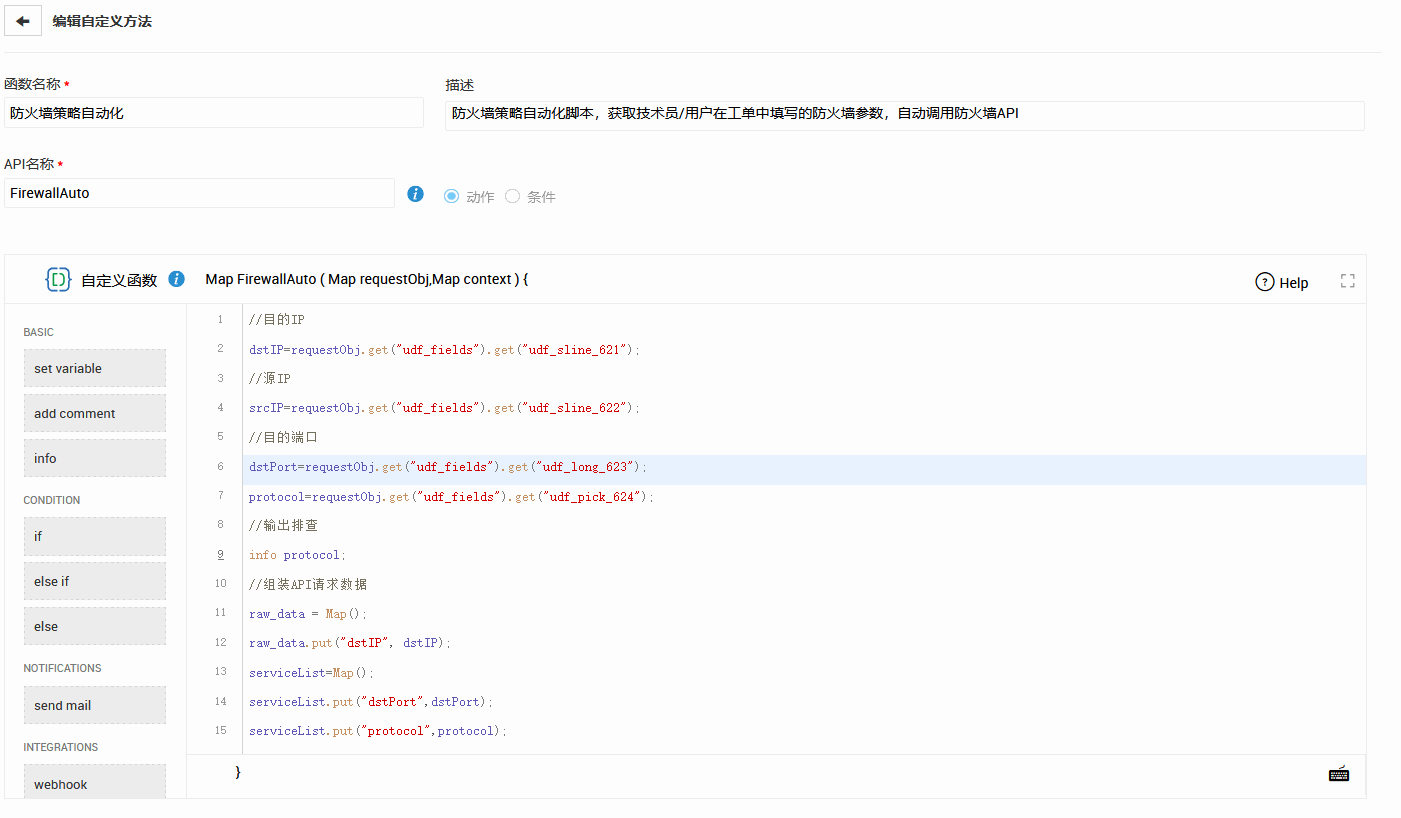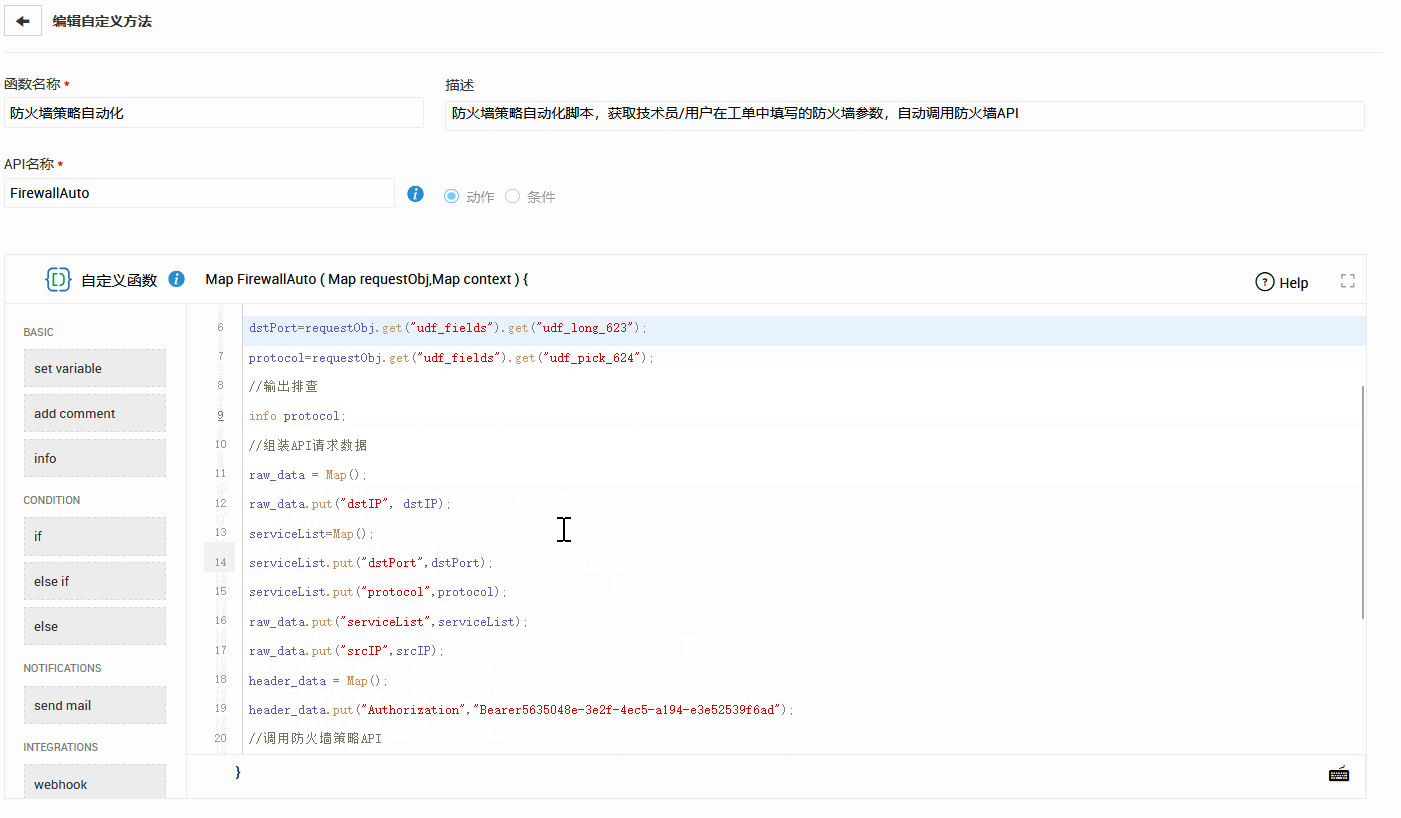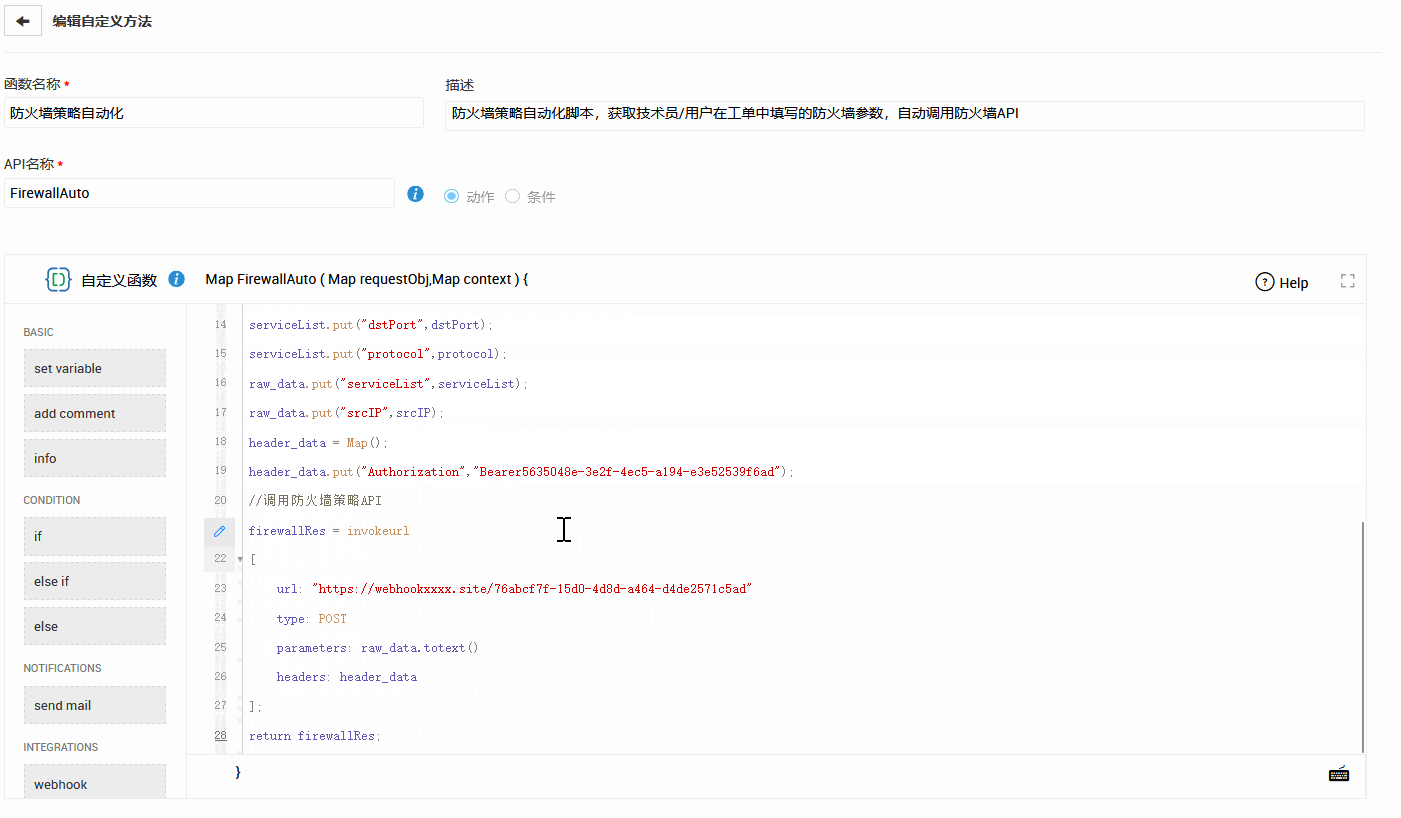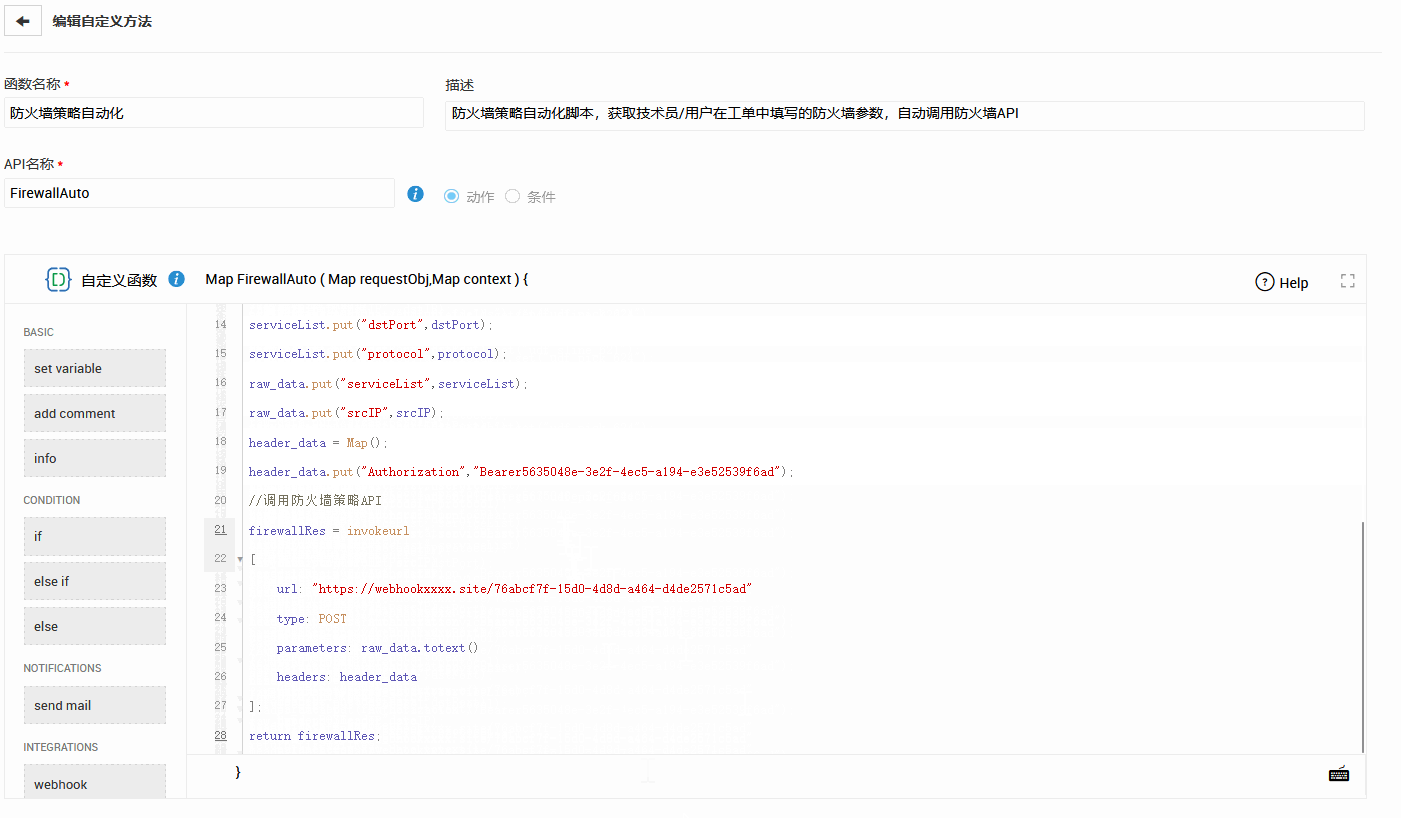
二、建立成本可视化:先把“工单数据”做成能算账的结构
成本可视化并不等同于“给每张工单标一个金额”。真正可落地的路径通常更朴素:先让工单具备可计算的字段与关联关系,再逐步把时间、人力、资产与风险映射到可解释的成本模型中。这里最关键的不是复杂算法,而是你是否能在不增加太多录入负担的情况下,让数据自然而然地沉淀出来。
1)先统一口径:服务目录、请求类型、优先级与业务影响
想把工单“算账”,第一步是统一口径。最常见的失败案例是:分类体系太多、层级太深、命名不一致,导致同一类事情在系统里以不同方式被记录。你看似有很多数据,实际却无法对比。一个务实的做法是先用“服务目录/请求类型”作为主轴,把高频请求收敛成少量可理解的服务条目;同时把优先级与业务影响拆开:优先级反映紧急程度,业务影响反映影响范围(人数、门店、收入、关键流程),两者共同决定资源调度。
当入口统一之后,成本可视化会变得简单得多:你至少能清晰知道“哪些服务最常被请求”“哪些服务最耗时”“哪些服务的 SLA 最容易失守”。这些并不是成本本身,但它们是成本的影子:高频 × 高耗时往往对应高人力成本;高影响 × 高超时往往对应高业务成本与高风险成本。
2)把工单与资产、系统、地点关联起来:成本才有“归属”
同样一类故障,如果发生在关键系统、核心门店或高价值客户场景中,其业务代价完全不同。因此,成本可视化的第二步是“归属”:这张工单属于哪个资产/系统(配置项 CI),发生在哪个地点/部门,影响了哪些用户。只有当工单有归属,你才能把它映射到成本中心、责任团队与治理对象上。
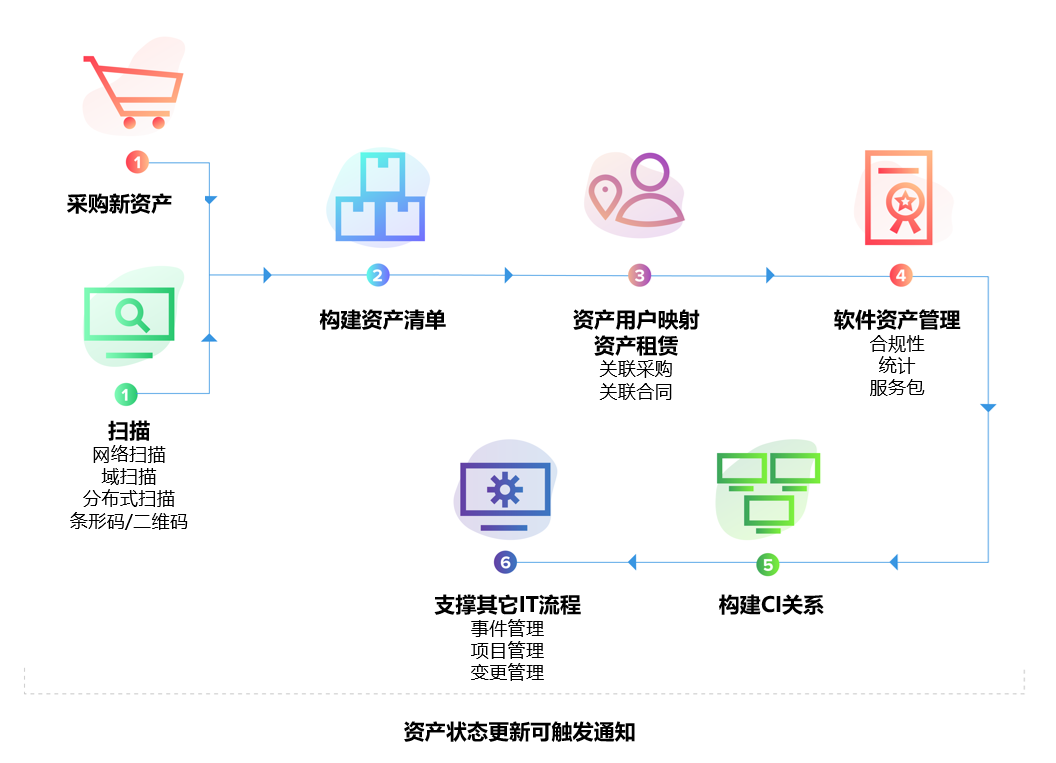
关联的价值不仅是统计。它还能直接改变你的改进策略:如果某类故障高度集中在少数资产上,那更像是“资产治理问题”(老旧、配置漂移、补丁滞后);如果故障分散但集中在某类变更后,那更像是“变更治理问题”;如果故障集中在某些地点与班次,那可能是“网络或供应链问题”。这些判断如果没有关联数据,很难站得住脚。
3)用“时间”做成本锚点:工时、等待、返工与升级链路
对大多数组织来说,人力是 IT 成本的最大项。要把工单转换成成本语言,最朴素的锚点就是时间:处理工时(真正投入的时间)、等待时间(审批、外部依赖、用户反馈)、返工时间(重复沟通与补信息)、升级次数(跨团队协作成本)。当你能把这些时间结构化记录下来,就拥有了可解释的“成本分解”。
特别要关注“等待时间”,它往往是体验差与成本高的共同根源。等待来自哪里?来自审批过多、信息不全、跨部门协作不顺、责任边界不清。你会发现:很多看似是“人不够”的问题,最终都指向流程与数据结构不合理。把等待时间做成指标,你才能把改进从“加人”转向“改机制”。
三、从成本到价值:把 ITSM 指标体系升级为“经营仪表盘”
成本可视化的目的不是“追责”,而是“经营”。经营意味着你不仅能看到花了多少钱,还能看到这些钱换来了什么:服务稳定性提升了多少?用户体验改善了多少?风险降低了多少?交付速度提升了多少?如果 ITSM 的指标只停留在工单层面,就很难把价值说清楚。你需要把指标体系升级到“服务层面”,用更接近业务的方式呈现 IT 的贡献。
1)四类指标,构成“服务经营视图”:成本、效率、风险、体验
一个可落地的服务经营仪表盘,通常围绕四类指标构建: 成本(工时、外包费用、许可证/资源消耗、重复问题成本)、效率(SLA、首次解决率、自动化履行率、平均恢复时间)、风险(高影响事件数量、变更失败率、合规偏差、关键资产健康度)、体验(满意度、NPS、响应透明度、重复沟通次数)。 这四类指标之间不是并列关系,而是因果链:自动化提升→效率提升→重复问题下降→成本下降;变更治理加强→风险下降→重大事件减少→体验提升。
2)用“服务产品化”把价值沉淀下来:标准服务、可复用流程与自助能力
经营的核心,是把一次性劳动变成可复用能力。ITSM 最容易被忽视的一点是:它不仅是流程平台,还是“服务产品化”的载体。把高频请求做成标准服务目录,把履行步骤固化成可复用流程,把常见问题沉淀成知识与自助,把跨系统的动作用规则与集成自动执行——这会让同样的人力,支撑更大的业务规模。你会看到一种可持续的增长曲线:业务规模增长,但 IT 人力不必同比增长。
这里有个非常实用的判断标准:一项服务如果连续三个月都在 Top10 请求中出现,并且平均处理工时偏高,那它就不应该继续以“人工处理工单”的方式存在,而应该被产品化:要么自助化(让用户能自己完成)、要么自动化(让系统自己完成)、要么标准化(让履行步骤更短、更一致)。当你不断把“最贵的那部分工作”产品化,成本才会真正下降,体验才会真正提升。
3)用“复盘机制”把价值持续放大:事件复盘、问题根治、变更改进
很多组织做复盘,但复盘常常变成会议纪要。要让复盘变成经营动作,必须让它与数据闭环:复盘的输入来自工单与监控数据,输出变成问题记录、变更策略、知识库更新与自动化改造;并且这些输出必须能在后续的指标上体现效果。否则复盘就是“感动自己”。当你把复盘与问题管理、变更管理、知识管理串起来,ITSM 才会从“处理系统”进化成“改进系统”。
四、落地方法论:用“90 天治理闭环”把体系跑起来
讲方法论很容易,但你真正需要的是:明天就能做什么、一个月内能看到什么、三个月能形成怎样的闭环。下面给出一个在多数组织都可执行的“90 天治理闭环”——它不依赖大规模重构,也不要求你一开始就把所有流程做完美,而是先让数据跑起来、让指标站得住、让改进能落地。
第 1–30 天:建立基础口径与数据完整性(先能“看清”)
这一阶段的目标不是改流程,而是改数据结构:统一服务目录与请求类型,明确优先级与业务影响的定义,强制关键字段(服务、地点/部门、影响范围、相关系统/资产)被采集,并让“时间结构”可被度量(处理、等待、返工、升级)。你会很快发现:数据完整性提升后,很多沟通成本会自然下降,因为工单本身已经能承载上下文。
第 31–60 天:做第一版经营仪表盘(先能“讲清”)
用你已经结构化的数据,做一个最小可用的经营仪表盘:Top 服务成本(按工时估算)、Top 重复问题、Top 等待时间来源、SLA 风险点、高影响事件趋势、自动化履行率。注意:不要一开始追求大而全,关键是让每个指标都有可解释的定义,并能用于决策。比如“等待时间 Top3”一旦可见,就能立刻推动审批简化或责任重构,这类改进往往比“加人”更有效。
第 61–90 天:用三类动作闭环(先能“改动”)
第三阶段只做三类动作:产品化(把 Top 高频服务做成标准目录与自助/自动履行)、根治(把 Top 重复问题转为问题记录并推动结构性修复)、治理(对高风险变更与关键资产引入更严格的审批与回滚策略)。三类动作分别对应体验、成本与风险。你会在 90 天左右看到趋势改变:重复问题下降、等待时间缩短、满意度提升,最重要的是——你终于能用数据讲清楚:IT 的投入正在如何换取价值。
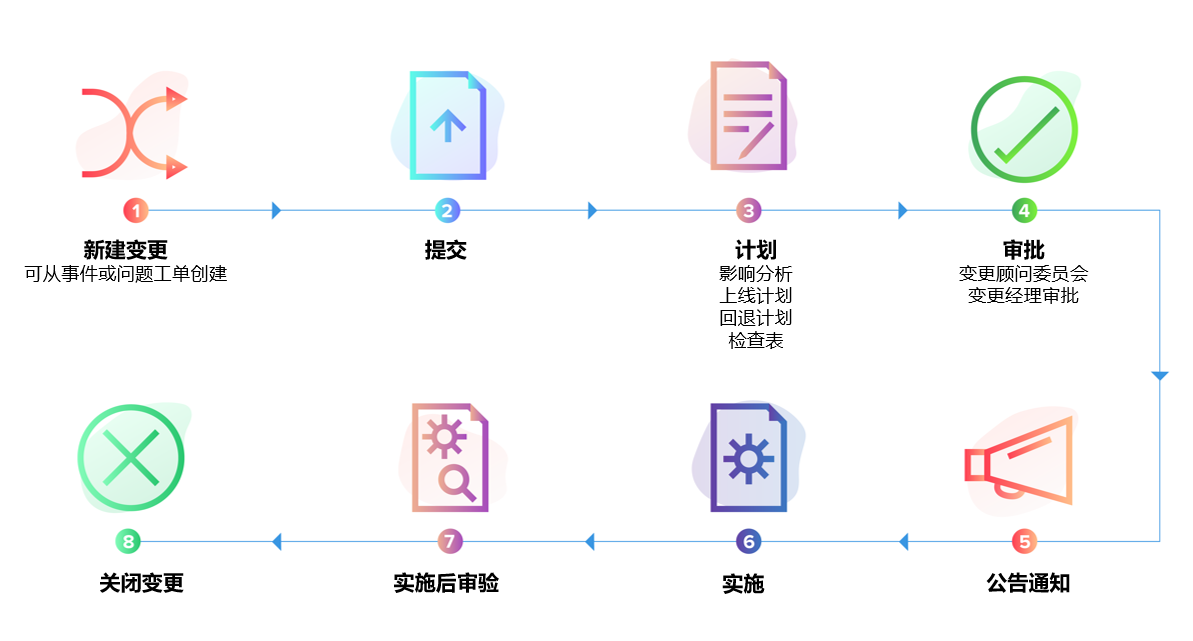
五、把体系长期跑稳:从 ITSM 到“服务经营”的组织能力
90 天能让体系跑起来,但要长期跑稳,需要把它变成组织能力,而不是某个团队的专项。服务经营的关键,不只是工具与流程,而是“角色、节奏、责任与机制”。你需要明确:谁是服务负责人(Service Owner),谁负责指标与改进(Service Ops),谁负责跨部门协同与变更治理(Governance),并建立固定节奏:周看运营、月看趋势、季度做结构性改造。
1)让“服务”成为管理对象:每个服务都有成本与目标
许多组织的 ITSM 只管理“工单”,而不管理“服务”。服务经营要求你把服务当作产品:定义服务目标(体验、可用性、合规)、定义交付方式(自助/自动/人工)、定义成本结构(人力、系统、外包)、定义改进路线图(从手工到自动化,从重复故障到根治)。当服务成为管理对象,预算讨论就会更健康:不是“IT 需要多少钱”,而是“这项服务要达到某个水平,需要怎样的投入与改造”。
2)让“数据”成为共识:统一事实来源,降低跨部门摩擦
治理常常失败在“各说各话”。工单数据如果能成为统一事实来源(Single Source of Truth),就能减少大量扯皮:谁在做、做到哪、为什么慢、慢在哪里、该改什么。特别是在跨部门服务(入职、权限、设备、差旅、门店支持)中,统一事实来源能显著降低协作成本。你会发现,很多体验问题并非技术问题,而是信息不透明导致的焦虑与误解。
3)让“自动化”成为杠杆:用低代码规则把运营动作固化
服务经营离不开自动化。因为当你把改进动作固化为规则与流程时,它才能规模化地生效,而不是靠个人记忆与临时推动。最常见的起点是:自动分派、自动升级、自动通知、自动校验字段、自动关联相似工单、自动触发外部系统动作。通过低代码规则,你可以把很多“运营动作”固化下来,让体系自己运转。
常见问题
1)成本可视化是不是一定要引入复杂的成本核算系统?
不一定。最务实的路径是先从“工单结构化数据 + 时间锚点(工时/等待/返工)”开始,建立可解释的成本分解,再逐步把资产、外包、许可证等成本要素纳入模型。关键是口径统一与可持续沉淀,而不是一步到位做精细核算。
2)如果我们工单分类很乱,应该先改流程还是先改分类?
建议先改“口径”再改流程:先用少量服务目录与请求类型收敛入口,让数据可用、可比,再在高频场景上做流程与自动化优化。分类体系一旦稳定,流程优化的收益会放大很多。
3)如何证明 ITSM 改造带来的价值,而不仅是“更规范”?
用四类指标证明:成本(工时与重复问题)、效率(SLA/首次解决率/自动化履行率)、风险(高影响事件/变更失败率)、体验(满意度/透明度/重复沟通)。如果这些指标在 60–90 天出现趋势变化,你就能把改造从“规范项目”变成“经营改进”。
4)服务产品化一定要做很重的服务目录吗?
不需要。可以从 Top 高频服务开始做“最小目录”,每月迭代。服务产品化的关键是可复用与可度量:让同类请求走同一条路径,让交付步骤可复制,让数据能反映成本与体验变化。
立即体验 ServiceDesk Plus
- 更喜欢云版本?注册试用:点击注册免费试用ServiceDesk Plus(30天全功能);
- 希望本地部署?下载地址:下载ServiceDesk Plus本地版(5个技术员永久免费!);
- 预约专家:需要定制化演示?立即预约1对1方案产品讲解;
- 获取报价,联系销售:填写信息,获取专属报价
限时福利:本月下载注册的用户赠送1小时配置指导服务,助力快速上线!
