ITSM 交付治理:把工单系统做成“可控的组织能力”



很多企业上线 ITSM 系统 或者部署 ITIL 流程 的初衷很直接:统一入口、规范工单、提升效率,最好还能形成可审计的闭环。但现实往往是:系统上线后“看起来很忙”,却难以稳定交付;业务抱怨仍多,IT 团队疲于救火,流程被绕过,口径争论不断。问题不一定出在工具,而常常出在“交付治理”缺位——没有把 IT 服务交付当成一项可以被设计、被运营、被审计、被持续改进的组织能力。
真正成熟的 IT 服务管理,不只是把工单从邮件与群聊里搬到系统里,而是用一套稳定的机制回答三个问题:(1)我们交付的服务是什么;(2)交付质量如何保证;(3)出现波动时如何快速收敛并持续变好。当交付治理建立起来,工单系统才会从“记录工具”升级为“组织运行的服务中枢”。
在平台层面,本文会以 ServiceDesk Plus 这类企业级 IT 服务管理平台为参照,给你一套可落地的交付治理方法论:从服务定义、流程边界、组织职责、指标体系、审计追溯,到上线后的持续运营路线。你可以把它当作一份“把 ITSM 做成组织能力”的操作手册。
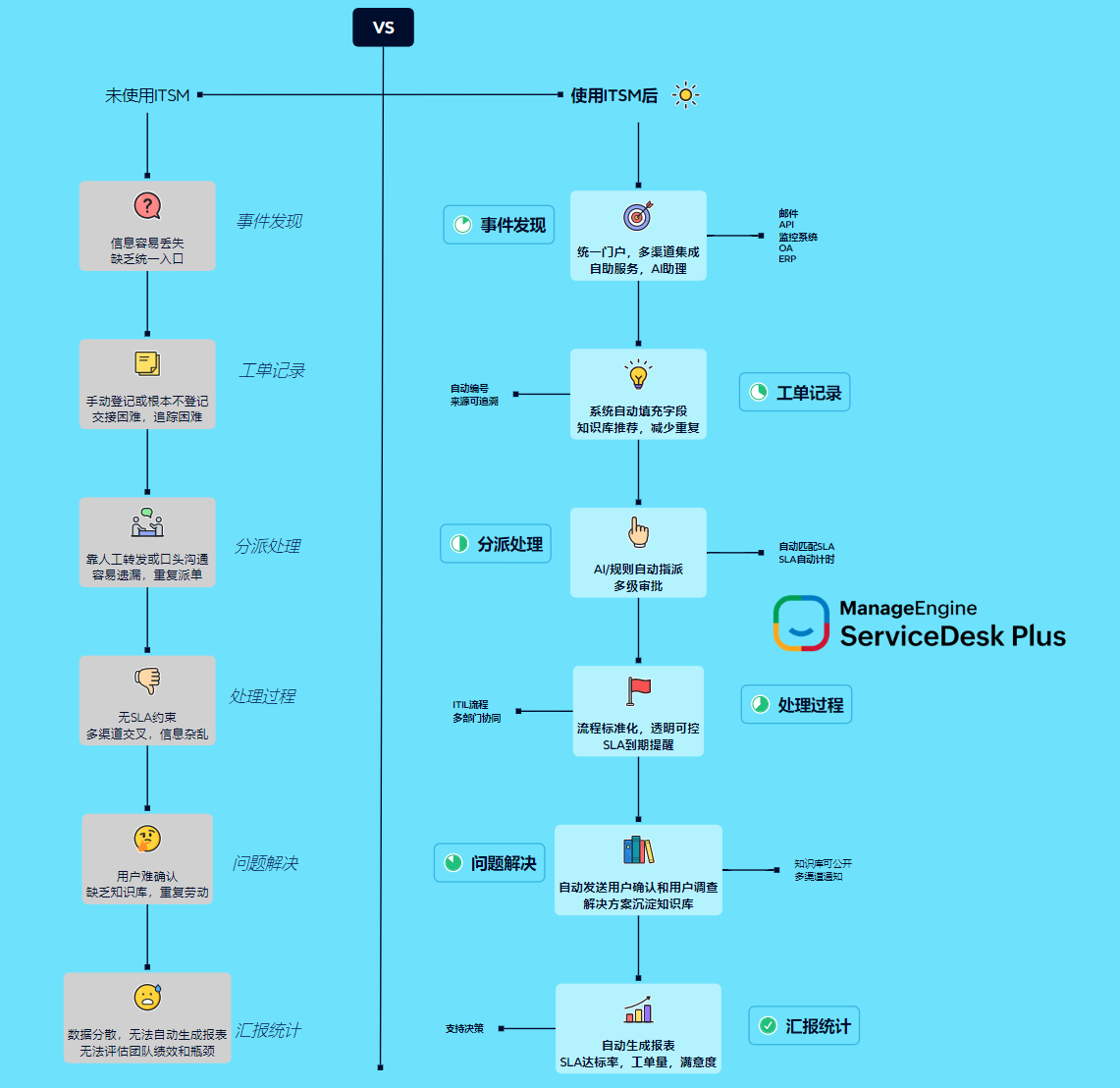
一、交付治理是什么:让“流程执行”变成“结果可控”
很多组织把 ITSM 的成功定义为“工单都进系统、流程跑起来、SLA 看起来达标”。但只要你做过一段时间,就会发现这套定义很脆弱:工单进系统并不等于问题被解决;流程跑起来也不等于体验变好;SLA 达标更不等于业务满意。交付治理要解决的,恰恰是这种“表面合规、结果不可控”的尴尬。
所谓交付治理,本质是一套“可控机制”:它把服务交付拆成可管理的单元,并明确边界、责任、标准、升级路径与审计证据。换句话说,它让组织在面对波动时不再靠个人英雄主义,而是靠机制稳定输出。
- 可定义:服务边界明确,用户知道该选什么,团队知道该交付什么。
- 可承诺:承诺可量化(响应、解决、完成物),并能被追溯。
- 可升级:例外处理有路径,重大风险有机制,不靠“喊人救火”。
- 可审计:关键决策与动作有证据链,合规不靠补材料。
- 可改进:问题不会反复“换人再犯”,而会沉淀为制度与知识。
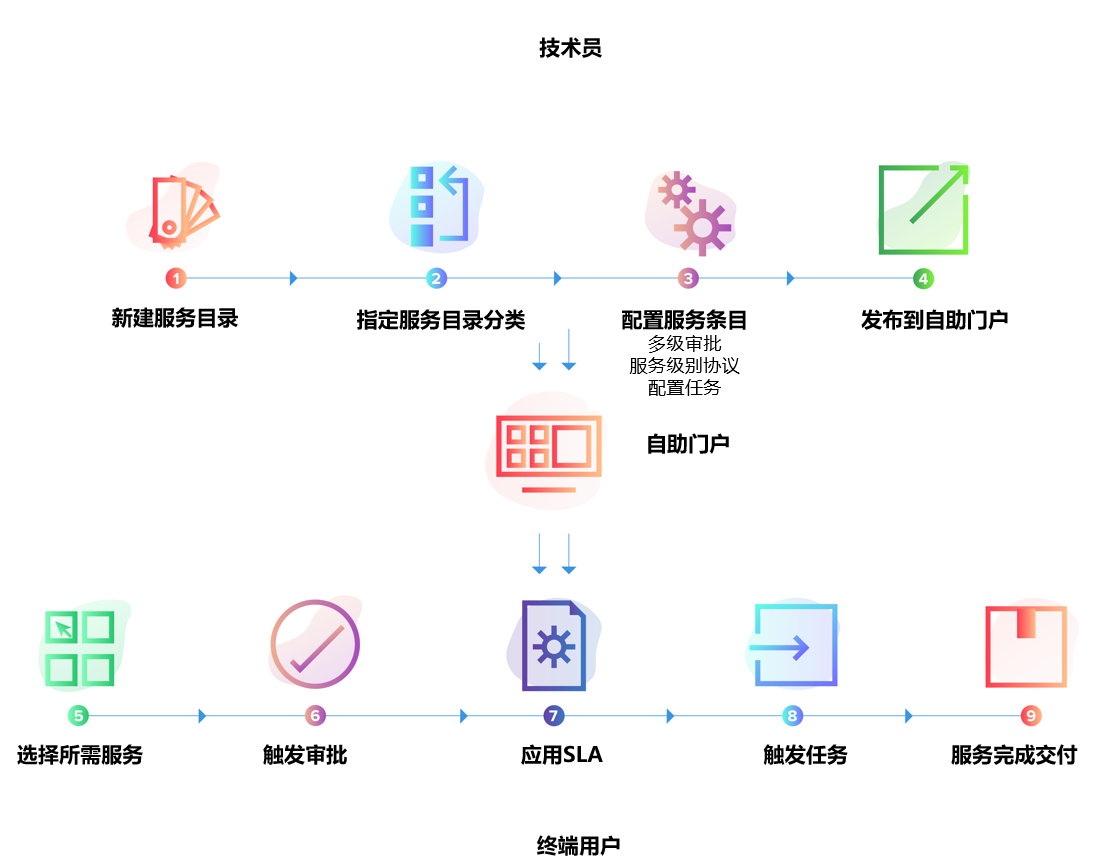
二、先把服务说清楚:服务目录与交付标准的“最小可用版本”
交付治理的第一步不是做一百条流程,也不是把所有工单字段补齐,而是把服务讲清楚:用户要的到底是什么?IT 能交付什么?交付需要什么输入?交付产物是什么?如果这些不清晰,所有流程都会变成“填表运动”,最终被绕开。
1)用“用户语言”描述服务,而不是用 IT 术语
服务目录最常见的失败方式,是把内部术语直接暴露给用户:例如“VPN 权限申请”“AD 组策略调整”“防火墙策略开通”等。对业务来说,这些是实现目标的手段,而不是目标本身。更好的方式是用用户目标来组织服务:远程办公访问、入职账号开通、设备申领与更换、系统权限申请、软件安装与升级等。用户越容易识别,入口越稳定,工单越结构化,后续治理成本越低。
2)交付标准要“可承诺、可验收”
很多组织把服务完成定义为“状态改成已解决”,但用户想要的是“我能继续工作”。因此交付标准必须包含可验收的结果描述:完成物是什么(账号/权限/设备/配置/文档/报告),完成条件是什么(可登录、可访问、可运行、已验证),以及用户需要做什么配合(重启/确认/填写信息)。这会显著降低扯皮与返工。
3)先做“最小可用目录”,不要一次性做全
建议先用“80/20”原则:选出覆盖 80% 需求的 20% 高频服务(例如:账号与权限、设备与软件、访问与网络、常见故障、入离职等),把它们做成结构化模板,定义输入字段与交付标准。先让高频服务变得可控,组织会很快看到收益:工单更规范、解决更快、满意度更稳,后续再扩展目录。
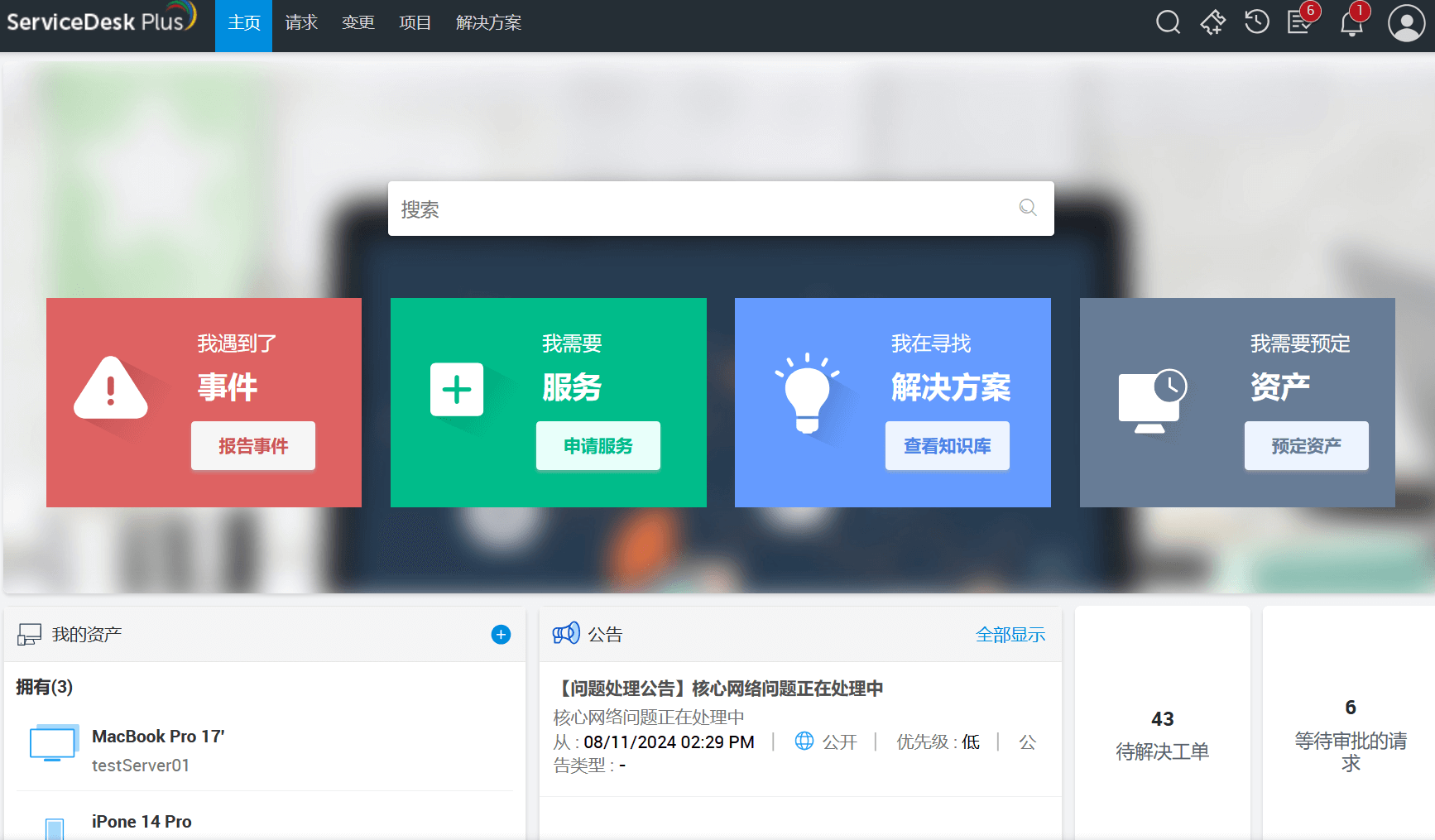
三、流程边界与例外机制:让系统“既严谨又不僵硬”
交付治理的第二步是把流程边界设好:什么必须走强流程,什么可以走轻流程,什么必须升级,什么允许例外。很多 ITSM 失败不是因为流程不够严,而是“该严的地方不严、该灵活的地方太死”。最终导致两种极端:要么流程被绕过、要么流程变成拖累。
1)把请求分成三类:标准、半标准、非标准
标准请求(例如软件安装、账号开通)应高度模板化,能自动分派、自动校验;半标准请求(例如权限申请、设备升级)需要审批与合规校验;非标准请求(例如跨部门特殊需求、紧急业务支持)应走“例外通道”,明确升级路径与记录证据。这样既能保证效率,也能保证合规。
2)例外不是“开后门”,而是可审计的机制
例外一定会发生:重大活动、客户紧急需求、系统突发故障、关键人员临时授权。如果没有例外机制,团队就会私下处理,留下风险黑洞。正确做法是把例外做成机制:例外触发条件、审批人、有效期、回收策略、复盘要求。这样既满足业务弹性,也保留审计证据。
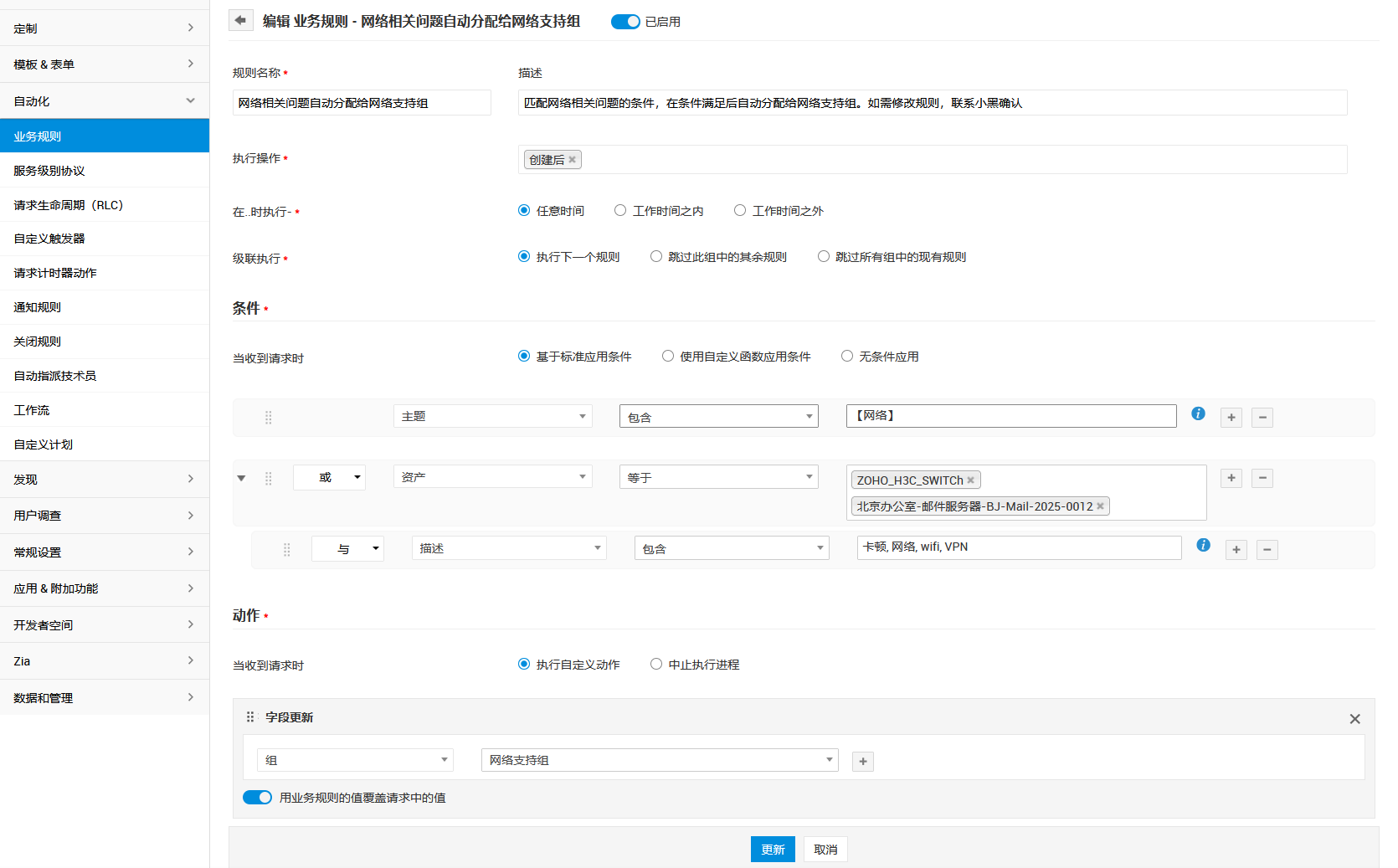
四、组织与职责:把“谁来做”写进体系,而不是写进群聊
交付治理真正难的地方,是组织层面:谁负责什么?谁拍板?谁背 SLA?谁负责复盘?如果职责不清,流程再完整也会变形:该升级的不升级、该通知的不通知、该复盘的不了了之。你需要把“责任结构”显性化,让系统里的每一步都有明确主人。
1)定义三类角色:服务负责人、交付负责人、治理负责人
服务负责人对服务定义与体验负责(服务目录、模板、标准、知识);交付负责人对日常交付效率负责(队列、排班、升级、SLA);治理负责人对风险与合规负责(例外、审批、审计、复盘、改进)。小团队可以一人多角,但职责一定要明确,否则出了问题就会“谁都说不清”。
2)RACI 不是文档,而是系统配置
很多组织写了 RACI 表,但没有进入系统。最终还是靠人记、靠人问。更有效的方式是把 RACI 落进规则:哪些分类自动指派给哪个组;哪些条件触发升级给谁;哪些审批必须走到哪一层;哪些事件必须创建问题记录。把职责变成系统行为,治理才会稳定。
五、指标体系与审计证据:把“交付好不好”变成可证明的事实
交付治理要建立“可证明性”。很多组织最痛的不是做不好,而是做得不错却无法被认可:因为没有一致口径、没有可追溯证据、没有业务听得懂的指标。要解决这个问题,你需要把指标分层:运营层看效率,质量层看复发与稳定,治理层看风险与合规。这样既能支持一线管理,也能支持管理层决策。
1)运营指标:让队列可控、负载可见
- MTTA / MTTR(响应与修复时长)
- 队列积压与年龄结构(长尾是否增长)
- 转派次数与跨组协作比例(摩擦点)
- 首次解决率(FCR)与升级率(复杂度)
2)质量指标:让“解决”不再只是一次性止血
- 复发率 / 重复工单占比(问题是否被根治)
- 问题记录覆盖率与根因完成率(沉淀是否发生)
- 知识复用率与自助解决率(系统是否在变聪明)
3)治理指标:让风险与合规“随运行生成”
- 例外处理次数与理由分布(风险热点)
- 审批逾期与违规比例(流程是否被尊重)
- 重大事件复盘完成率与改进行动关闭率(闭环是否有效)
这些指标的关键不是“多”,而是“可解释”:你要能把指标翻译成业务语言——哪些服务在拖慢业务?哪些请求造成大量返工?哪些变更带来高风险?这样管理层才能把资源投到真正的瓶颈上,而不是被噪声指标牵着走。
六、落地路线:90 天让交付可控,6–12 个月形成稳定机制
交付治理不是“写制度”,而是“跑机制”。建议用分阶段交付的方式推进:先把高频服务做成可控单元,再把例外机制与审计证据固化,最后形成持续运营节奏。下面是一条可执行路线,你可以直接拿去当项目计划:
第 1–30 天:最小可用服务目录 + 责任结构落地
选出 20% 高频服务(覆盖 80% 需求),把模板字段与交付标准做清楚;明确服务负责人/交付负责人/治理负责人职责;把基础指派与升级规则落进系统。目标是让“入口统一、字段结构化、队列可见”,从第一天起就开始积累可治理数据。
第 31–60 天:例外机制上线 + 指标分层仪表板上线
把例外通道做成可审计流程:触发条件、审批、有效期、回收与复盘要求;同时搭建运营/质量/治理三层指标仪表板,定义口径并固定输出节奏。此阶段的成果是:组织开始用同一套事实对齐“问题是什么、风险在哪、该怎么改”。
第 61–90 天:复盘机制固化 + 改进动作闭环
选取高影响事件与高复发服务做专项复盘;把改进行动拆成可执行任务并跟踪关闭;把“有效改进”沉淀为标准模板/知识文章/流程规则。90 天目标不是“零事故”,而是让组织拥有一种可复制的改进机制,减少“反复踩坑”。
第 4–12 个月:扩展覆盖 + 把治理变成组织节奏
逐步扩展服务目录覆盖范围;把更多团队纳入统一口径;完善质量指标(复发率、知识复用、自助率);定期召开服务评审与治理评审,让交付治理成为组织节奏的一部分。最终你会获得一个“可控、可审计、可持续变好”的 IT 服务交付体系。
平台承接:ServiceDesk Plus 如何支撑交付治理落地
从工具角度看,交付治理最怕“分散”:入口分散、口径分散、证据分散,导致治理成本飙升。以 ServiceDesk Plus 为例,它能够把服务目录、工单流程、SLA、问题与变更、资产与报表仪表板统一在一套体系中,让规则、责任、指标与审计证据围绕同一套数据语义运转。这样你才可能用更低的组织成本跑出“可控交付”的机制,而不是把治理变成额外负担。
常见问题
1)交付治理会不会让流程更慢?
短期可能会多一些结构化输入,但长期会显著减少返工、扯皮与升级救火的时间。治理的目标是降低隐性摩擦,而不是增加表面步骤。
2)团队小、人手紧,也需要这么做吗?
越小的团队越依赖关键个人,风险越高。交付治理能把经验沉淀为机制与知识,降低个人依赖,反而更重要。
3)最推荐的起点是什么?
从“最小可用服务目录 + 责任结构”起步:先把高频服务做成可控单元,再上例外机制与指标分层,最后固化复盘闭环。
4)如何避免流程被绕过?
核心是降低入口摩擦(用户好选、模板清晰)、提升结果确定性(进度可见、交付可验收)、并把例外机制做成“正规通道”。只靠强制,绕过一定会发生。
5)怎么证明交付治理真的有效?
看三件事:复发率是否下降、长尾工单是否收敛、改进行动是否能按期关闭;同时看满意度与自助率是否上升。治理有效一定能在指标上体现。
把 ITSM 做成组织能力,关键不在“流程有多全”,而在“交付是否可控、风险是否可审计、改进是否可持续”。你可以从高频服务与最小治理机制开始,逐步形成服务目录、责任结构、例外机制、指标分层与复盘闭环的完整体系,让 IT 从“救火队”转向“稳定的服务交付者”。
- 更喜欢云版本?注册试用:点击注册免费试用 ServiceDesk Plus(30 天全功能);
- 希望本地部署?下载地址:下载 ServiceDesk Plus 本地版(5 个技术员永久免费);
- 需要定制化演示?立即预约 1 对 1 方案产品讲解。
