IT 服务财务透明化:构建可量化、可预测的 IT 成本治理体系



在数字化转型背景下,IT 服务管理 已不再只是技术问题,而成为企业战略投资的重要组成部分。 然而,在许多组织中,IT 成本仍然处于“黑盒”状态: 预算支出难以拆分、服务价值难以量化、ITIL 流程与财务体系脱节。
借助 ServiceDesk Plus 等统一服务平台, 企业可以将工单数据、资产成本、SLA 承诺与财务指标整合, 实现真正的 IT 服务财务透明化。
一、为什么 IT 成本长期难以量化?
IT 成本复杂的原因主要包括:
- 基础设施与业务系统混合计费
- 跨部门资源共享
- 隐性人力成本难以统计
- 服务质量与成本脱节
当管理层无法清晰了解 IT 成本结构, IT 部门就容易被视为“高成本中心”。
二、服务视角下的成本拆分模型
财务透明化的第一步,是从“系统成本”转向“服务成本”。
可按以下维度拆分:
- 基础设施成本(服务器、网络、云资源)
- 软件授权成本
- 支持人力成本
- 运维与升级成本
通过将资产与服务目录关联, 企业可以计算出单项服务的真实成本。
三、SLA 与成本挂钩:高质量是否意味着高成本?
SLA 通常被视为服务质量指标, 但很少与成本结构直接关联。
事实上,不同响应级别的 SLA, 对应不同的人力与资源投入。
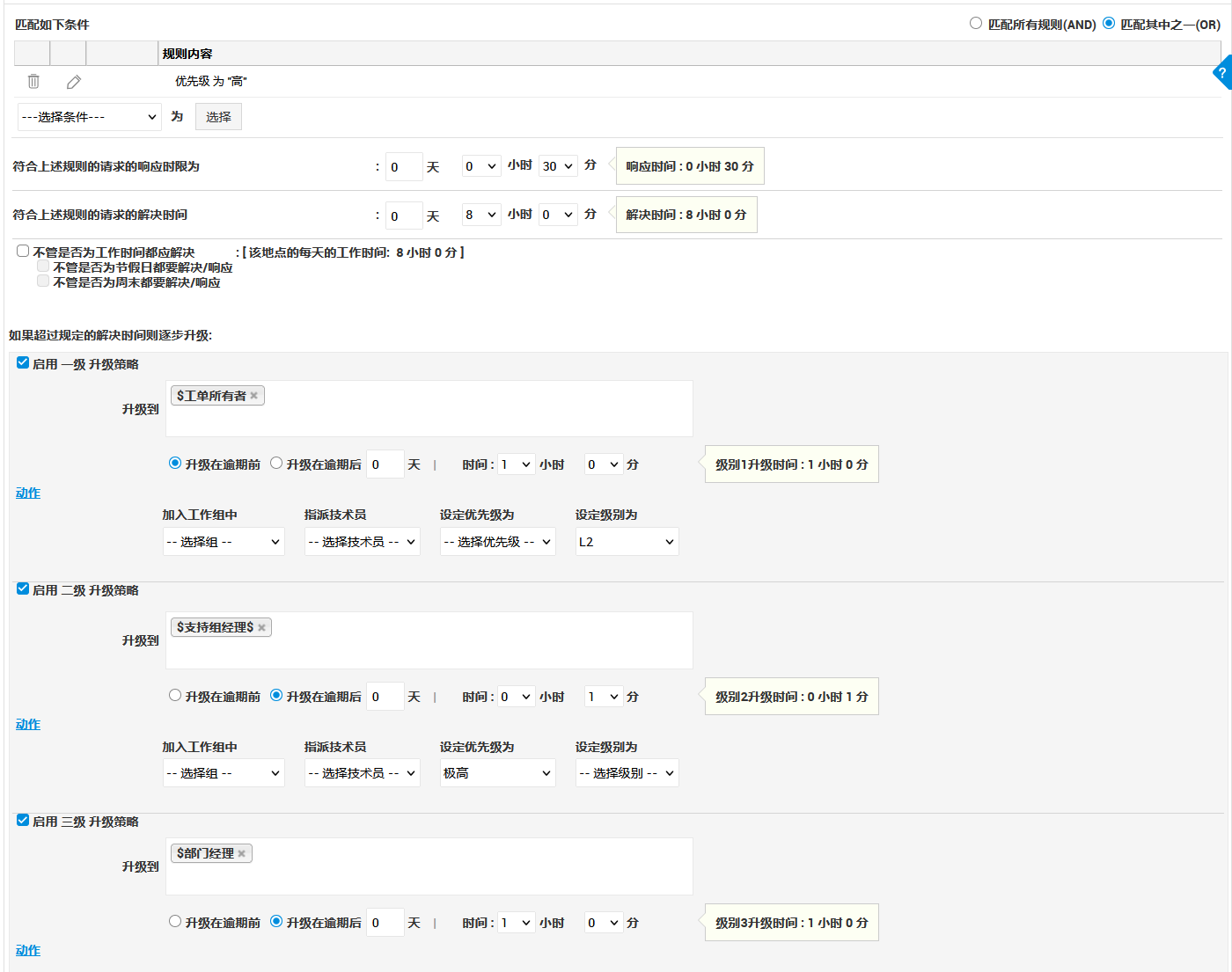
当 SLA 与成本模型结合, 企业可为不同业务部门提供差异化服务等级与预算分配。
四、Showback 与 Chargeback:让成本真正“看得见”
IT 服务财务透明化的核心机制之一, 是建立 Showback(成本展示)或 Chargeback(成本分摊)体系。
Showback 模式强调向业务部门展示其实际使用的 IT 服务成本, 但不直接收费;Chargeback 则根据使用量进行内部结算。
- Showback:提升业务部门对 IT 资源使用的认知
- Chargeback:建立责任归属与预算约束机制
当每个部门都能看到自身 IT 服务消耗结构, 成本优化将不再是单向压缩, 而是基于数据的共同决策。
五、预算预测模型:从历史数据到未来规划
传统预算编制依赖历史支出数据, 但在数字化环境中, 业务增长与技术变革速度远超历史趋势。
预测模型通常结合:
- 工单增长趋势
- 资产生命周期数据
- 系统使用频率
- 业务扩展计划
通过趋势预测, IT 部门可提前规划硬件更新、许可证续约与人员配置, 避免预算突发增长。
六、数据驱动决策:将服务质量与成本对齐
当 IT 成本透明后, 下一步是将服务质量与成本结构结合分析。
例如:
- 某业务系统 SLA 提升 20%,是否对应成本增长?
- 自助服务率提升是否降低了支持人力成本?
- 重复故障是否导致额外资源浪费?

通过将工单、资产与财务数据整合, CIO 可以向管理层提供清晰的 ROI 报告。
七、案例:金融企业的 IT 成本转型实践
某金融企业在实施服务财务透明化前, IT 预算每年增长 15%, 但业务部门对其价值缺乏认知。
通过建立:
- 统一服务目录与资产映射
- 部门 Showback 报告
- 预测预算模型
在一年内实现:
- 重复资源采购减少 18%
- 云资源浪费降低 22%
- 预算增长率控制在 6%
同时,IT 在董事会中的战略地位显著提升。
八、IT 财务透明化成熟度模型
Level 1:成本汇总
仅统计总预算与支出。
Level 2:成本分类
按资产与系统分类成本。
Level 3:服务映射
将成本映射至具体服务目录。
Level 4:预测与优化
基于趋势数据进行预算预测与持续优化。
九、落地路线图:从“看得见”到“管得住”
IT 服务财务透明化并非一次性项目,而是一套持续运营体系。 建议采用“循序渐进”的落地路线,确保每一步都有可验证成果。
阶段 1:数据统一(4–8 周)
- 统一工单入口与分类标准
- 建立资产清单与成本字段
- 确立服务目录与责任人
阶段 2:服务成本模型(8–12 周)
- 建立服务-资产-人力映射
- 输出部门 Showback 报告
- 与 SLA 指标联动分析
阶段 3:预算预测与优化(持续)
- 建立趋势预测模型
- 定期识别浪费点与重复采购
- 持续优化服务等级与预算分配
当路线图持续推进后,财务透明化将从“报告输出”变为“管理机制”, 让 IT 预算的每一笔投入都能被解释、被追踪、被优化。
十、从成本治理到价值证明:CIO 的关键表达方式
真正成熟的 IT 财务透明化,不仅是为 CFO 提供数据, 更是帮助 CIO 建立“价值表达能力”。
建议 CIO 在汇报中采用“三段式价值表达”:
- 成本节约:减少浪费、提升利用率、降低重复采购
- 效率提升:缩短等待时间、提升自动化覆盖、提高一次解决率
- 风险降低:减少重大事件、提升合规审计可追溯性
常见问题
1)Showback 与 Chargeback 必须二选一吗?
不必。许多企业会先采用 Showback 建立透明度与共识,再逐步引入 Chargeback。 如果你希望先统一流程与数据口径,可参考 ITSM 建设指南。
2)没有 CMDB 能做成本透明化吗?
可以先从“资产清单 + 服务目录 + 工单数据”入手,但 CMDB 能显著提升服务映射与影响分析精度。 建议逐步补齐配置管理能力。
3)如何衡量财务透明化项目是否成功?
可通过重复采购降低比例、云资源浪费下降、预算预测偏差收敛、以及业务部门满意度提升进行综合评估。
4)SLA 提升一定会导致成本上升吗?
不一定。若通过自动化与自助服务提升交付效率, SLA 提升可能伴随单位成本下降。 可参考 ITIL 实践 中关于持续改进的思路。
5)中小企业是否需要做 Chargeback?
多数中小企业更适合从 Showback 开始,以透明化推动自发节约,而非复杂内部结算。
立即体验 ServiceDesk Plus,建立可量化的 IT 成本治理体系
- 更喜欢云版本?注册试用: 点击注册免费试用 ServiceDesk Plus(30天全功能);
- 希望本地部署?下载地址: 下载 ServiceDesk Plus 本地版(5个技术员永久免费);
- 需要定制化演示? 立即预约 1 对 1 产品讲解。
