IT问题管理怎么做?从反复救火到根治故障的ITIL问题管理实战指南



同一台服务器每隔一个月就宕机一次,每次技术员花两小时重启恢复,恢复之后皆大欢喜——直到下一个月再次宕机。同样的故障,同样的抢修,周而复始,没有人去追问:为什么它总是宕机?
这正是IT事件管理与IT问题管理之间最核心的差异:事件管理的目标是"快速恢复服务",问题管理的目标是"找到根本原因、防止问题再次发生"。只有事件管理而没有问题管理的IT团队,永远活在救火模式里,无法真正走出重复故障的泥潭。
本文将围绕三个问题展开:IT问题管理与事件管理有何本质区别?企业在问题管理落地中容易踩哪些坑?ITIL流程框架下的问题管理如何通过系统工具真正落地?
一、事件管理 vs. 问题管理:为什么只救火远远不够?
在ITIL框架中,事件(Incident)和问题(Problem)是两个明确区分的概念,却经常被企业混为一谈:
- 事件(Incident):任何导致或可能导致IT服务中断、质量下降的非计划性事件。事件管理的目标是以最快速度恢复正常服务,不强求找到根本原因。
- 问题(Problem):一个或多个事件的根本原因,或潜在的未知错误。问题管理的目标是识别根本原因、记录已知错误(Known Error),并通过永久性解决方案防止事件再次发生。
用一个比喻来说明:地板漏水了,拖干地板是"事件管理"——快速恢复;找到管道哪里破了并修复它,是"问题管理"——根治。只拖地不修管道,地板会一直漏。
很多IT团队之所以陷入"每天救火"的困境,正是因为只有成熟的事件管理,而问题管理形同虚设——没有系统性地分析重复事件的根源,没有"已知错误数据库"沉淀经验,每次故障都当作全新事件处理,消耗大量人力。
数据参考:根据 Gartner 研究,在缺乏问题管理流程的企业中,重复性事件平均占所有事件工单的 35%~45%。而建立规范问题管理流程后,企业的重复性事件占比通常可以下降至 15%以下,技术员的有效工时利用率提升超过 20%。
二、IT问题管理的三个关键阶段与常见落地误区
ITIL将问题管理分为三个核心阶段,每个阶段都有其特定目标和常见失误:

阶段一:问题识别与记录
问题的来源通常有三个:主动分析事件趋势发现潜在根源、技术员在处理事件时识别出深层问题、供应商或监控系统主动告警。常见误区是"等故障够严重了再立问题",导致大量中低级别的反复事件积累,形成慢性运维负担而无人察觉。
阶段二:根本原因分析(RCA)
这是问题管理最核心、也最容易流于形式的环节。常用的RCA方法包括5 Whys分析、鱼骨图、故障树分析等。常见误区是"RCA报告写了但没人看""结论停在表面原因而非根本原因",以及"分析完了没有后续行动项跟踪"。一次没有行动项的RCA,等于一次无效的复盘。
阶段三:已知错误管理与永久性解决
当根本原因已知但永久性解决方案尚未实施时,应当在已知错误数据库(KEDB)中记录该问题及其临时解决方案(Workaround),使技术员在下次遭遇相同事件时能够快速定位并应用已知处理方法,将影响时间压缩到最低。常见误区是"KEDB存在于某个技术员的脑子里"而没有被系统化记录。
三、哪些事件应该触发问题管理?建立触发标准
问题管理的资源是有限的,不是每一张事件工单关闭后都需要触发问题分析流程。建立清晰的触发标准,是问题管理能够持续运转而不会让团队不堪重负的关键:
- 重复性触发:同一类型事件在30天内发生2次及以上,自动触发问题记录创建
- 重大影响触发:单次事件影响用户数超过阈值(如影响50人以上),或导致核心系统不可用超过30分钟
- 主动识别触发:技术员在处理事件过程中发现明显的系统性缺陷,主动关联或创建问题记录
- 趋势分析触发:IT主管在月度数据回顾中发现某类工单量呈上升趋势,主动发起问题调查
在ServiceDesk Plus中,前两类触发标准可以配置为自动化规则,当满足条件的事件工单关闭时,系统自动提示或创建问题记录,确保高价值的问题分析机会不被遗漏。
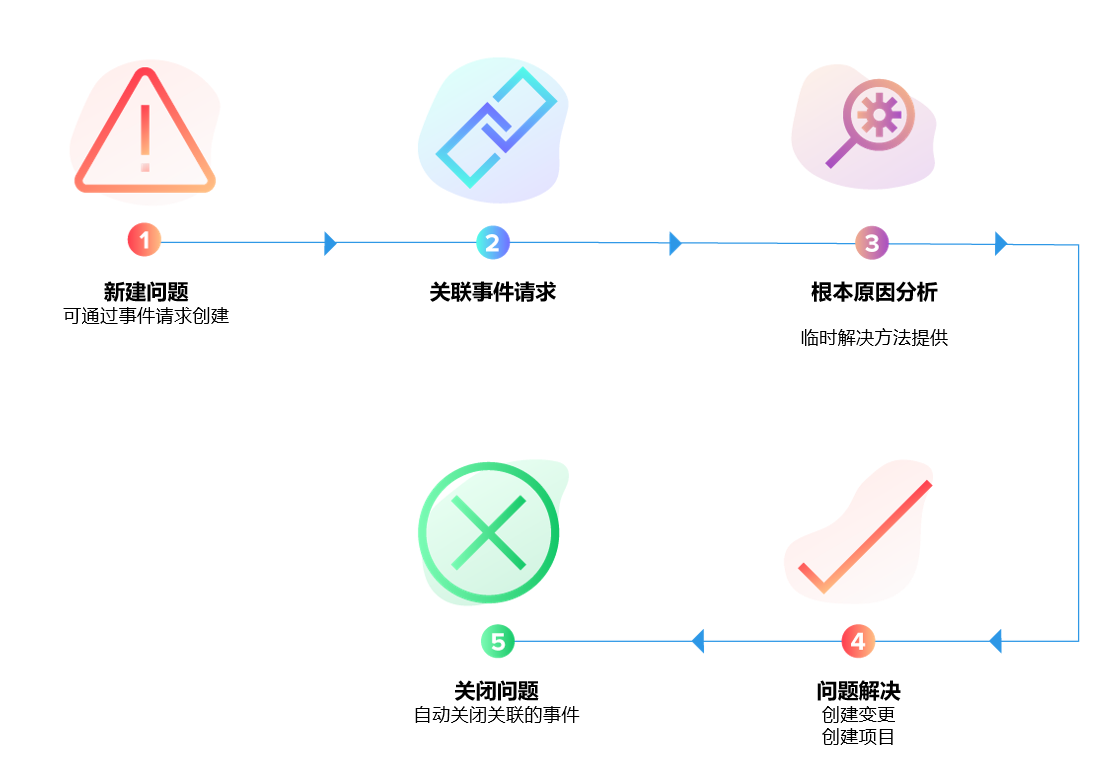
四、ServiceDesk Plus 如何将问题管理从"理论"变为"日常"?
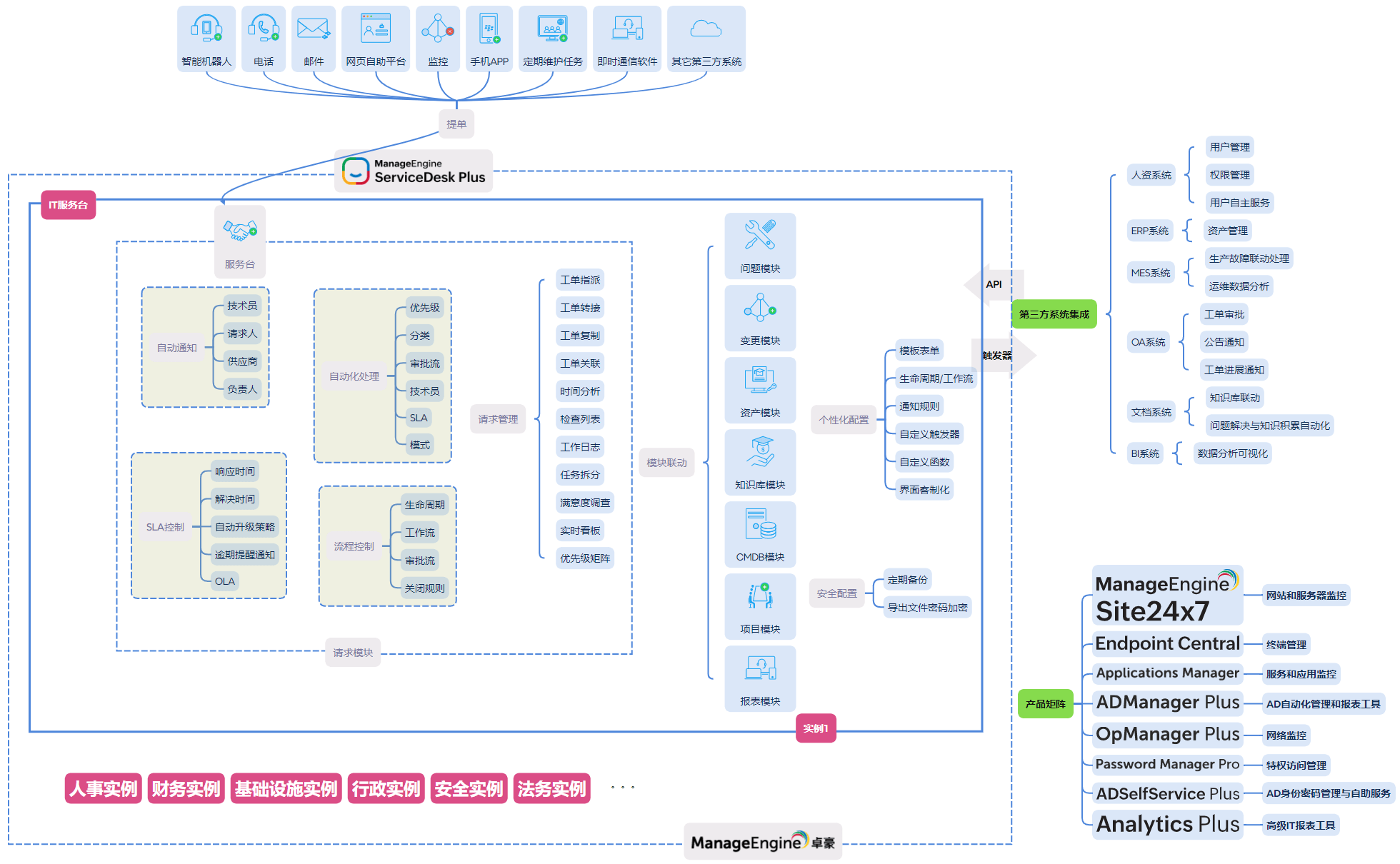
ServiceDesk Plus 的问题管理模块与事件管理、知识库、变更管理深度集成,让问题管理不再是一个独立的"额外工作",而是嵌入IT服务日常流程中的自然环节。
① 事件自动关联问题,从趋势中发现根源
技术员在处理事件时,可以一键将该事件关联至已有问题记录,或创建新的问题记录。系统自动统计每个问题关联的事件数量和影响范围,帮助IT主管快速识别"哪些问题最值得优先投入资源根治",而不是凭感觉决策。
② 结构化RCA记录,分析结果有据可查
系统内置RCA记录模板,支持5 Whys等常用分析方法的结构化填写,分析结论、行动项、责任人、完成时限一目了然。行动项完成后由责任人在系统内确认,全程留痕,避免"分析了但没落实"的老问题。
③ 已知错误数据库(KEDB)与知识库联动
问题记录中的临时解决方案(Workaround)可一键转换为知识库文章,供全体技术员和员工查阅。当相同事件再次出现时,技术员在工单页面即可看到"已知问题及处理方法"的提示,大幅缩短事件处理时间。
④ 问题与变更联动,永久性解决方案闭环跟踪
当问题的永久性解决方案需要通过变更来实施时,可以直接从问题记录发起变更申请,变更审批通过并实施后,问题状态自动更新为"已解决",形成完整的问题→变更→关闭闭环,不会出现"问题记录挂在那里没人跟进"的情况。
⑤ 问题管理报表,量化运营改善效果
IT主管通过报表追踪:问题平均解决时长趋势(是否在缩短)、重复事件率变化(是否在下降)、KEDB覆盖率(有Workaround记录的问题占比)、因问题管理触发的变更数量。这些数据证明问题管理投入的价值,也为持续优化提供方向。
五、真实案例:问题管理如何打破重复故障的循环
📌 案例一:某电商平台——核心系统"月月宕机",问题管理介入后8个月零复发
背景:KK电商公司核心交易系统在过去一年内发生了11次故障,平均每月一次,每次故障导致系统不可用30~90分钟,直接影响销售额和用户体验。IT团队每次都能在两小时内恢复系统,但故障始终周期性复发。
根本原因:引入ServiceDesk Plus后,IT团队对过去11次故障事件进行系统性关联分析,发现其中9次均与数据库连接池在高并发场景下的耗尽有关。过去每次故障都以"重启服务"结束,没有人将这些事件关联为同一个问题,更没有触发针对性的根本原因分析。
解决过程:问题记录创建后,技术团队完成RCA,明确根本原因为连接池配置参数不适配业务增长后的并发量。行动项包括调整连接池参数、增加连接监控告警、制定连接池扩容预案。永久性解决方案通过变更管理流程审批后实施。
成果:变更实施后,该故障类型在此后8个月内零复发;技术员从每月一次的紧急救火中彻底解放,将节省出的时间投入到系统性能优化项目中;IT部门季度总结会上"主动解决"项目首次超过"被动响应"项目。
📌 案例二:某制造集团——多工厂MES系统同类故障各自为战,问题管理实现全集团协同根治
背景:LL制造集团在全国有5个生产基地,各基地使用同一套MES系统,但IT运维分散在各基地独立管理。某类MES数据同步故障在不同工厂分别出现了多次,各基地均独立处理,互相不知情,重复投入了大量人力,且部分基地采用了错误的处理方法导致数据损坏。
引入ServiceDesk Plus后:集团IT部门建立统一的问题管理记录,各基地发生的MES相关事件统一关联至同一问题记录,RCA在集团层面统一开展。最终确认根本原因为MES与ERP系统之间的接口在网络抖动时的异常处理逻辑缺陷,并协调软件供应商发布了补丁。
成果:补丁部署后,五个基地的MES同步故障全部消除;集团IT节省了原本分散在各基地的重复排查工时约240小时/年;已知错误处理方案沉淀至知识库,供各基地技术员统一参考,新问题的响应速度提升60%。
写在最后:问题管理,是IT团队走向主动运维的关键一步
事件管理让IT团队能够"快速响应",而问题管理让IT团队能够"提前预防"。两者相辅相成,缺一不可。一个只有事件管理的IT团队,永远是被动的、疲惫的;加入问题管理之后,IT团队才真正具备了从"救火队员"向"系统守护者"转型的能力。
ServiceDesk Plus 将事件管理、问题管理、变更管理、知识库整合在同一平台,让每一次故障都有机会成为系统性改进的起点,而不仅仅是一条关闭的工单。如果你的团队正在被重复故障困扰,从建立第一条问题记录开始,就是改变的第一步。
立即体验 ServiceDesk Plus,从根源解决重复IT故障
| ☁️ 免费注册云版本 | 💻 下载本地版 | 📅 预约专家演示 |
常见问题解答(FAQ)
延伸阅读:
