IT灾备计划怎么做?ITSM支撑业务连续性管理实操指南



那是一个周三上午10点17分。某零售公司核心订单系统突然停止响应,全国83家门店收银机同时卡死。IT运维负责人接到报警,第一反应是打开灾备预案文档——文档在内网服务器上,而内网已经不通了。他记得预案里写着"联系网络工程师李建",但李建三个月前已经离职。备用机房在哪、哪个云服务商有备份,这些问题的答案全在那份打不开的文档里。
这不是极端案例。我们和大量企业IT团队交流后发现,大多数灾备计划存在同一个根本问题:它是为了"有文档能应付检查"而存在的,而不是为了"真正能用"而设计的。 合规审计时能拿出来,真正发生故障时完全指望不上。
本文将围绕三个问题展开:企业IT灾备计划为什么总在关键时刻失灵?业务连续性管理(BCM)落地要解决哪些真实难题?ITSM平台如何让灾备从"文档里的规划"变为"系统驱动的真实能力"?
一、灾备计划为什么总在关键时刻失灵?五个真实原因
把大量"灾难恢复失败"的案例拆开来看,失灵的原因高度集中:
① 预案文档存放在灾难发生后根本访问不到的地方
灾备文档存在内网Wiki、公司文件服务器,或者某个工程师的桌面。一旦主机房宕机、网络中断,文档和故障同时消失。真正有价值的灾备计划,必须在"什么都不工作"的情况下依然能被访问——存在云端、存在手机离线文档、甚至打印后贴在机柜门上,都比"存在内网"强。
② 联系人信息过时,文档写完就再没有人更新
预案里的联系人离职了、换号了、转岗了,但文档从两年前写完就没人动过。真实故障时打过去的是已注销的手机号,发出去的是弃用的邮箱。联系人信息必须有人员变动时的强制更新触发机制,不能靠人记忆。
③ RTO/RPO目标是拍脑袋定的,从未经过真实场景验证
文档写的是"4小时内恢复",但没有人计算过:定位根因需要多久?启动备用系统需要多久?通知全员切换需要多久?不经过演练验证的RTO只是一个数字——在审计报告里好看,在真实灾难里没有意义。
④ 灾备演练从未真正进行,或走了形式
很多企业的"灾备演练"是会议室里口头讨论"如果发生X我们会做Y"——这是讨论,不是演练。真正的演练要模拟系统不可用,验证备用流程能否运转,验证恢复时间是否达到目标,记录发现的缺陷并跟踪修复。没有演练的灾备计划,在真实灾难中几乎必然暴露未知缺陷。
⑤ BCM团队和IT运营团队的信息两张皮
BCM文档里说"系统A是关键系统",但IT运维不知道系统A的备份在哪;IT知道备份在云端,但BCM的恢复步骤是基于三年前老架构写的。两套体系平时不往来,灾难来了信息完全对不上。
真实代价:根据 Gartner 研究,企业IT系统宕机的平均成本为每分钟约 5600 美元;无有效灾备计划的企业在重大故障中平均恢复时间超过 8小时;有经过演练验证的灾备计划的企业,同类故障平均恢复时间不超过 2.3小时——差距接近 4倍。
二、业务影响分析(BIA):灾备建设的起点不是技术,而是业务
很多IT团队从技术层面开始设计灾备——"服务器要做主备切换"——但科学的灾备建设起点是业务影响分析(BIA):先搞清楚哪个业务流程停摆损失最大,再决定哪些IT系统需要最高级别的保护。
BIA核心只需要回答三个问题,每个答案对应一个关键灾备参数:
- 这个流程停摆多久会造成不可接受的损失? → 决定 RTO(恢复时间目标)
- 数据最多可以丢失多少时间段内的内容? → 决定 RPO(恢复点目标)
- 支撑这个流程的关键IT系统有哪些? → 决定灾备优先级和投入
以一家零售企业为例,BIA结果可能是:
| 业务流程 | RTO目标 | RPO目标 | 依赖关键系统 |
|---|---|---|---|
| 门店收银与订单 | 30分钟 | 5分钟 | POS系统、订单数据库 |
| 供应链库存管理 | 2小时 | 1小时 | ERP、WMS仓储系统 |
| 员工协作与通讯 | 4小时 | 24小时 | 企业微信、邮件服务器 |
| HR与薪资管理 | 24小时 | 24小时 | HR系统、OA平台 |
BIA完成后,IT团队就有了清晰的投入优先级:收银系统的灾备投入远高于HR系统,这不是IT主管的主观判断,而是业务影响数据决定的。把有限的预算花在最关键的地方,才是有效的灾备建设。
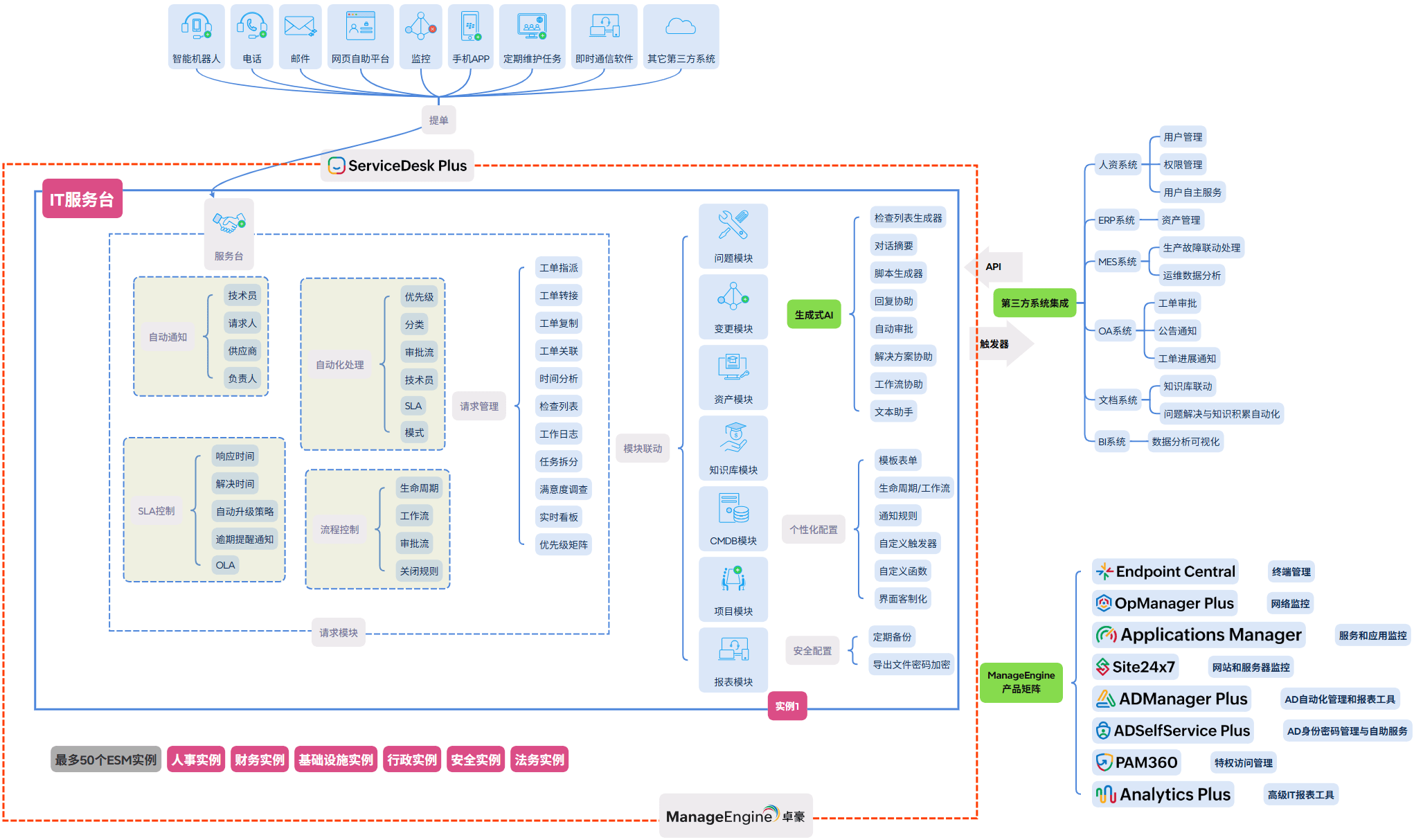
三、ServiceDesk Plus 如何让灾备从文档变为系统能力?
灾备计划失效的根本是"知识锁在文档里、流程靠人记忆"。ServiceDesk Plus 通过将灾备响应内化为IT工单管理的标准化流程,解决这个结构性问题。
① 灾备预案作为服务目录条目——触发即执行,无需翻文档
将不同场景的灾备响应("核心数据库故障""机房断电""运营商链路中断")配置为服务目录的专项条目,每个条目内置完整响应任务清单:谁做什么、按什么顺序、需要多长时间、验证标准是什么。灾难发生时负责人点击触发预案,系统自动创建工单并向所有相关人员推送企业微信/钉钉通知——不需要翻文档,不靠记忆,流程在系统里等着被执行。
② 关键信息在资产管理和供应商档案中实时维护
灾备响应依赖的关键信息(备用系统位置、云平台账号、供应商紧急联系、备份存储地址)存储在ServiceDesk Plus的CMDB和供应商管理模块中。人员变动、供应商更换时更新一处全局同步。系统设置定期审查提醒——每季度自动通知灾备负责人确认关键联系人是否仍然在职,不再靠人记忆维护。
③ 灾备演练作为正式项目执行,发现的问题持续跟踪
每次演练在IT服务管理软件中创建正式项目,包含演练计划、任务分工、实际耗时记录、发现缺陷和改进行动项。演练结束后自动生成报告,与BIA中的RTO/RPO目标对比,直观显示"目标 vs 实际"差距。改进行动项创建为后续工单持续追踪,确保演练发现的问题被真正修复。
④ P1事件工单自动关联灾备预案,响应窗口显示可用预案
当监控告警触发P1事件工单时,系统自动检查受影响系统是否有对应灾备预案,并在工单页面显示"该系统有以下灾备预案可用"的快速链接。技术员处置故障的同时,可以一键查看并启动灾备响应流程,无需切换系统,响应时效大幅提升。
⑤ 基础设施变更自动触发灾备预案的更新提醒
IT架构发生重大变更(数据库迁移、备用机房切换、云服务商更换)时,对应变更工单自动关联受影响的灾备预案,提醒灾备管理员"该预案需要同步更新"。这个联动机制解决了"IT环境变了但预案还是旧架构"的长期隐患,让灾备文档的有效性随IT变更自动维护。
四、真实场景还原:有灾备和没有灾备的差距
📌 案例一:同样是核心数据库故障,两家公司截然不同的结局
A公司(无有效灾备计划):周五下午4点52分,核心订单数据库因磁盘阵列故障停止响应。IT团队排查15分钟确认硬件故障,联系厂商,厂商说备件次日才能到。团队开始找备份,发现备份策略三个月前改过,最新有效备份在另一台服务器,但还原流程从没完整演练过。折腾11小时,周六凌晨4点系统勉强恢复,数据损失约3小时,估算损失订单约120万元。
B公司(有系统化灾备):同样的场景,ServiceDesk Plus检测到数据库异常立即创建P1工单,工单页面自动显示"核心数据库灾备预案"链接。响应负责人点击触发预案,系统自动向4名相关技术员推送企业微信通知,任务清单即时可见:启动云端备用数据库实例、切换应用服务器连接、通知业务团队临时切换手工流程。全程记录时间戳。从故障发现到订单系统恢复:42分钟。数据损失:8分钟(最后一次RPO备份以来)。
📌 案例二:演练发现RTO目标无法实现,提前修复避免了真实灾难
背景:SS制造企业MES系统灾备预案写明"2小时内恢复",但IT主管心里没把握——这个数字两年前写的,架构已大幅调整。主管决定在ServiceDesk Plus中安排一次真实演练。
演练暴露的问题:模拟MES主服务器宕机,按预案操作,实际恢复时间:5小时17分钟——远超2小时目标。深入分析发现两个缺陷:备用数据库需要手动同步一批离线数据(新增的业务逻辑,预案没有更新);恢复步骤有3步依赖一个已离职工程师持有的专有工具账号密码,现在没人有。
成果:演练结果作为工单在ServiceDesk Plus记录,两个缺陷分别在演练后6天和12天内修复完成。3个月后第二次演练:实际恢复时间1小时44分钟,达标。IT主管在事后复盘时说:"如果不是演练暴露了这些问题,真实灾难来临时5小时的恢复时间会让生产线停工,那个代价可能是几百万。演练的代价是一天,提前规避的损失远不止这个数字。"
写在最后:灾备不是一份文档,而是一套随时可以运转的能力
灾备计划的价值不取决于文档写得多详细,而取决于灾难真正来临时,团队能否在极度压力下快速、有序地执行正确操作。这需要流程在系统里固化、联系人信息实时有效、演练结果有记录、改进行动项有人跟踪——这些恰好是ITSM平台最擅长做的事。
ServiceDesk Plus 将灾备响应预案、关键资产信息、演练管理和改进跟踪整合在统一平台,让灾备建设不再是独立于日常IT运营的一次性文档项目,而是随IT环境变化持续演进的真实能力。如果你的灾备计划还在文档里,今天是开始改变的好时机——从做一次真实的BIA开始。
立即体验 ServiceDesk Plus,让灾备能力从文档走向真实可用
| ☁️ 免费注册云版本 | 💻 下载本地版 | 📅 预约专家演示 |
常见问题解答(FAQ)
延伸阅读:
