数字韧性运营:构建抗冲击、可持续的企业服务中枢



一、什么是“数字韧性运营”?
在企业全面数字化之后,IT 已经不再只是支撑系统运行的后台部门,而是业务连续性、客户体验与品牌信誉的核心保障。 这意味着组织必须构建一种能够抵御冲击、快速恢复并持续优化的运营体系。 这种体系的基础,往往建立在成熟的 IT 服务管理、 标准化的 ITIL流程, 以及统一的 ServiceDesk Plus 平台能力之上。
数字韧性运营的目标,并不是让系统永不出错,而是确保: 出现异常时能够被迅速发现; 影响范围被快速评估; 处置流程被自动触发; 沟通机制保持透明; 经验被沉淀为可复用的知识。
二、传统 IT 运维模式为何缺乏韧性?
在很多企业中,运维仍然以“人工响应 + 经验判断”为主。 当异常发生时,团队通过邮件、微信群、临时会议进行协调, 直到有人定位到根因,才逐步恢复。 这种模式的核心问题在于:高度依赖个人经验,缺乏系统化编排。
- 故障定位依赖个人知识
- 跨部门沟通缺乏统一平台
- 问题记录与知识沉淀脱节
- 风险无法提前预测
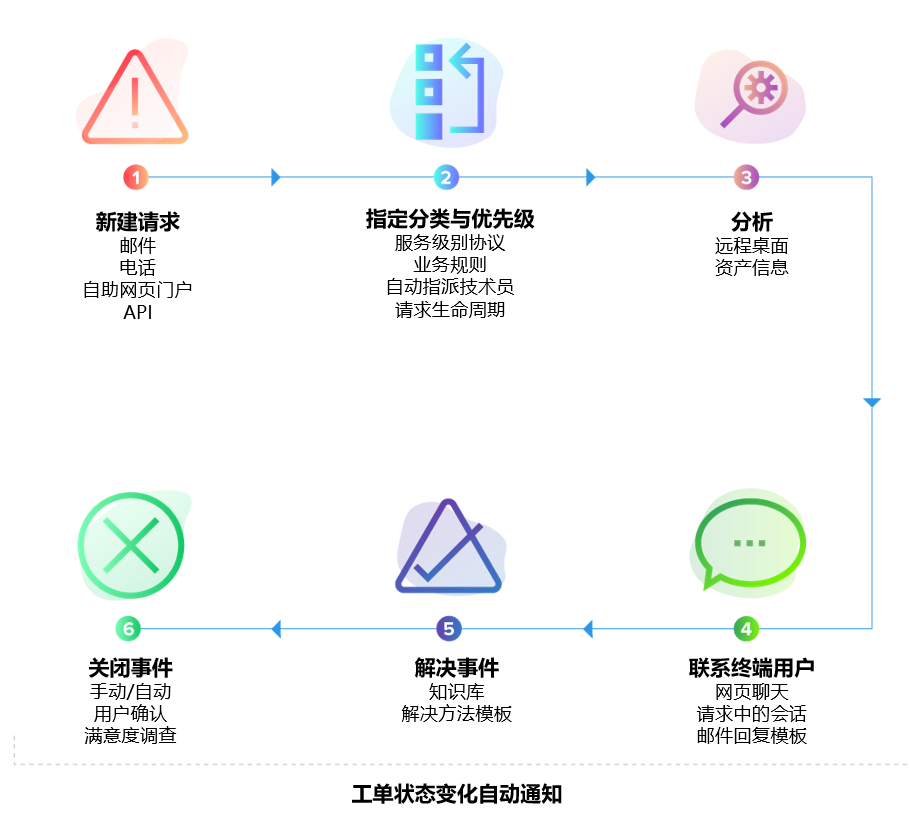
三、数字韧性运营的三大支柱
1)结构化事件管理体系
成熟的事件管理体系要求: 每一个异常都必须被记录; 每一次升级都必须有依据; 每一个解决方案都必须沉淀为知识。 这不仅是流程合规问题,更是韧性构建的基础。
2)可视化指标体系
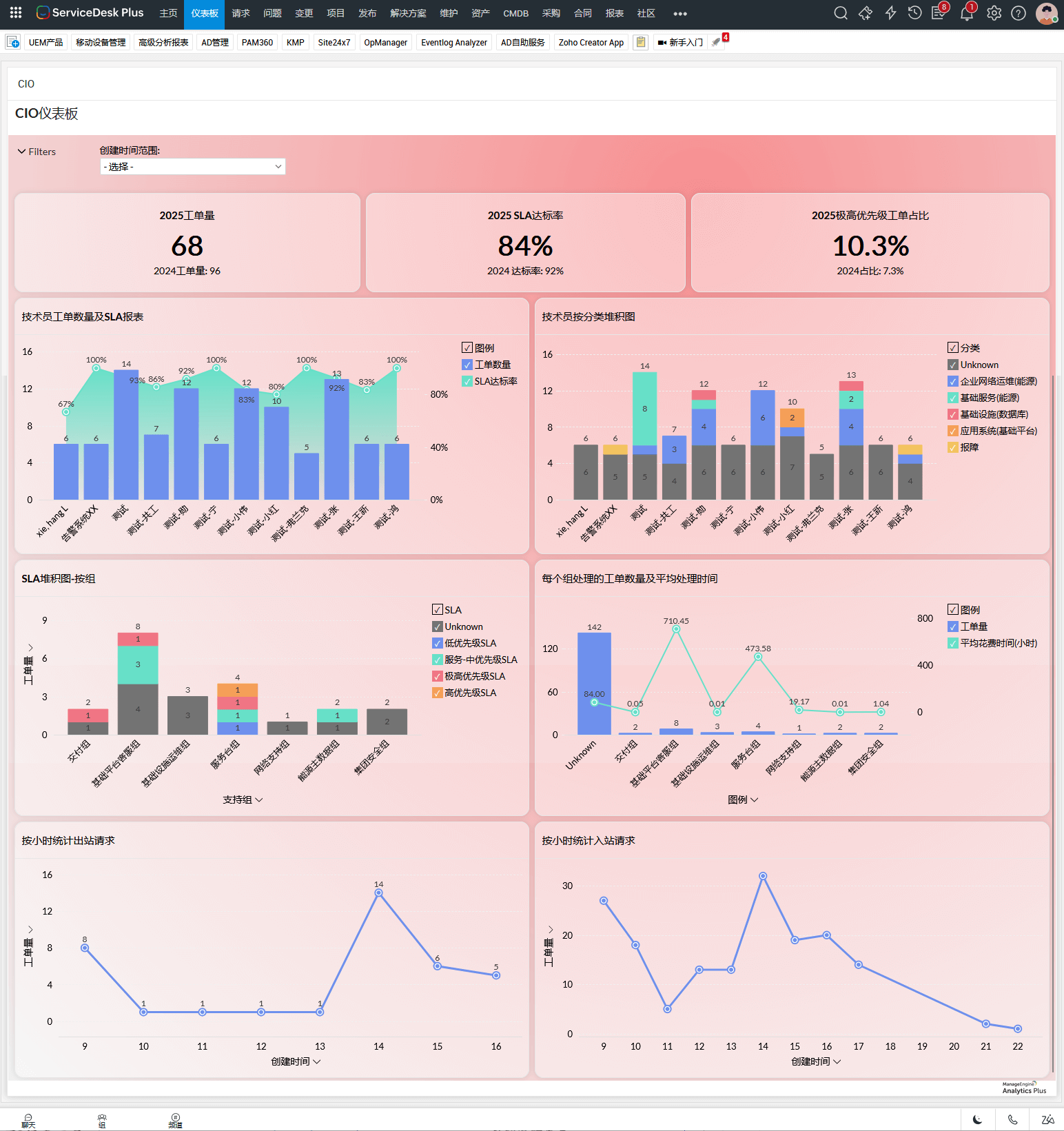
韧性不是口号,而是可度量的能力。 建议企业至少监控以下指标: 平均恢复时间(MTTR)、 首次解决率、 SLA 达成率、 重大事件频率、 自动化覆盖率。
3)自动化与预警机制
真正的韧性来自“提前发现问题”, 而不是“快速救火”。 自动化告警、规则触发、风险分析模型, 能够让企业在异常扩大之前进行干预。
下一部分,我们将深入拆解: 如何用流程编排、低代码能力与跨系统集成, 构建真正具备抗冲击能力的企业服务中枢。
四、抗冲击架构模型:从“响应型”走向“预防型”
数字韧性运营的核心不在于“故障处理速度”, 而在于构建一套能够识别冲击、缓冲冲击、恢复冲击并持续优化的服务架构。 我们可以将其拆解为四层模型:
- 监测层:实时收集系统与业务信号
- 判断层:基于规则或模型评估影响范围
- 执行层:自动触发标准化处置流程
- 复盘层:沉淀知识并优化规则
在传统模式下,这四个步骤往往由不同团队分别完成, 且缺乏统一视图。结果就是响应时间长、沟通成本高、重复劳动严重。
五、风险分级与响应矩阵设计方法
企业在重大异常面前容易出现两种极端: 要么所有问题都被当作“重大事件”处理, 要么真正的重大事件被低估。 因此,建立分级矩阵至关重要。
1)影响维度
- 用户数量
- 业务中断时间
- 收入影响
- 合规风险
2)响应级别
- P1:跨部门响应,启动应急机制
- P2:技术负责人主导
- P3:标准流程处置
分级矩阵必须提前定义, 而不是在事故发生时临时讨论。
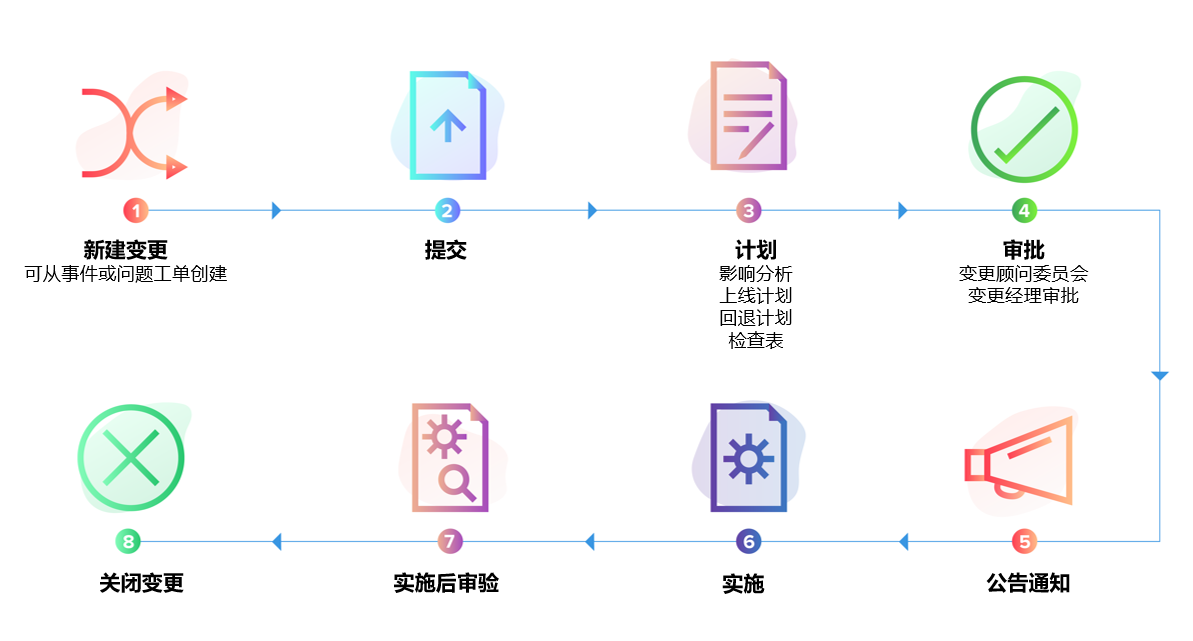
六、跨部门响应编排逻辑
数字韧性运营强调“编排”而非“通知”。 通知只是告诉别人发生了什么, 编排则是自动创建任务、分配角色、追踪状态并确保闭环。
例如,当核心数据库异常触发 P1 事件时:
- 自动创建重大事件记录
- 通知值班工程师与业务负责人
- 生成沟通公告草稿
- 启动回滚或备份校验流程
七、行业案例解析
案例一:制造企业的产线中断
某大型制造企业在 ERP 升级后, 出现库存同步异常。 若未及时处理,将影响产线调度。 通过标准化事件管理与自动化编排, 在 40 分钟内完成回滚与通知, 避免数百万损失。
案例二:金融行业核心系统异常
某金融机构通过监控系统识别交易延迟异常, 自动升级为 P1。 同时自动生成监管报告草稿, 保障合规响应时效。
案例三:连锁零售 POS 故障
在 300+ 门店同时出现支付延迟时, 自动聚类为单一重大事件, 避免 300 张重复工单。 统一公告,稳定客户预期。
八、自动化成熟度模型
企业自动化能力可分为四级:
- Level 1:人工响应为主
- Level 2:规则触发自动化
- Level 3:跨系统流程编排
- Level 4:预测与自愈能力
多数企业停留在 Level 2, 而真正的数字韧性往往建立在 Level 3 以上。
下一部分将进入最终章节: 从治理机制、智能升级路径到 FAQ 与 CTA, 形成完整闭环。
九、组织治理模型:韧性不是技术问题,而是结构问题
数字韧性运营的长期成功,离不开明确的组织治理结构。 如果事件管理与服务编排仅停留在技术层面, 那么随着人员变化和组织扩张,体系将逐渐失效。
1)服务治理委员会
由 IT、业务、合规及运营负责人组成, 负责重大服务目录变更、SLA 策略调整、 以及跨部门响应机制优化。
2)流程负责人(Process Owner)
每一个核心流程必须有明确负责人, 包括事件管理、问题管理、变更管理、 重大事件响应、知识库治理等。
十、智能升级路径:从自动化到预测与自愈
数字韧性并不是一次性建设完成。 它需要持续升级,从基础自动化走向预测与自愈。
阶段一:规则自动化
基于预定义规则触发通知、升级与分派。
阶段二:跨系统编排
自动联动监控平台、身份系统、 变更记录与知识库,实现联动响应。
阶段三:预测与异常检测
利用历史数据与模式识别, 在问题扩大之前触发干预。
阶段四:自愈能力
自动执行标准修复脚本, 如重启服务、回滚版本、恢复备份。
韧性运营长期指标体系
建议企业建立季度复盘机制, 关注以下长期指标:
- 重大事件数量趋势
- 自动化覆盖率
- 知识复用率
- 变更失败率
- 恢复时间趋势
未来趋势:从服务台到企业服务中枢
随着业务复杂度提升, 企业将不再区分“IT 服务”与“业务支持”, 而是构建统一的服务中枢。 数字韧性运营,将成为企业核心竞争力的一部分。
常见问题
Q1:数字韧性是否等同于灾备?
不是。灾备是恢复能力的一部分, 而数字韧性包括预防、检测、响应与优化全周期。
Q2:中型企业是否需要完整韧性模型?
建议从关键流程开始逐步推进, 不必一次性覆盖全部场景。
Q3:如何衡量投资回报?
可通过减少停机时间、提升满意度、 降低返工率进行量化。
Q4:是否必须引入 AI 才能实现韧性?
AI 可以加速成熟度提升, 但基础流程治理同样重要。
立即行动
构建数字韧性运营体系, 从统一服务平台与标准流程开始。 让企业在面对不确定性时依然保持稳定与高效。
