AIOps 驱动的服务可靠性体系:构建可预测、可恢复、可演进的 ITSM 架构



当企业的业务体验直接依赖数字基础设施时,“稳定性”不再只是 IT 的内部 KPI,而是整个公司的市场竞争力。无论是零售的秒级支付、制造的自动化生产、金融的合规要求,还是企业内部的服务交付,都在逼迫 IT 团队构建更加智能、可预测、可恢复的服务体系。
然而,今天的 IT 环境却比以往更加复杂:微服务架构、多云部署、边缘节点、远程用户、第三方 SaaS,以及成倍增加的日志、事件和告警。这让传统的 ITSM + 人工排查模式迅速失效,响应延迟、误报、根因难查、跨团队协作困难等问题愈发显著。
企业需要的不只是更快的工单处理,而是一个能够 预测风险、主动发现异常、自动化处置并持续提升稳定性 的体系。这正是 AIOps(Artificial Intelligence for IT Operations) 与现代 ITSM 深度融合后的价值所在。
作为领先的 IT 服务管理平台,ManageEngine ServiceDesk Plus 正在从传统工单系统向 “智能稳定性引擎” 加速演进,通过 AI 驱动事件降噪、智能关联分析、异常预测、根因建议、自动化修复、跨系统协作等能力,为企业构建下一代服务可靠性体系提供底座。
本文将从 AIOps 的五大能力模型出发,系统解析企业如何利用 SDP 构建以稳定性为核心的服务体系,帮助你的团队从“救火模式”升级为“预测与预防模式”,从被动响应走向主动治理,从流程驱动转向智能驱动。
AIOps 的五大核心能力:稳定性的智能化底座
AIOps 并不是一个单一技术,而是一套能力体系。企业在落实 AIOps 时,并不需要“一步到位”,而是围绕五大关键能力逐步构建可演进的稳定性体系。本章将拆解这五层能力,并对应 ServiceDesk Plus 的落地方式。
01. 感知 —— 数据采集与告警降噪
在现代 IT 环境中,企业每天要处理的信号量巨大:监控告警、日志、流量、调用链信息、设备状态等。传统做法是“告警来了就处理”,导致团队被噪声淹没。AIOps 的第一步,就是将所有运行数据统一汇聚,并通过算法消除冗余告警,让 IT 团队只关注真正重要的信号。
当 ServiceDesk Plus 与企业监控平台、日志平台整合后,系统可自动将告警转为工单,去重、合并具有相同根因的事件,并通过智能分类模型标注标签。对于大量重复发生的告警,系统会自动识别模式并建议规则,帮助团队持续降低噪声水平。
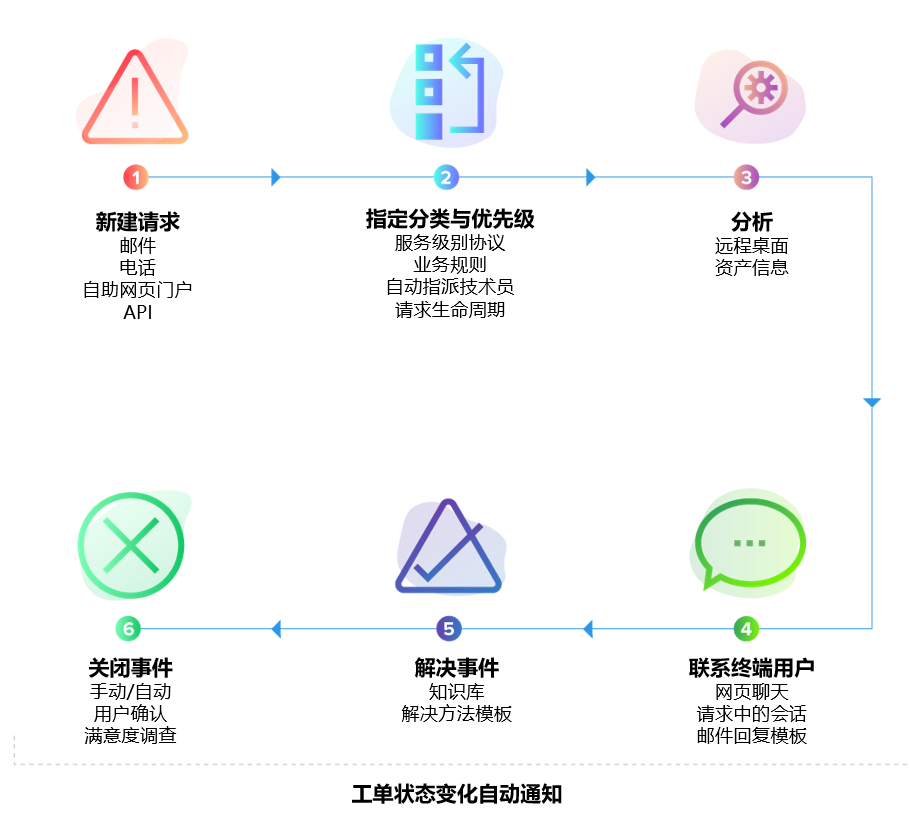
02. 关联 —— 智能事件归并与根因线索
事件之间并非孤立。一次服务中断,往往源自多个系统同时出现异常。AIOps 的第二层能力是关联分析:通过拓扑结构、变更日志、时间线、CI 关系等数据找出“真正的关键点”。这一步极大提高了故障定位效率,减少无效排查。
SDP 与 CMDB 整合后能够自动展示受影响的资源链路。若某一网络节点宕机、数据库压力过高或应用实例崩溃,系统会自动提示可能的根因,并给予问题建议或知识文档,提高工程师排查效率。
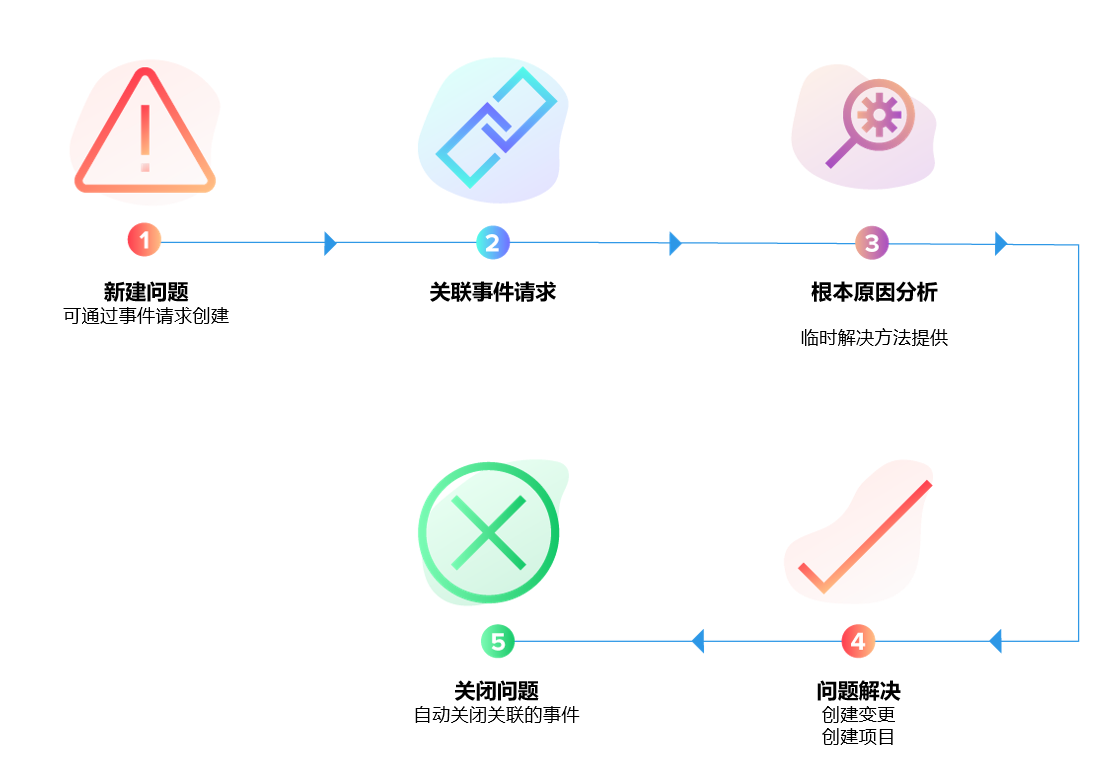
03. 决策 —— 从预测到自动化补救
当系统真正“学会”事件背后的运行规律后,就能基于趋势预测风险。AIOps 的第三层能力是智能决策:系统能主动判断某项指标是否即将超出阈值,并给出预测性告警,阻止事件发生。
在 ServiceDesk Plus 中,这些预测结果可自动转为变更请求、自动化脚本任务或自动修复流程。例如:
- 检测到磁盘增长趋势后自动清理缓存。
- 预测数据库 CPU 即将飙升时提前扩容资源。
- 发现服务延迟上升时自动重启实例。
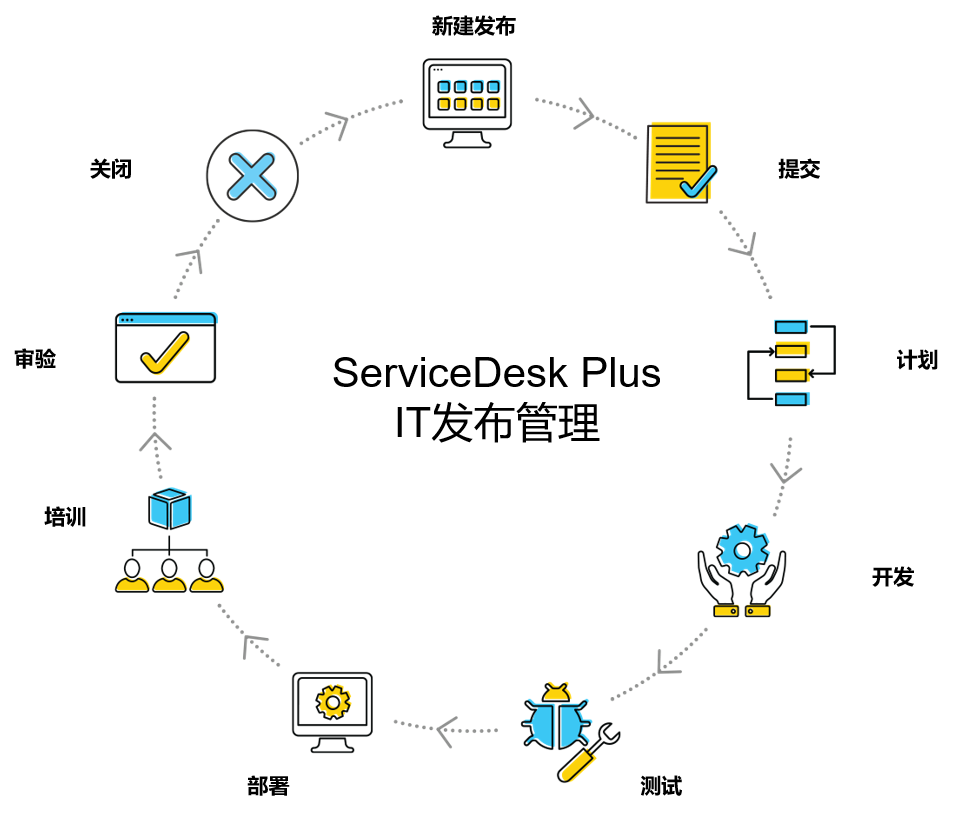
04. 执行 —— 自动化编排与跨系统联动
当企业 IT 生态越来越丰富时,运维操作往往会涉及多个平台:监控、CMDB、工单系统、部署工具、云平台等。AIOps 的第四层能力是自动化编排,让不同系统之间协同运行,减少人工干预。
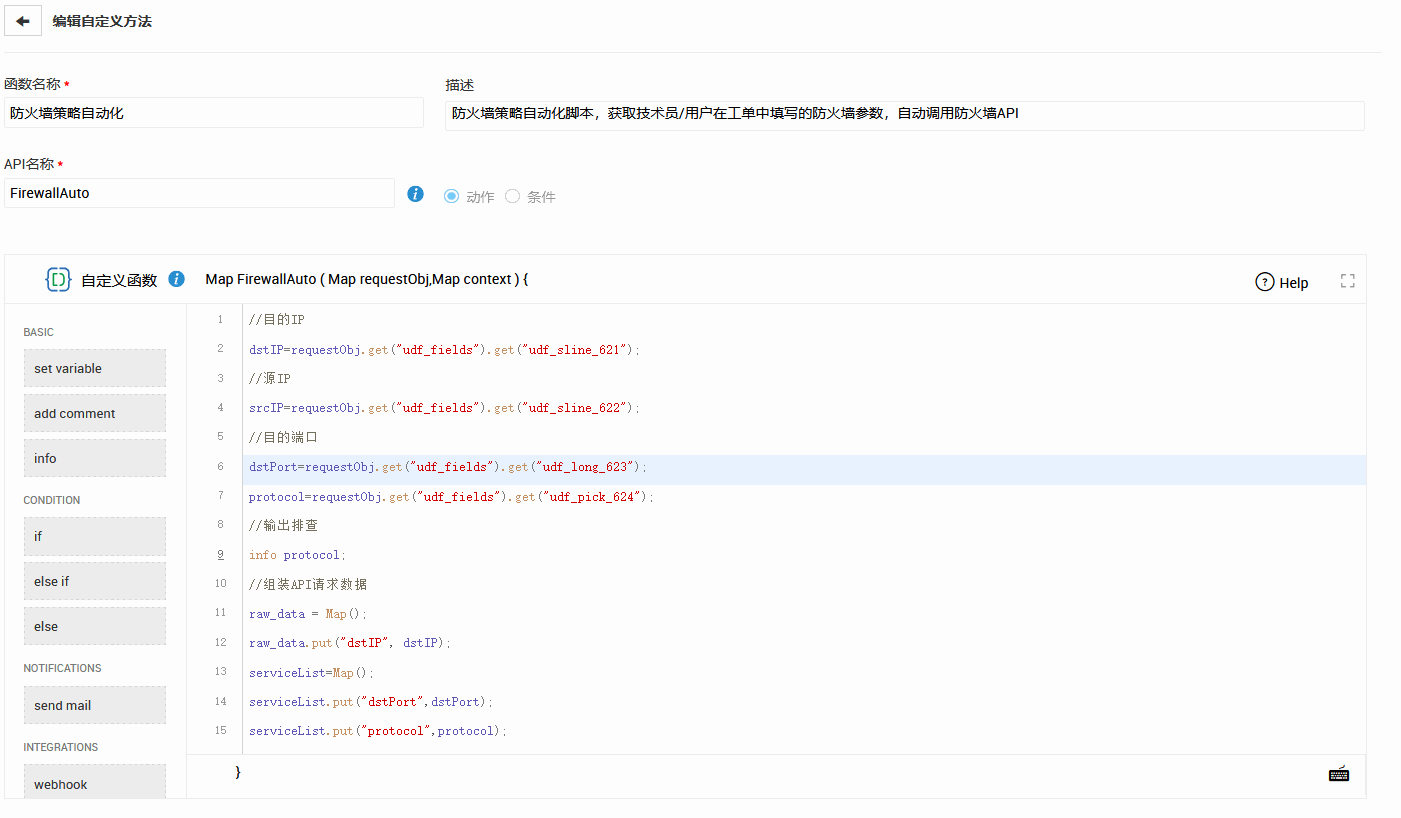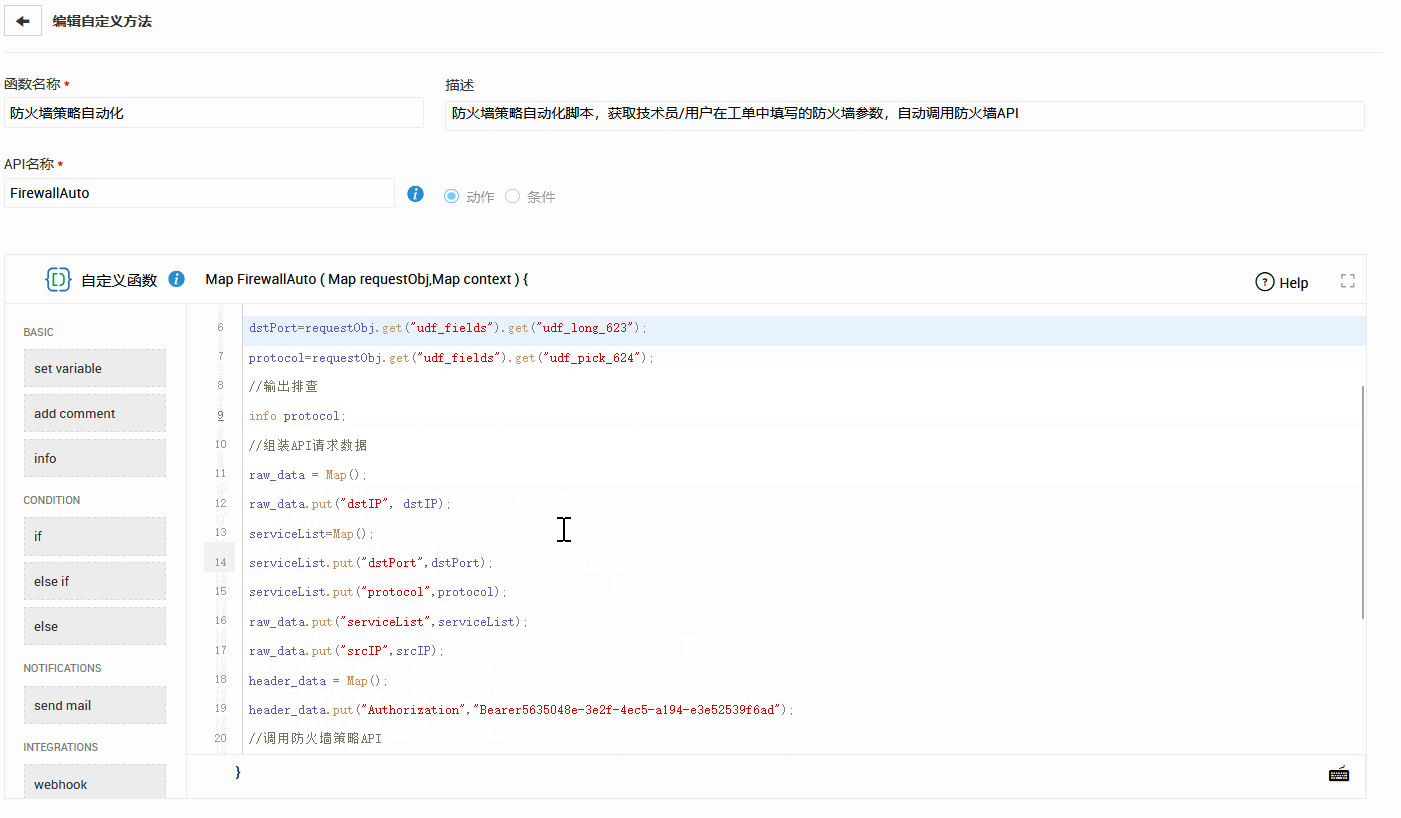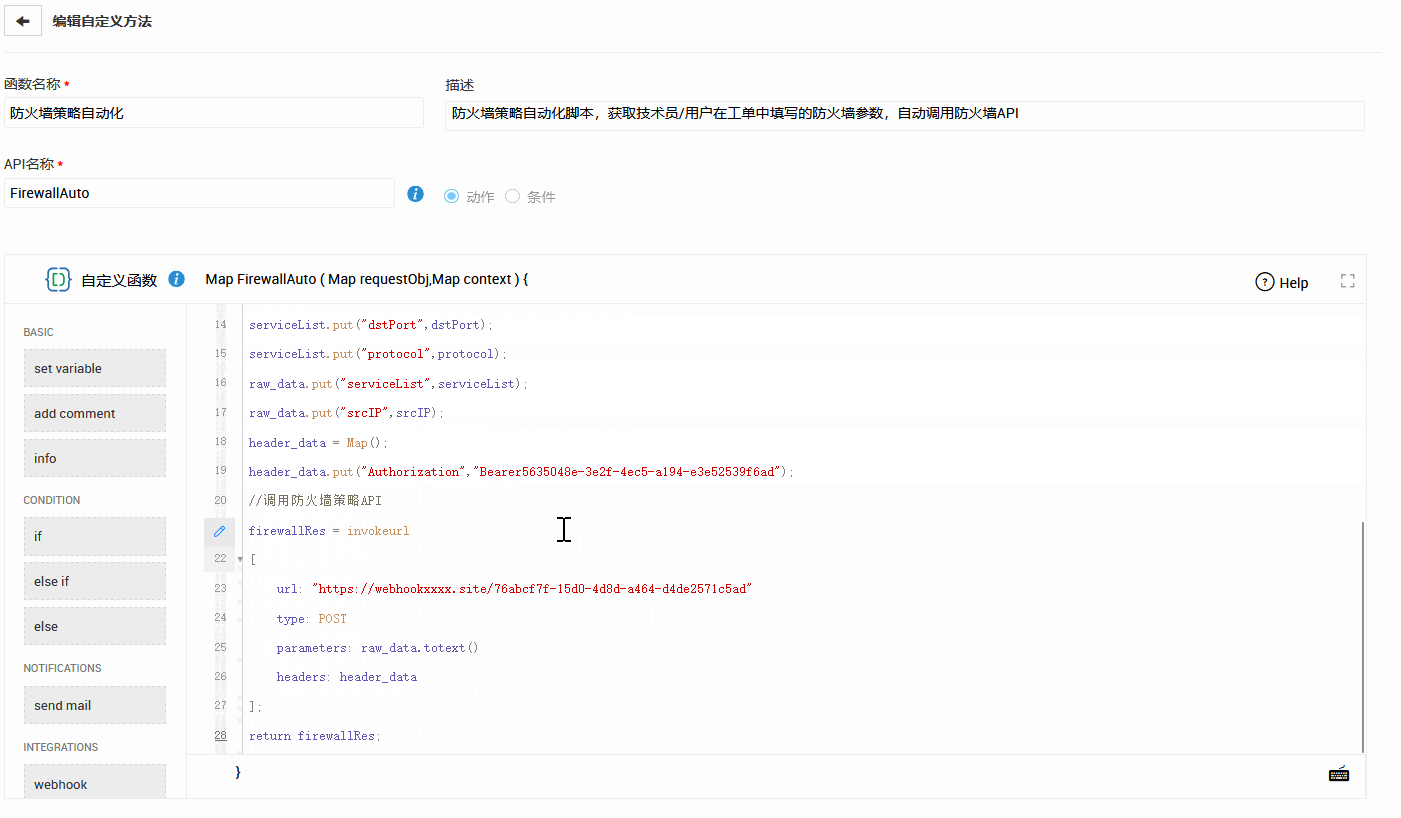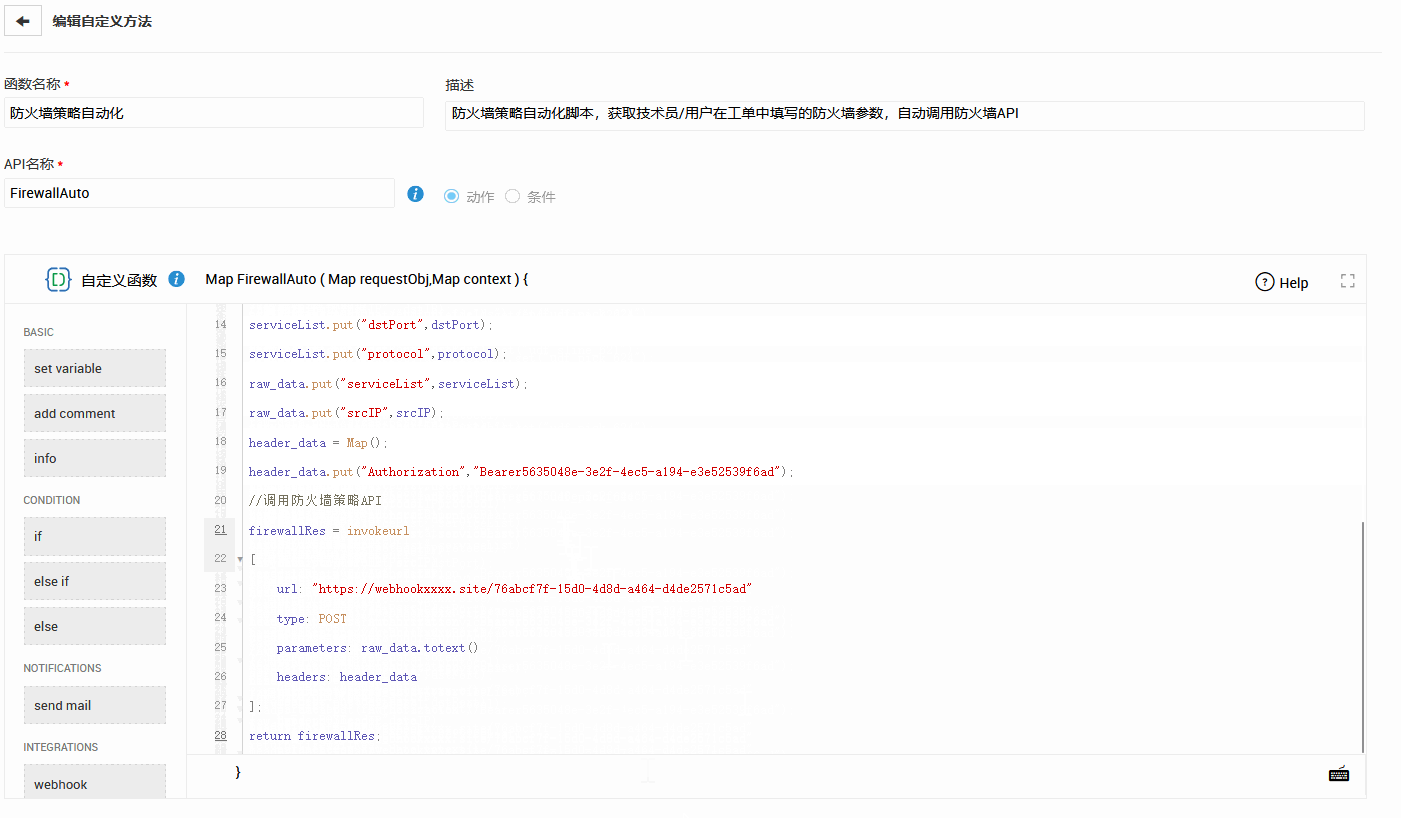
SDP 的低代码自动化 + Webhook + 自定义函数 + API 集成,使得跨平台修复流程得以快速搭建。例如:
- 监控平台告警 → 自动生成工单 → 自动关联 CMDB → 自动派单。
- 自动化脚本根据规则在后端执行修复动作。
- 修复结果回写至工单、知识库和 SLA 报表。
05. 学习 —— 持续优化与稳定性治理
AIOps 的最终目标不是“自动化越多越好”,而是让系统不断学习事件规律与业务模式,从而实现服务交付的持续优化。这包括:
- 分析常见故障模式并推动结构化问题管理。
- 识别高风险变更并建议审批策略。
- 基于用户体验指数(XLA)持续调整资源与流程。
这五大能力结合起来,构成现代稳定性体系的基本框架。下一章,我们将进一步拆解 ServiceDesk Plus 如何作为“稳定性中枢”落地这些能力。
ServiceDesk Plus:从 ITSM 平台到稳定性指挥中心
传统 ITSM 主要关注流程和工单,而现代企业需要的是“自动驾驶式的服务运营”。SDP 在体系化、智能化和跨系统能力上持续强化,为企业稳定性提供可观测、可治理与可演进的底座。
1. 统一事件收敛与跨平台集成能力
SDP 与监控系统(Zabbix、Nagios、Datadog 等)、日志平台、APM 工具深度集成,可将告警转为标准化事件工单,并能自动归并重复告警、为事件添加风险标签、提取关键字段,为根因分析打下基础。
2. 与 CMDB 联动,实现依赖关系可视化
SDP 的 CMDB 可帮助企业构建从基础设施到业务服务的拓扑结构。当事件发生时,系统会自动展示受影响的 CI、服务路径、最近变更等,使工程师能够快速抓住关键点。
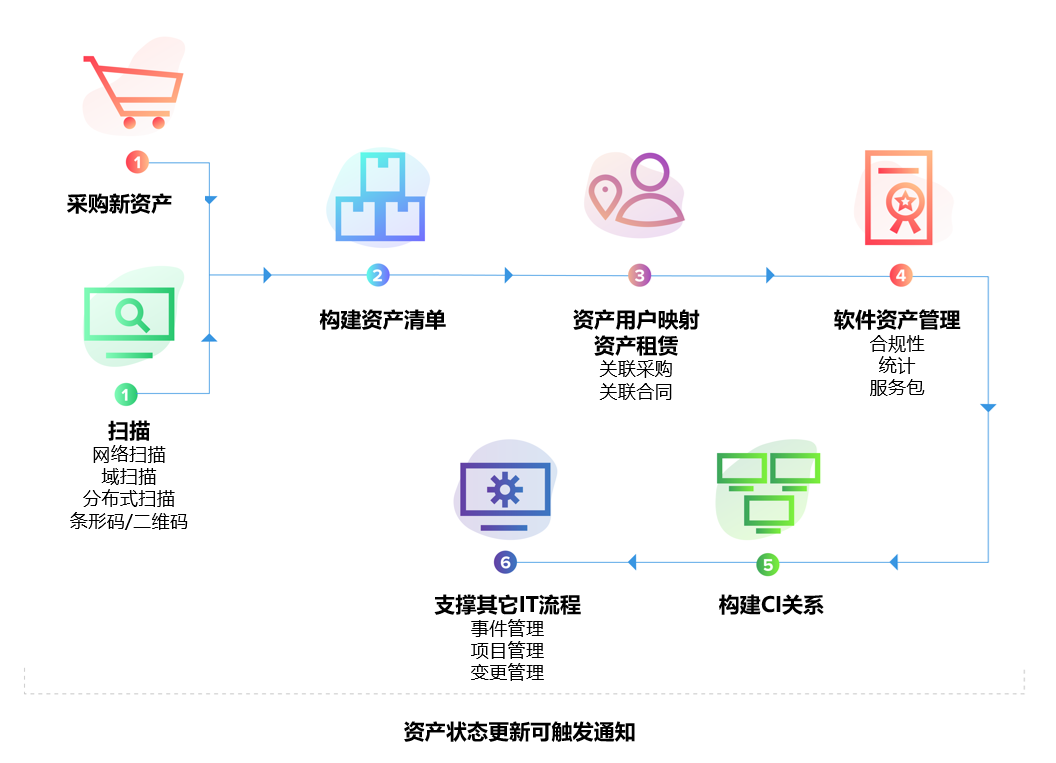
3. 场景化自动化修复能力
结合自动化规则、脚本执行、自定义函数,SDP 可以在事件初期就自动采取补救措施。例如:
- 磁盘满 → 自动清理日志。
- 服务无响应 → 自动重启。
- 网站延迟升高 → 自动扩容。
4. 稳定性指标体系(SLO / XLA / MTTR)可视化
SDP 内建的报表引擎可实时展示事件趋势、SLA 违约率、工单响应速度、问题根因分布等指标,让管理者能够根据数据调整策略,而非凭经验判断。
企业落地 AIOps 的四步路线图
企业通常不可能一次性“全量部署” AIOps,而是按照业务成熟度逐步建设。以下路线图适用于 90% 的企业。
第一步:从告警自动化开始(降噪 → 合并 → 标准化)
通过 SDP + 监控平台集成,将告警自动化转工单并去重、合并,这是 AIOps 的基础。
第二步:构建 CMDB 与事件关联能力
当 CMDB 建好后,事件分析能力会提升多个维度,为根因定位与自动化修复奠定基础。
第三步:自动化修复与脚本编排
这是 AIOps 的核心阶段。大量重复性操作可由系统自动完成,使工程师专注于真正复杂的工作。
第四步:建立稳定性运营体系(SLO / 问题管理 / 趋势分析)
最终,企业将进入“治理阶段”,从大量历史数据中提取模式,通过问题管理、错误库、XLA 指标等,建立可持续优化的体系。
行业案例:AIOps 如何真正提升企业稳定性
金融行业:从分钟级故障恢复到秒级自动修复
客户银行通过 SDP 的自动修复能力,将支付系统的常见故障恢复速度从“人工 5 分钟”下降到“自动 10 秒”,极大减少了交易失败率。
零售行业:多门店系统健康度实时监控
SDP 自动监控 800+ 门店 POS 设备,异常时自动提醒并创建工单,避免人工排查带来的时间成本。
制造行业:预测性维护减少 40% 停机时间
基于 SDP + 监控平台的趋势分析,制造业设备故障可提前 24 小时预测,使企业将停机时长减少近一半。
常见问题
1. AIOps 与传统 ITSM 有什么区别?
ITSM 强调流程,而 AIOps 注重数据驱动和自动化能力,两者结合能显著提高响应速度与问题定位效率。
2. 是否必须拥有 CMDB 才能使用 AIOps?
不是,但 CMDB 能极大增强事件分析能力,因此建议逐步构建 CMDB。
3. 自动化修复是否存在风险?
自动化修复支持审批与多级验证,可确保执行安全可靠。
4. AIOps 是否适合中小型企业?
非常适合。即便从简单降噪开始,也能显著提升效率。
