新功能!OpManager 支持 Nvidia GPU 监控,打造统一企业算力监控平台
AI 摘要
OpManager 最新版本新增 Nvidia GPU 监控功能,支持 Linux 环境下自动采集利用率、显存、温度、功耗等关键指标,告别手动 nvidia-smi 排查。通过统一平台实现 GPU 与网络、服务器、应用一体化监控,提供实时可视化、智能告警与趋势分析,帮助企业优化算力利用率,保障 AI 训练和高性能计算业务稳定运行,构建面向 AI 时代的智能运维体系。
随着人工智能、大模型训练、视频渲染和高性能计算(HPC)的快速发展,GPU 已逐渐成为企业 IT 基础设施中最重要的计算资源之一。从 AI 模型训练到数据分析,从智能视频处理到云计算平台,GPU 的稳定运行直接影响业务性能和计算效率。
然而,在许多企业环境中,GPU 运维仍然停留在较为传统的阶段。运维人员通常需要登录服务器,通过 nvidia-smi 命令手动查看 GPU 使用情况。这种方式虽然简单,但缺乏持续监控、历史数据和自动告警能力,难以满足企业级 IT 运维的需求。
如今,在最新版本的 OpManager 中,已经实现了对 Nvidia GPU 在 Linux 系统环境下的监控支持。OpManager 通过调用 nvidia-smi 命令自动采集 GPU 关键指标,并将 GPU 资源纳入统一监控平台,帮助企业实现 网络、服务器、应用与 GPU 算力资源的一体化监控管理。



为什么企业需要 GPU 监控?
在 AI 和数据密集型业务快速发展的背景下,GPU 已成为企业最核心、同时也是最昂贵的 IT 资源之一。企业如果缺乏有效的 GPU 监控能力,将面临多种运维挑战,例如:
- GPU 利用率过低导致算力资源浪费
- GPU 长时间满载影响业务性能
- GPU 温度过高导致降频或设备损坏
- 显存耗尽导致 AI 训练任务失败
- GPU 节点故障影响计算集群稳定性
对于 AI 训练或大规模计算任务来说,一个 GPU 节点的异常可能导致整个任务失败,甚至浪费数小时甚至数天的计算资源。因此,企业需要具备 持续、自动化、可视化的 GPU 监控能力,以确保算力资源稳定、高效运行。
传统 GPU 运维方式的局限
在缺乏专业 GPU 监控工具的情况下,企业运维团队通常采用手动方式管理 GPU:
- 登录服务器
- 执行 nvidia-smi 命令
- 查看 GPU 使用情况
- 手动记录或排查问题
虽然这种方式可以获取 GPU 当前状态,但在企业规模环境中存在明显局限。
| 运维挑战 | 具体表现 |
|---|---|
| 无持续监控 | 只能看到当前 GPU 状态 |
| 无历史数据 | 无法分析 GPU 使用趋势 |
| 无自动告警 | GPU 故障无法提前发现 |
| GPU 集群难管理 | 多服务器环境复杂 |
| 运维效率低 | 需要逐台服务器排查 |
随着企业 GPU 服务器数量不断增加,这种方式不仅效率低下,还容易导致运维风险。
OpManager 的 GPU 监控能力
通过 OpManager,企业可以将 GPU 纳入统一监控体系,实现集中化管理。
OpManager 通过 Linux 系统中的 nvidia-smi 命令自动采集 GPU 关键性能指标,包括:
GPU 状态指标
- GPU 可用性
- GPU 计算模式
- GPU 显示状态
- GPU 持久模式
GPU 性能指标
- GPU 利用率
- GPU 显存利用率
- GPU 温度(摄氏度)
- GPU 功耗(瓦特)
- GPU 功耗百分比
- GPU 风扇转速百分比
- GPU 核心时钟频率百分比
- GPU 显存时钟频率百分比
这些监控数据会在 OpManager 的可视化界面中以 仪表盘、趋势图和报表的形式呈现,使运维人员能够实时掌握 GPU 资源状态。在 OpManager 产品 AIOps 路线图中,已经纳入更多的 GPU 监控指标,以及基于监控数据做进一步智能分析的开发计划。
OpManager GPU 监控的核心优势
统一 IT 基础设施监控
OpManager 不仅能够监控 GPU,还可以统一管理整个 IT 基础设施,包括:
- 网络设备(交换机、路由器)
- Linux / Windows 服务器监控
- 虚拟化环境
- 应用服务
- GPU 计算资源
通过统一监控平台,企业可以实现 从网络到应用再到算力资源的端到端可视化运维。
例如,当 GPU 利用率异常时,运维人员可以同时查看:
- 服务器 CPU 使用率
- 内存使用情况
- 网络流量
- 应用性能指标
从而快速定位问题。
自动发现 GPU 设备
在 OpManager 中,当 Linux 服务器被添加到监控系统后,系统即可自动识别 GPU 设备并采集相关指标。
运维人员无需:
- 手动编写监控脚本
- 部署复杂监控工具
- 构建额外的监控架构
即可实现 GPU 监控。
这一能力特别适合 AI 服务器、GPU 集群以及数据中心算力环境。
GPU 实时性能可视化
OpManager 提供直观的 GPU 性能监控图表,例如:
- GPU 利用率趋势图
- GPU 显存使用趋势
- GPU 温度变化
- GPU 功耗趋势
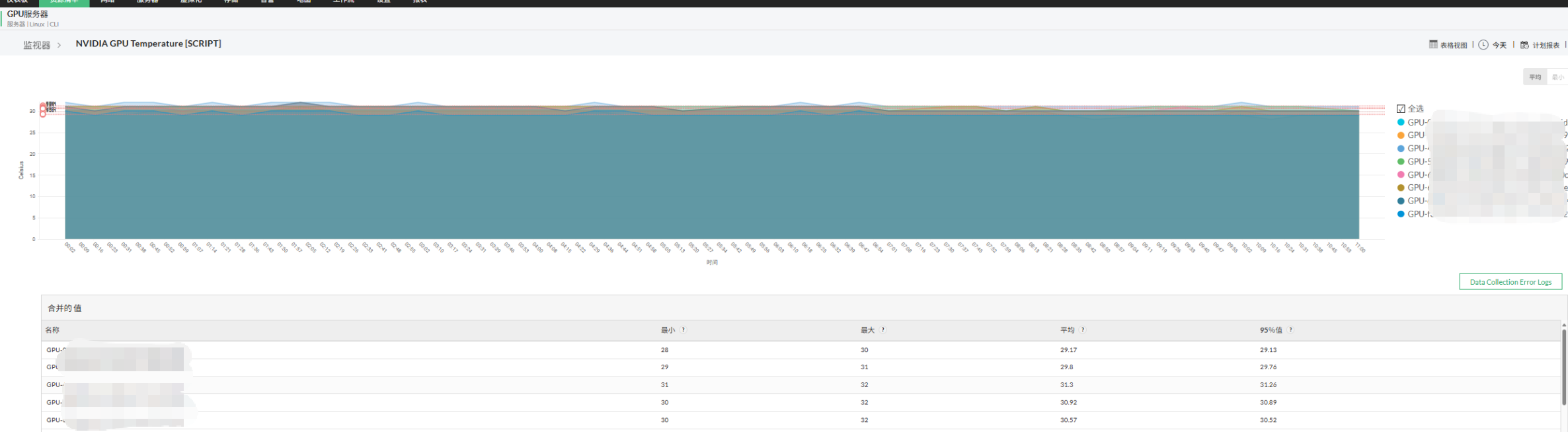
通过这些可视化数据,运维团队可以:
- 快速识别算力瓶颈
- 分析 GPU 使用模式
- 优化 AI 计算任务调度
在 AI 和高性能计算环境中,这些数据对于 算力规划与性能优化至关重要。
GPU 异常自动告警
OpManager 支持基于阈值的 GPU 告警策略,例如:
| GPU 指标 | 告警场景 |
|---|---|
| GPU 利用率 | 长期 0%(资源闲置) |
| GPU 利用率 | 长期高于 90%(过载风险) |
| GPU 温度 | 超过安全阈值 |
| 显存使用率 | 接近满载 |
| GPU 功耗 | 异常波动 |

当 GPU 指标出现异常时,OpManager 可以通过以下方式通知运维团队:
- 邮件通知
- Webhook 集成
- 自动工单
- 自动化运维脚本
这意味着 GPU 故障可以 在业务受到影响之前被及时发现和处理。
GPU 资源利用率优化
GPU 是企业 IT 成本最高的资源之一。如果 GPU 长时间处于低利用率状态,将导致算力浪费。
通过 OpManager 的历史趋势分析和报表功能,企业可以:
- 识别闲置 GPU
- 分析 GPU 使用趋势
- 优化计算任务调度
- 制定 GPU 扩容策略
从而实现 算力资源的最大化利用。
使用 OpManager 与传统 GPU 运维方式对比
| 运维能力 | 传统 GPU 运维 | 使用 OpManager |
|---|---|---|
| GPU 状态查看 | 手动执行 nvidia-smi | 自动实时监控 |
| GPU 数据记录 | 无历史数据 | 趋势分析 |
| GPU 故障发现 | 用户投诉后 | 自动告警 |
| GPU 集群管理 | 人工管理 | 集中管理 |
| 运维效率 | 低 | 自动化 |
| GPU 利用率优化 | 难以评估 | 可视化分析 |
可以看到,OpManager 将 GPU 运维从 人工排查模式升级为智能监控模式。
为企业 IT 运维带来的价值
部署 OpManager GPU 监控能力后,企业可以获得多方面收益:
提升运维效率
- 减少 SSH 登录排查
- 自动采集 GPU 指标
- 自动异常告警
提高 AI / GPU 业务稳定性
及时发现:
- GPU 过热
- GPU 故障
- 显存耗尽
避免计算任务中断。
提升 GPU 利用率
通过趋势分析:
- 识别闲置算力
- 优化资源调度
降低运维复杂度
通过统一平台监控:
- 网络设备
- 服务器
- GPU
- 应用系统
减少多工具运维带来的复杂性。
构建面向 AI 时代的统一运维平台
随着 AI 和数据密集型应用不断增长,GPU 将在企业 IT 架构中扮演越来越重要的角色。传统依赖手动命令的 GPU 运维方式已经无法满足现代数据中心的需求。
借助 OpManager 的 GPU 监控能力,企业可以实现:
- GPU 实时监控
- GPU 异常告警
- GPU 性能趋势分析
- GPU 集群集中管理
从而打造 更加智能、自动化、高效的企业级 IT 运维体系,为 AI 计算和数字化业务提供稳定可靠的算力基础。
互动话题
你的企业是否也经历过因网络中断导致的重大损失?你是如何从被动救火转向主动预防的?欢迎分享你的故事。
想亲身体验OpManager如何引领智能运维新纪元?它支持30天免费试用(全功能开放),现有用户更新到最新版本即可使用;还能预约1对1演示,看看如何为你的企业构建智能网络监控体系~
- 即刻开始体验!免费下载安装并享30天全功能开放!
- 需要深入交流?预约产品专家一对一定制化演示!
- 获取报价?填写信息获取官方专属报价!
- 想了解更多?点击进入OpManager官网并查看更多内容!
- 倾向云版本?Site24*7云上一体化解决方案!
常见问题(FAQs)
- OpManager 的 GPU 监控支持哪些环境?
答:目前支持 Linux 系统下的 Nvidia GPU,通过 nvidia-smi 命令自动采集指标。未来将扩展更多 GPU 类型和操作系统。
- OpManager 可以监控哪些 GPU 关键指标?
答:包括 GPU 利用率、显存利用率、温度、功耗、风扇转速、核心/显存时钟频率,以及可用性、计算模式等状态指标。
- 传统 GPU 运维方式有哪些弊端?
答:依赖手动登录执行 nvidia-smi,无持续监控和历史数据,无法自动告警,多服务器管理困难,故障发现滞后,容易导致算力浪费或业务中断。
- OpManager 的 GPU 监控如何帮助企业优化算力?
答:通过趋势分析和可视化报表,识别闲置 GPU、分析使用模式、优化任务调度,并支持基于阈值的告警,避免过载或故障,最大化 GPU 资源利用率。
- OpManager 的 GPU 监控是否需要额外配置?
答:无需手动脚本。只需将 Linux 服务器加入 OpManager 监控,系统自动发现 GPU 并开始采集指标,实现即插即用式监控。



