Gartner 预测 AIOps 爆发,企业为什么更需要一体化网络监控工具?
AI 摘要
Gartner预测AIOps将爆发,超60%企业将其作为核心运维战略。混合云、SD-WAN、远程办公使网络复杂度激增,传统监控工具难以应对。OpManager作为一体化网络监控平台,提供自动发现、网络可视化、多维度性能监控、智能告警与根因分析,帮助企业实现混合云统一监控与可观测性。相比Nagios、Zabbix等工具,OpManager具备开箱即用、拓扑感知、低运维成本等优势,是构建现代化智能运维体系的核心选择。
OpManager 正在成为越来越多企业构建现代化 IT 运维体系的重要平台。随着 AIOps、混合云、远程办公以及零信任架构的快速普及,传统依赖人工巡检和分散工具的运维模式已经难以满足复杂网络环境的需求。尤其是在 Gartner 预测到 2026 年超过 60% 的大中型企业将把 AIOps 作为核心运维战略的背景下,企业对于“统一可视化、智能告警、根本原因分析”的需求正在迅速增长。
与此同时,据 SolarWinds 2026 年监测与可观测性报告显示,77% 的 IT 团队在混合环境中缺乏完整的端到端可见性。这意味着,越来越多的企业正在面临这样一个现实:网络设备越来越多,云资源越来越复杂,但运维团队却无法快速知道“问题在哪里、为什么发生、影响范围有多大”。
在这样的趋势下,现代化网络监控工具不仅需要“看见故障”,更需要帮助运维团队理解故障背后的关联关系。这正是 OpManager 在当前 IT 运维环境中的核心价值。



传统 IT 运维为什么越来越难?
混合云与多云架构让网络复杂度激增
过去,大部分企业网络都集中在本地数据中心,监控对象相对固定。但如今,大量企业已经同时使用 AWS、Azure、本地虚拟化平台以及 SaaS 服务,形成典型的混合 IT 架构。
这种变化直接带来了三个问题:
- 网络边界消失
- 运维数据来源碎片化
- 故障定位时间不断增加
Gartner 指出,可观测性已经超越传统监控模式。传统监控更多关注“设备是否在线”,而现代可观测性更强调通过 Metrics、Logs、Traces 与拓扑关系理解“为什么会出问题”。
对于运维团队来说,仅仅依赖 Ping 或简单 SNMP 监控已经远远不够。
SD-WAN 与远程办公让链路监控压力暴增
Gartner 预测,到 2026 年,超过 60% 的企业将实施 SD-WAN,而 2021 年这一比例还不到 20%。
这意味着:
- 企业分支机构数量增加
- VPN 与互联网链路更加复杂
- 云边缘流量持续增长
- 用户访问路径更加动态
尤其是在远程办公常态化后,很多 IT 团队发现:
“总部网络没问题,但员工体验依然很差。”
原因往往来自:
- ISP 链路波动
- WAN 延迟增加
- VPN 设备负载过高
- 分支机构交换机异常
- Wi-Fi 接入拥塞
传统监控工具由于缺乏统一网络可视化能力,很难快速定位这些问题。
运维团队人手有限,但告警数量却越来越多
现代 IT 环境每天都会产生大量告警。
如果缺少智能告警机制,运维人员很容易陷入:
- 告警风暴
- 重复告警
- 无效通知
- 人工关联分析
最终导致:
- MTTR(平均故障恢复时间)增加
- 关键业务中断时间延长
- 运维疲劳严重
而这也是 AIOps 市场高速增长的重要原因之一。数据显示,AIOps 市场预计将从 2025 年的 159.6 亿美元增长至 2026 年的 193.3 亿美元,年复合增长率达到 21.1%。
企业希望通过智能运维平台减少人工分析压力,并实现更加主动的故障预测。
OpManager:面向现代 IT 的网络监控系统
作为一款成熟的网络监控系统,OpManager 提供了覆盖网络设备、服务器、虚拟化环境以及关键基础设施的统一监控能力。
其核心优势并不只是“监控”,而是帮助企业实现:
- 网络可视化
- 智能运维
- 故障根因定位
- 容量规划
- 混合环境统一监控
对于需要构建现代化 NOC(网络运维中心)的企业来说,OpManager 提供了一种更加完整、可落地的解决方案。
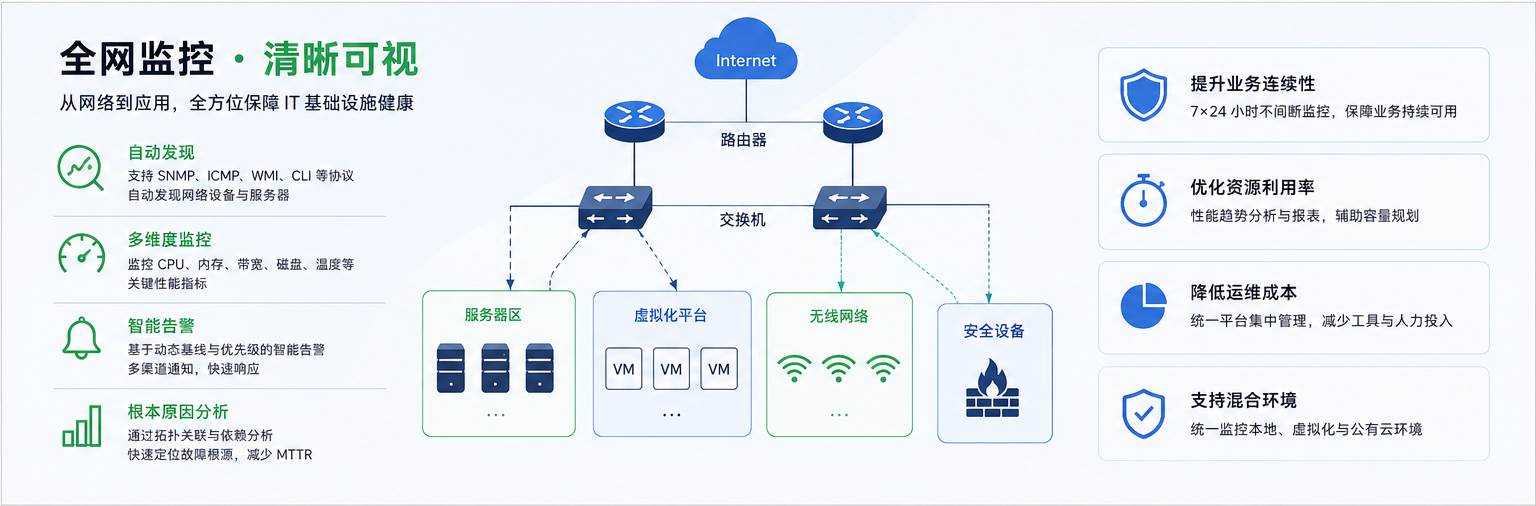
自动发现与网络可视化:让复杂网络真正“看得见”
自动发现全网设备
在大型企业环境中,网络设备数量可能达到数千台。
OpManager 支持通过:
- SNMP
- ICMP
- WMI
- CLI
- VMware API
等方式自动发现网络中的设备与资源,包括:
- 路由器
- 交换机
- 防火墙
- 服务器
- 虚拟机
- 无线设备
这对于多分支机构或混合办公场景尤其重要。
很多企业最大的难点并不是“监控”,而是根本不知道网络中有哪些资产正在运行。
OpManager 可以帮助运维团队快速建立完整资产视图。
动态网络拓扑图提升可观测性
传统监控工具通常以列表形式展示设备状态。
而 OpManager 提供动态网络拓扑映射能力,可以自动生成:
- Layer 2 拓扑图
- 业务视图
- 数据中心布局图
- WAN 链路视图
这对于现代可观测性体系至关重要。
因为很多时候:
“问题不是单点故障,而是关联影响。”
例如:
某核心交换机异常可能导致:
- 多个 VLAN 中断
- VPN 延迟增加
- 云应用访问异常
- VoIP 质量下降
通过网络可视化,运维团队能够更快理解故障传播路径。
这也是当前越来越多企业重视“拓扑感知型监控”的原因。
多维度服务器监控与网络性能监控
实时监控关键性能指标
OpManager 提供全面的服务器监控与网络性能监控能力,可实时采集:
- CPU 使用率
- 内存利用率
- 磁盘空间
- 接口流量
- 丢包率
- 延迟
- 温度
- 电源状态
对于关键业务系统而言,这些指标直接决定用户体验。
例如:
数据库服务器磁盘 IOPS 异常,可能导致:
- ERP 响应缓慢
- API 超时
- Web 页面卡顿
通过实时性能监控,运维人员能够提前发现资源瓶颈。
支持 SNMP 监控与多厂商设备
在现实环境中,企业通常并非单一厂商网络。
很多组织同时部署:
- Cisco
- 华为
- HPE
- Juniper
- Fortinet
等不同品牌设备。
OpManager 支持广泛的 SNMP 监控能力,并兼容大量主流厂商 MIB。
这意味着企业无需因为设备品牌不同而部署多个监控平台。
统一监控不仅降低运维复杂度,也减少了学习与维护成本。
智能告警与根本原因分析:减少“告警风暴”
从“发现故障”到“预测风险”
传统监控更多是被动响应。
但现代智能运维更强调:
- 动态基线
- 趋势分析
- 异常检测
- 预测性告警
OpManager 能够基于历史运行数据建立性能基线。
例如:
某 WAN 链路平时利用率为 40%,突然持续升高至 85%,系统即可识别异常趋势并触发预警。
相比固定阈值,这种方式更适合现代动态网络环境。
根本原因分析提升故障处理效率
很多时候,运维团队最头疼的问题并不是收到告警,而是不知道:
“哪个才是真正的故障源头?”
例如:
某核心设备故障可能同时引发:
- 服务器离线
- 应用超时
- VPN 中断
- AP 掉线
如果缺少根本原因分析能力,系统可能产生几十甚至上百条重复告警。
OpManager 能够通过设备依赖关系与拓扑分析帮助识别根因设备,从而减少无效告警干扰。
这对于降低 MTTR 具有非常现实的意义。
混合云与现代可观测性场景中的价值
统一监控本地与云环境
随着企业越来越依赖云服务,运维团队需要同时管理:
- 本地服务器
- VMware
- Hyper-V
- AWS
- Azure
而不同平台的数据通常分散严重。
OpManager 提供统一监控视角,帮助 IT 团队建立跨环境的性能可见性。
这对于当前混合云趋势尤为关键。
因为 SolarWinds 的研究已经表明,混合 IT 复杂度是企业增加可观测性投资的首要驱动力。
网络拓扑帮助理解“为什么”
Gartner 对现代可观测性的定义强调:
不仅知道“发生了什么”,更要理解“为什么发生”。
OpManager 的网络拓扑、依赖映射以及性能关联能力,可以帮助运维团队从:
- 网络层
- 服务器层
- 应用连接层
多个维度理解故障关系。
这也是现代网络监控工具与传统 NMS 最大的区别之一。
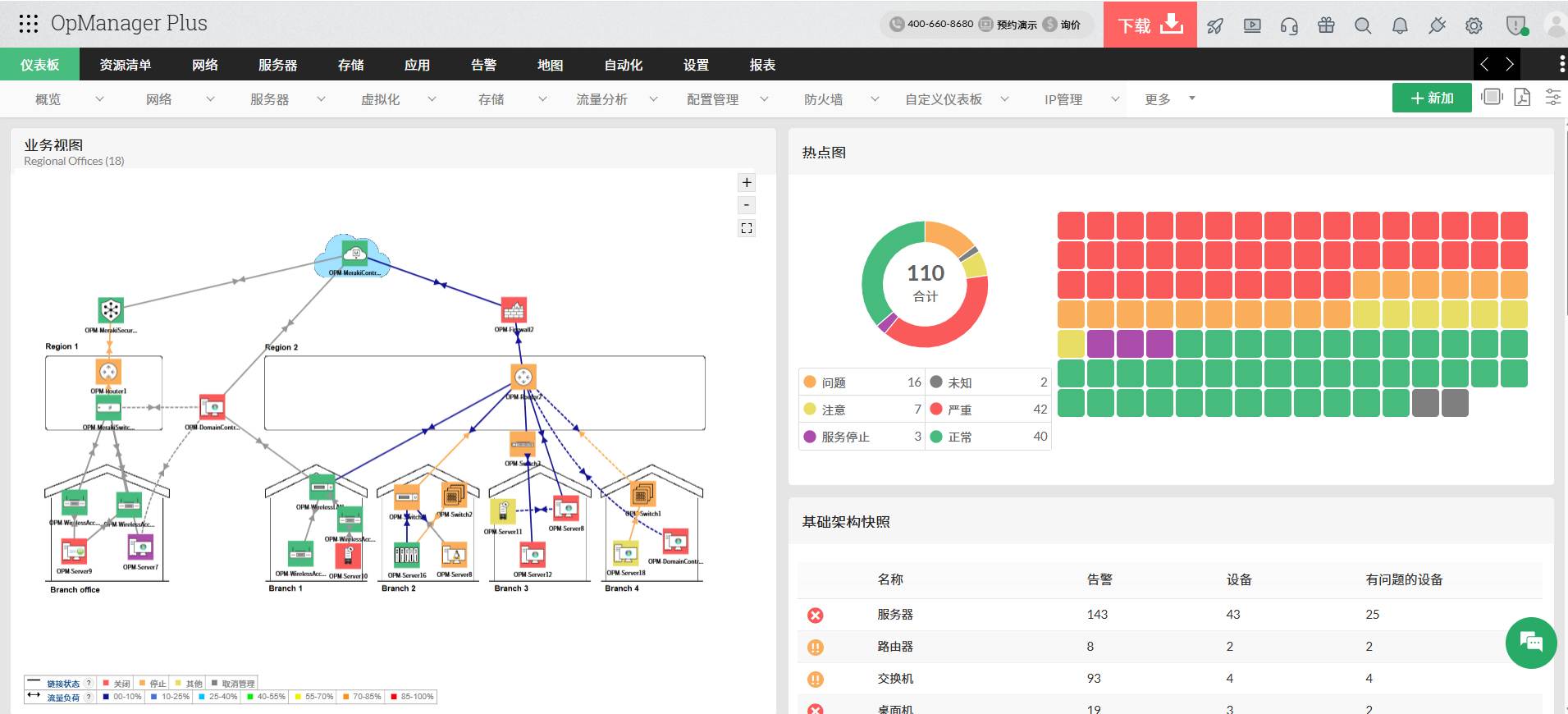
与传统监控工具相比,OpManager 为什么更适合现代企业?
对比 Nagios
Nagios 功能强大,但:
- 配置复杂
- 可视化能力有限
- 插件依赖较高
- 初期部署成本较大
对于很多中大型企业而言,维护成本较高。
对比 Zabbix
Zabbix 在开源监控领域非常流行,但:
- 拓扑展示能力相对有限
- 多团队协作体验一般
- 智能运维能力需要额外扩展
很多企业最终仍需结合其他工具补足网络可视化能力。
对比 Cacti
Cacti 更偏向流量图形展示。
虽然适合基础 SNMP 监控,但:
- 告警能力有限
- 缺乏完整根本原因分析
- 不适合现代复杂混合环境
对于当前强调可观测性与智能运维的企业来说,已经难以满足需求。
OpManager 的优势:开箱即用与统一运维体验
相比传统工具,OpManager 更强调:
- 可视化
- 易部署
- 多厂商兼容
- 智能告警
- 模块化扩展
- 统一运维视图
尤其是在当前 AIOps 与可观测性趋势下,这种“一站式网络监控平台”正在成为越来越多企业的选择。
面向未来的智能运维平台
未来 IT 运维的发展方向已经越来越明确:
- 网络与安全深度融合
- AIOps 普及
- 混合云长期存在
- SD-WAN 成为主流
- 可观测性替代传统监控

与此同时,零信任与 SASE 架构也正在推动企业更加依赖互联网与云连接。
数据显示,SASE 市场预计将从 2026 年的 191.9 亿美元增长至 2032 年的 680.6 亿美元。
在这样的背景下,企业需要的不再只是一个简单的“监控工具”,而是一个能够帮助 IT 团队建立统一可见性、快速定位问题、优化资源利用率的现代化运维平台。
OpManager 正是在这样的趋势中体现出价值。
通过自动发现、网络可视化、服务器监控、智能告警、SNMP 监控以及根本原因分析能力,OpManager 能够帮助企业更高效地管理复杂网络环境,并逐步迈向真正的数据驱动型智能运维。
对于正在规划现代化 IT 运维体系的企业来说,现在正是重新评估网络监控平台的重要时机。
互动话题
你的企业是否也经历过因网络中断导致的重大损失?你是如何从被动救火转向主动预防的?欢迎分享你的故事。
想亲身体验OpManager如何引领智能运维新纪元?它支持30天免费试用(全功能开放),现有用户更新到最新版本即可使用;还能预约1对1演示,看看如何为你的企业构建智能网络监控体系~
- 即刻开始体验!免费下载安装并享30天全功能开放!
- 需要深入交流?预约产品专家一对一定制化演示!
- 获取报价?填写信息获取官方专属报价!
- 想了解更多?点击进入OpManager官网并查看更多内容!
- 倾向云版本?Site24*7云上一体化解决方案!
常见问题(FAQs)
- 为什么AIOps是现代企业运维的必然趋势?
答:Gartner预测到2026年超60%大中型企业将采用AIOps。混合云、SD-WAN和远程办公使网络复杂度激增,传统监控产生大量告警且难以定位根因。AIOps通过动态基线、异常检测和智能关联分析,帮助企业从被动响应转向主动预测,降低MTTR并提升运维效率。
- OpManager如何实现混合云环境的统一监控?
答:OpManager支持自动发现本地设备(路由器/交换机/服务器)、虚拟化平台(VMware/Hyper-V)以及公有云资源(AWS/Azure),通过统一仪表盘展示跨环境性能指标、拓扑关系和告警,并提供与云API的集成能力,实现混合IT架构的端到端可观测性。
- OpManager的根本原因分析(RCA)如何工作?
答:OpManager通过动态拓扑映射建立设备依赖关系,当故障发生时自动关联上下游设备状态、分析网络路径和性能指标,识别核心异常节点。例如,业务缓慢可能是核心交换机拥塞或WAN链路抖动引起,RCA能直接定位源头,避免告警风暴。
- 相比Nagios/Zabbix,OpManager的核心优势是什么?
答:OpManager提供开箱即用的网络拓扑可视化、智能告警压缩、根本原因分析和丰富报表,无需大量脚本配置。其统一运维平台降低了学习成本和长期维护复杂度,尤其适合混合云、多厂商设备环境,帮助企业快速落地智能运维。
- 如何开始使用OpManager进行网络监控?
答:下载30天免费试用版,安装后通过自动发现向导扫描IP范围,系统自动识别设备并生成拓扑图。内置监控模板覆盖CPU、内存、带宽等关键指标,并可配置智能告警策略。支持本地、虚拟化及云环境,通常数小时内即可完成基础部署。



