2026智能运维拐点:为什么你的网络监控工具必须“懂思考”而不只是“能看见”?
AI 摘要
2026年智能运维拐点已至,网络监控工具需从“被动看见”升级为“主动思考”。OpManager通过AI/ML异常检测、动态基线、智能告警关联与根因分析、自动拓扑发现、3D机房可视化及SD-WAN监控等能力,帮助企业实现从被动响应到主动预防的转型。结合Agentic AI与可观测性趋势,OpManager构建端到端全栈监控,压缩告警噪音,缩短MTTR,应对SASE混合网络与零信任安全挑战,是驱动网络走向“自动驾驶”的核心平台。
凌晨3点,运维经理的手机再次被数十条“端口流量异常”“设备响应超时”“CPU利用率飙升”的告警震响,而你却无法从这堆混乱告警中快速定位真正的故障根因。当网络规模逼近千节点、业务负载呈现秒级波动时,传统“人海战术”加“静态阈值告警”的运维模式,早已力不从心——这正是 OpManager试图为每家企业解决的难题:将你的网络监控工具从“被动看见”升级为“主动思考”。
本文将从2026年最受关注的四大热点——智能体AI与可观测性、AIOps场景化实战、SASE混合网络监控、IT/OT融合与零信任安全——出发,结合OpManager的真实能力,为你呈现一条从“被动救火”走向“自动防御”的完整路线图。



一、Agentic AI与可观测性:从“看见”到“预见”的底层升级
2026年,AI能力的竞争焦点已从“谁支持了下一代标准”转向“谁真正具备以AIOps驱动网络运行的能力”。HPE的预测给出了一个颇具冲击力的结论:AIOps在2026年的重要性将首次超越Wi-Fi标准本身。换句话说,企业比拼的不再是“我的网络有多快”,而是“我的网络有多聪明”——能否在业务受损之前自动预测故障并提前干预。
这个转变背后,是网络从“被动反应”向“主动预见”的范式革命。Omdia报告还揭示,监控AI模型和Agentic AI应用现已成为释放AI举措价值的关键优先事项。然而,调研中近半数的企业(48.9%)对机器间的智能体流量完全不可见,无法监控自己的AI代理。这是当前运维领域一个巨大的可见性盲区。
在这一背景下,OpManager的核心价值恰好落在“让AI先看得清”这一关键环节上。OpManager是一个端到端的网络、服务器、虚拟机和存储设备监控平台,覆盖了企业IT基础设施从物理设备到应用服务的全栈层面。其网络监控能力深度覆盖路由器和交换机,还能扩展至无线接入点、WAN链路、存储阵列等设备。更关键的是,OpManager内置的AI/ML异常检测能力,能够通过动态基线和历史学习,识别出那些静态阈值永远无法捕获的异常模式,让运维团队从“被动响应”过渡到“主动预防”。
当网络规模扩展到千节点级别,手动绘制和更新拓扑图已不可能——而OpManager的自动网络发现与L2拓扑映射功能,可以自动扫描IP范围内的所有二层设备,生成包含节点、互联层及端口到端口连接的完整网络拓扑图,并随网络变化实时同步,彻底告别“人肉查配置”的痛苦阶段。这正是Agentic AI发挥效能的前置条件:让AI拥有一个清晰、实时、完整的网络数字孪生模型。
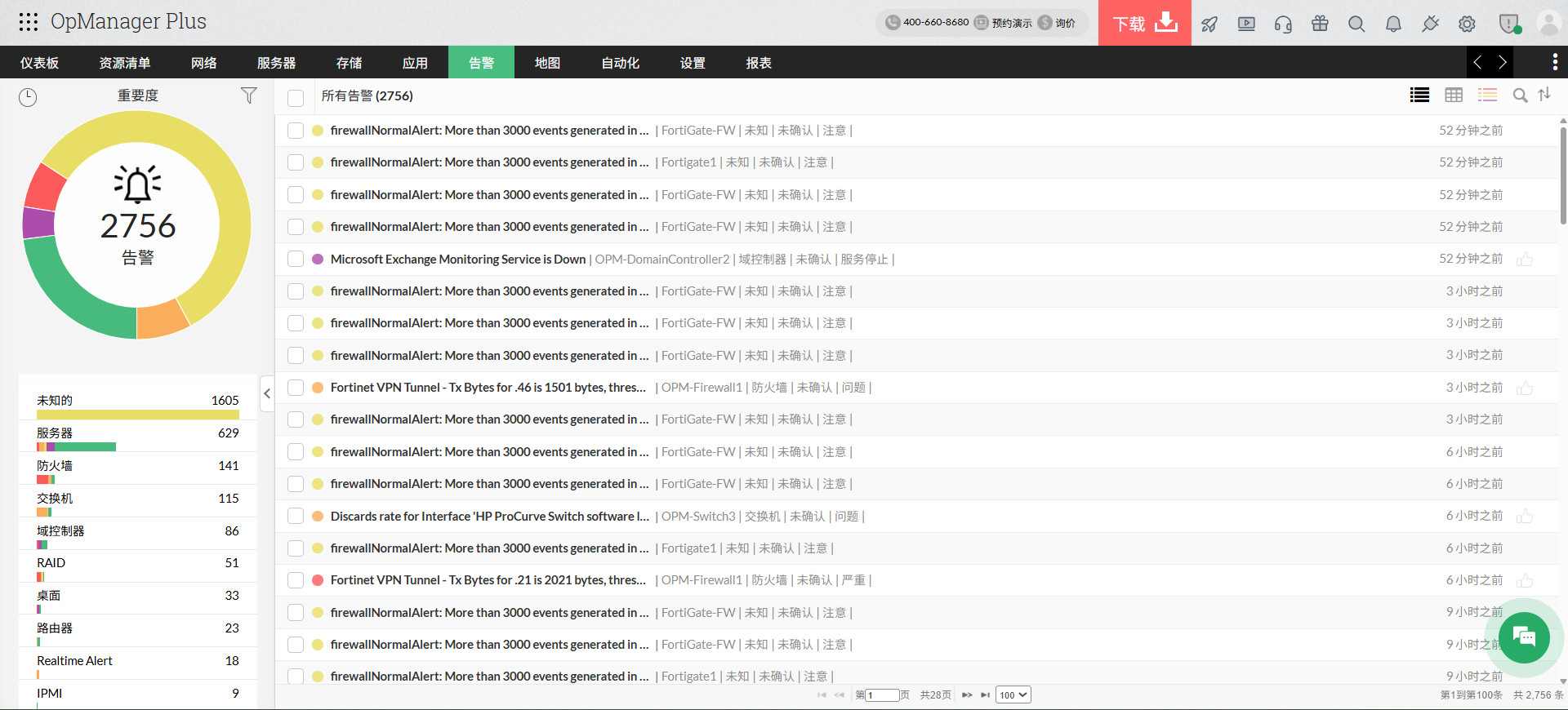
二、AIOps“场景化实战”:智能告警如何终结“半夜被叫醒”的噩梦
如果说前几年行业还在争论“要不要用AI做运维”,那么2026年的关键词已经变成了“AI到底怎么帮运维干活”——这就是行业热议的“AIOps场景化实战”。行业焦点从“能否拥有AI”转向“AI如何在实际运维流程中生效”。
场景化实战的核心要求是什么?智能系统应能自动对告警进行压缩、去重、关联,并基于历史数据与知识库,为每一条有效告警附上“最可能的原因”和“初步处置建议”。具体来说,一个好的AIOps平台不应只发出“数据库服务器A的CPU使用率95%”这样孤立无援的告警,而应将它与此服务器上特定SQL查询耗时激增关联,并提示“建议检查执行计划或联系应用团队”。
这正是OpManager智能告警与故障管理的核心战场。OpManager的智能告警引擎不仅仅是展示一条条单调的阈值告警,而是将原始网络事件进行关联、过滤和压缩,将有意义的告警按严重程度彩色编码后呈现给运维人员。AI/ML驱动的异常检测和动态基线技术,让系统能够学习设备的“正常行为模式”,在偏离常态时提前预警,而不是等到设备彻底宕机才触发静默告警。
在根本原因分析层面,OpManager提供了基于因果推断的能力。通过统一遥测数据和因果图谱技术,OpManager能够快速构建依赖关系模型,自动压制因单一故障引发的次级告警,帮助团队在告警风暴中直接锁定真实根因。在OpManager Plus中,这一能力进一步扩展到跨域协同、自动纠错和容量规划预测,为企业构建起从自动发现到持续监控、智能告警、分析定位、自动修复的完整运维闭环。
把所有这些功能整合起来看:一个中小规模的故障事件,传统排查可能需要30分钟甚至更久;而通过OpManager的智能告警关联与根因分析,这个时间可以压缩到几分钟以内。这对于日均处理成百上千条告警的运维团队而言,是一场实实在在的效率革命。
三、SASE与混合网络监控:混合云时代的可见性突围
当前超过70%的企业同时使用3个以上的公有云,加上私有云和边缘计算节点,网络拓扑已从经典的“星型”演变为复杂的“网状”。与此同时,SD-WAN正加速向SASE架构迁移。Gartner的最新预测显示,到2029年,75%的SD-WAN采购将来自单厂商SASE平台,而在2025年这一比例仅为25%。到2026年底,全球近60%的新SD-WAN采购将被集成到单厂商SASE架构中。
这意味着网络和安全的一体化管理已成为不可逆转的趋势。主流SD-WAN方案普遍采用机器学习驱动的预测性调度,能够学习历史流量模式,结合实时网络状态预测并规避潜在性能瓶颈。然而,传统的网络监控工具在面对跨云、跨域的混合环境时,往往暴露出策略配置复杂、流量调度僵化、可见性碎片化等痛点。
OpManager在混合网络监控方面的能力正是应对这一挑战的利器。它已支持通过REST API从各厂商原生监控系统直接提取SD-WAN控制器和边缘设备的健康状态、性能指标与设备详情。在OpManager 2026年的最新版本中,对VeloCloud SD-WAN的支持也已正式上线,能够实时追踪控制器、隧道、WAN链路及整体网络健康状况。结合OpManager利用Cisco IPSLA技术实现的WAN链路可用性监控与故障排查,企业可以在混合网络中获得从数据中心到分支机构、从本地设备到云服务的统一可见性。
对于运维团队而言,这种能力意味着:无论底层网络采用何种SD-WAN/SASE架构组合,都能在一个平台上看到所有节点的状态、流量和性能趋势,无需在不同工具之间反复切换,从根本上消除了混合云时代的可见性盲区。
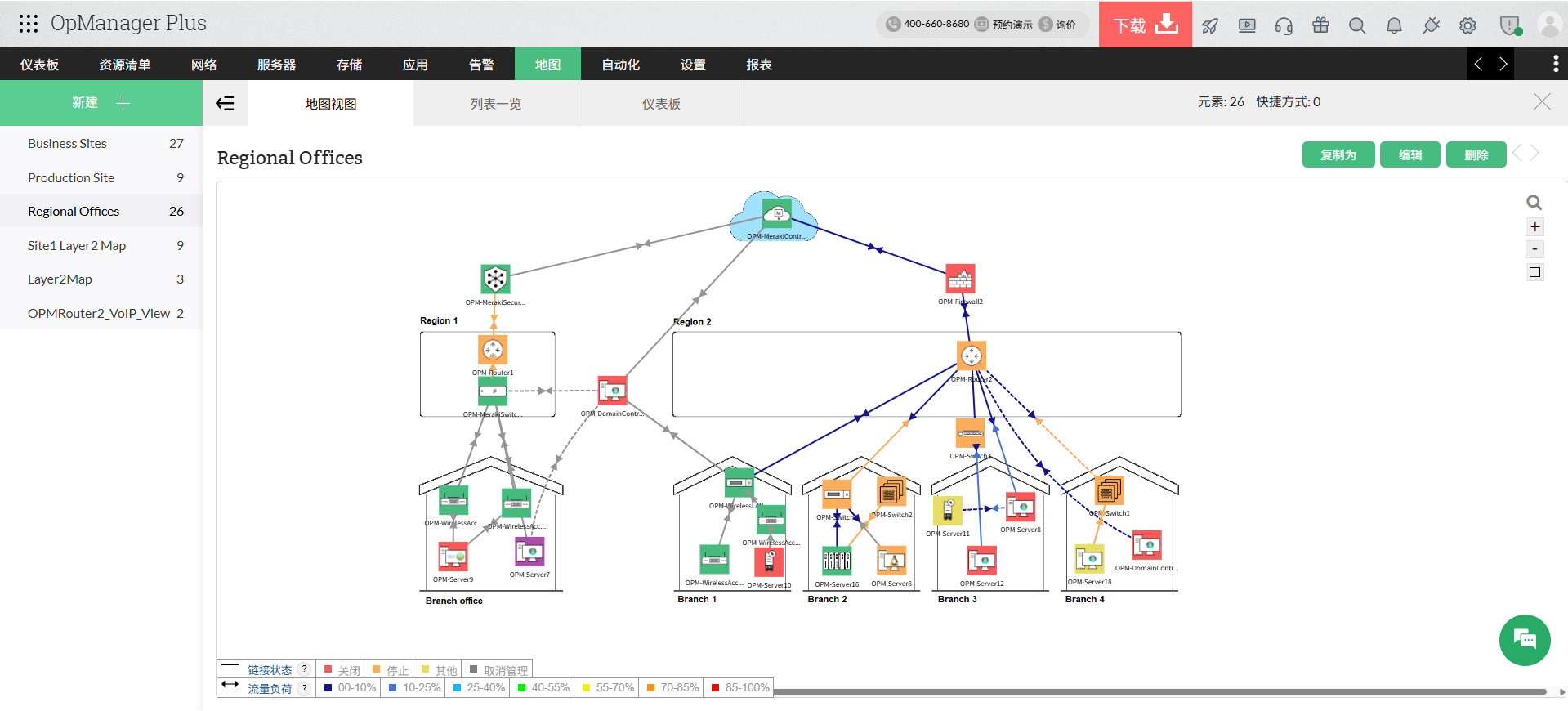
四、网络可视化与3D机房:让复杂运维“一目了然”
在数字化转型加速的背景下,网络不再是割裂的接入层、无线层或核心层的简单叠加,而是演进为由AI协调的自适应体验型网络体系。HPE指出,2026年是网络迈向“自动驾驶”的关键拐点,Agentic AI将嵌入交换机与AP中,主动预测并调整。然而,当网络如此庞大和复杂时,运维人员的最大痛点往往不是“监控不到”,而是“看不明白”——上千个设备、数百条连接关系,仅靠数据表格和命令行,根本不可能形成对整体网络健康状况的直觉判断。
这就是网络可视化工具战略价值所在。OpManager提供了从物理拓扑到虚拟业务视图的全方位可视化能力:Layer2拓扑图自动反映交换机和路由器之间的真实物理连接;业务视图允许按业务维度组织设备,直观追踪跨部门流量流向;而3D机房视图与机架视图则为数据中心管理员提供了沉浸式、动态更新的机房数字孪生。一个典型的场景是:在某数据中心,运维人员在3D视图中看到某个机架上的服务器状态由绿变红,单击即可下钻至该设备的详细监控页面,快速完成从“发现异常”到“定位故障”的全过程。
可视化不仅是“好看”,它在AI运维的闭环中扮演着至关重要的角色——让AI的决策结果能够以人类最容易理解的方式呈现出来。当系统检测到某个网络路径延迟异常时,运维人员可以在拓扑图中立即看到异常路径的视觉效果,并结合根本原因分析给出的信息快速做出判断和响应。这正是从“机器决策”到“人机协同”的关键桥梁。
数字化转型的当下,你的网络监控工具准备好了吗?
2026年的IT运维格局已经清晰:智能体AI走向主流,可观测性成为战略核心,SASE安全架构加速普及,而AIOps的比拼正式进入“场景化实战”阶段。在这场变革中,网络监控工具不再是边缘的辅助系统,而是决定企业IT竞争力的战略基础设施。
ManageEngine OpManager以其端到端的全栈监控能力、AI驱动的智能告警与根因分析、自动化的拓扑发现映射、沉浸式的3D机房可视化以及混合网络(包括SD-WAN)的全方位支持,为企业从“被动响应”向“主动预见”的运维转型提供了坚实的支撑平台。
立即试用ManageEngine OpManager 30天免费版,体验从“看见”到“预见”的智能运维之旅。访问我们的功能页面,解锁更多关于自动网络发现、智能告警、根本原因分析和3D数据中心可视化的深度演示,让你的网络管理真正进入AI驱动的时代!
互动话题
你的企业是否也经历过因网络中断导致的重大损失?你是如何从被动救火转向主动预防的?欢迎分享你的故事。
想亲身体验OpManager如何引领智能运维新纪元?它支持30天免费试用(全功能开放),现有用户更新到最新版本即可使用;还能预约1对1演示,看看如何为你的企业构建智能网络监控体系~
- 即刻开始体验!免费下载安装并享30天全功能开放!
- 需要深入交流?预约产品专家一对一定制化演示!
- 获取报价?填写信息获取官方专属报价!
- 想了解更多?点击进入OpManager官网并查看更多内容!
- 倾向云版本?Site24*7云上一体化解决方案!
常见问题(FAQs)
- 为什么2026年被称为智能运维的拐点?
答:因为AI能力从标准竞赛转向实际落地,AIOps重要性首次超越Wi-Fi标准本身。企业网络从“被动反应”转向“主动预见”,Agentic AI、可观测性、SASE成为核心趋势,监控工具必须“懂思考”而非仅“能看见”。
- OpManager如何通过AIOps终结告警风暴?
答:OpManager智能告警引擎对事件进行关联、过滤和压缩,利用AI/ML动态基线学习正常行为模式,在异常偏离时提前预警。根本原因分析基于因果图谱自动压制次级告警,直接锁定根因,将故障排查时间从30分钟压缩到几分钟。
- SASE架构下,OpManager如何实现混合网络统一监控?
答:OpManager通过REST API直接提取SD-WAN控制器和边缘设备的健康状态,最新版本已支持VeloCloud SD-WAN监控。结合Cisco IPSLA技术进行WAN链路分析,企业可在单一平台获得从数据中心到分支机构、从本地到云端的统一可见性,消除混合云盲区。
- 网络可视化(3D机房与拓扑图)对智能运维的实际价值是什么?
答:可视化让AI的决策结果以人类易懂的方式呈现,运维人员可在拓扑图中直观看到异常路径,结合根因分析快速响应。3D机房提供沉浸式数字孪生,单击设备即可下钻详情,实现从“发现异常”到“定位故障”的秒级闭环,是人机协同的关键桥梁。
- OpManager如何赋能Agentic AI和可观测性?
答:OpManager提供端到端全栈监控(网络、服务器、虚拟机、存储),内置AI/ML异常检测和动态基线。自动网络发现与L2拓扑映射为AI创建实时、完整的网络数字孪生,让AI“看得清”才能“想得明”,是Agentic AI发挥效能的前置条件。



