OpManager 如何重塑企业网络管理:从网络故障监控到智能运维
AI 摘要
OpManager为企业提供统一网络管理与智能运维平台,解决传统监控效率低、多厂商设备管理复杂、故障定位慢等难题。核心功能包括自动发现资产、实时性能监控(CPU/内存/带宽)、智能告警、根本原因分析(RCA)及网络拓扑可视化。相比开源工具,OpManager具备更低的学习成本、更强的可视化与报表能力。帮助企业降低MTTR 70%以上,适用于多分支、数据中心、混合云等场景,实现从被动救火到主动预防的运维升级。
在网络规模持续扩张、业务系统日益复杂的今天,传统运维方式已经难以满足企业对稳定性和可视化管理的需求。越来越多企业开始意识到,仅依赖人工巡检和分散监控,已经无法有效应对现代网络环境中的性能波动与突发故障。作为一款成熟的网络管理平台,OpManager正在帮助企业重新定义网络故障监控与基础设施运维模式。
对于网络管理员和 IT 运维团队来说,真正困难的并不是“发现问题”,而是如何在复杂环境中快速定位问题根源,并在业务受影响之前完成处理。而这,正是现代网络管理体系需要解决的核心问题。



一、为什么传统网络管理越来越难?
随着企业数字化建设深入推进,IT 基础设施已经从过去单一的数据中心环境,演变为:
- 多分支机构网络
- 混合云架构
- 虚拟化平台
- 多厂商设备混合部署
- 应用与业务深度耦合
在这样的环境下,传统监控方式逐渐暴露出明显短板。
1. 手动监控效率低
很多企业仍依赖:
- Ping 检测
- Excel 资产记录
- 人工查看日志
- 单设备逐个排查
这种方式不仅效率低,而且极易遗漏关键异常。
尤其在网络规模达到数百甚至上千台设备后,人工监控几乎无法持续。
2. 多厂商设备管理复杂
现实中的企业网络,很少只使用单一品牌设备。
常见环境包括:
- Cisco
- HPE
- Huawei
- Juniper
- VMware
- Windows/Linux Server
不同平台之间缺乏统一视图,会导致:
- 监控数据割裂
- 告警无法关联
- 故障定位困难
最终结果是:
👉 网络问题越来越难排查
👉 运维团队压力持续增加
3. 网络故障定位慢
在传统模式下,一次网络异常往往需要经历:
- 用户反馈
- 人工确认
- 多系统排查
- 设备逐层定位
整个过程可能耗费数小时。
而在业务连续性要求极高的今天:
- 电商平台
- 金融系统
- 制造业生产网络
- 医疗信息系统
任何一分钟的中断,都可能带来巨大损失。
因此,“快速发现 + 快速定位”已经成为现代网络管理的核心能力。
二、OpManager:面向现代企业的网络故障监控平台
OpManager 本质上不仅仅是一套监控工具,更是一套完整的网络管理与智能运维平台。
它能够帮助企业实现:
- 网络设备统一监控
- 网络故障监控
- 性能分析
- 自动发现
- 智能告警
- 网络拓扑可视化
- 根因分析(RCA)
通过集中化管理,运维团队可以真正做到:
👉 “在故障影响业务之前发现问题”
三、OpManager 的核心功能解析
1. 自动发现与资产管理
在大型网络环境中,资产管理往往是最头疼的问题之一。
OpManager 支持:
- 自动扫描网络设备
- 自动识别 IP 与接口
- 自动分类设备类型
- 自动生成资产清单
无论是:
- 路由器
- 交换机
- 防火墙
- 服务器
- 无线设备
- 虚拟机
都可以快速纳入统一监控体系。
这意味着企业无需再依赖手工登记设备,大幅减少管理成本。
2. 实时性能监控:CPU、内存、带宽全面可视化
现代网络管理的关键,在于“实时感知”。
OpManager 可持续监控:
- CPU 使用率
- 内存占用
- 磁盘性能
- 网络带宽
- 接口流量
- 丢包率
- 网络延迟
通过统一仪表盘,管理员可以快速掌握全网运行状态。
例如:
- 哪条链路正在拥塞
- 哪台服务器负载异常
- 哪个交换机端口流量飙升
这些问题都能实时呈现。
相比传统 CLI 排查方式,效率提升非常明显。
3. 智能告警机制:让故障提前暴露
很多网络事故,并不是突然发生,而是长期性能异常积累的结果。
OpManager 支持:
- 阈值告警
- 多级告警策略
- 邮件/短信通知
- 告警关联分析
例如:
- CPU 持续超过 90%
- 带宽异常突增
- 设备离线
- 温度异常
系统都可以第一时间通知管理员。
更重要的是,它支持智能告警抑制机制,减少“告警风暴”。
这意味着:
👉 运维团队不会再被海量无效告警淹没。
4. 网络故障根源分析(RCA)
对于大型企业来说,真正困难的并不是“知道故障发生了”,而是:
👉 “故障到底是谁引起的?”
OpManager 提供根本原因分析(Root Cause Analysis)能力,可以:
- 关联上下游设备状态
- 分析网络路径
- 识别核心异常节点
例如:
某业务系统访问缓慢,可能并非应用本身问题,而是:
- 核心交换机拥塞
- WAN 链路抖动
- 防火墙接口异常
通过 RCA,管理员可以快速定位真正问题源头。
很多企业在部署后,平均故障修复时间(MTTR)可降低 70% 以上。
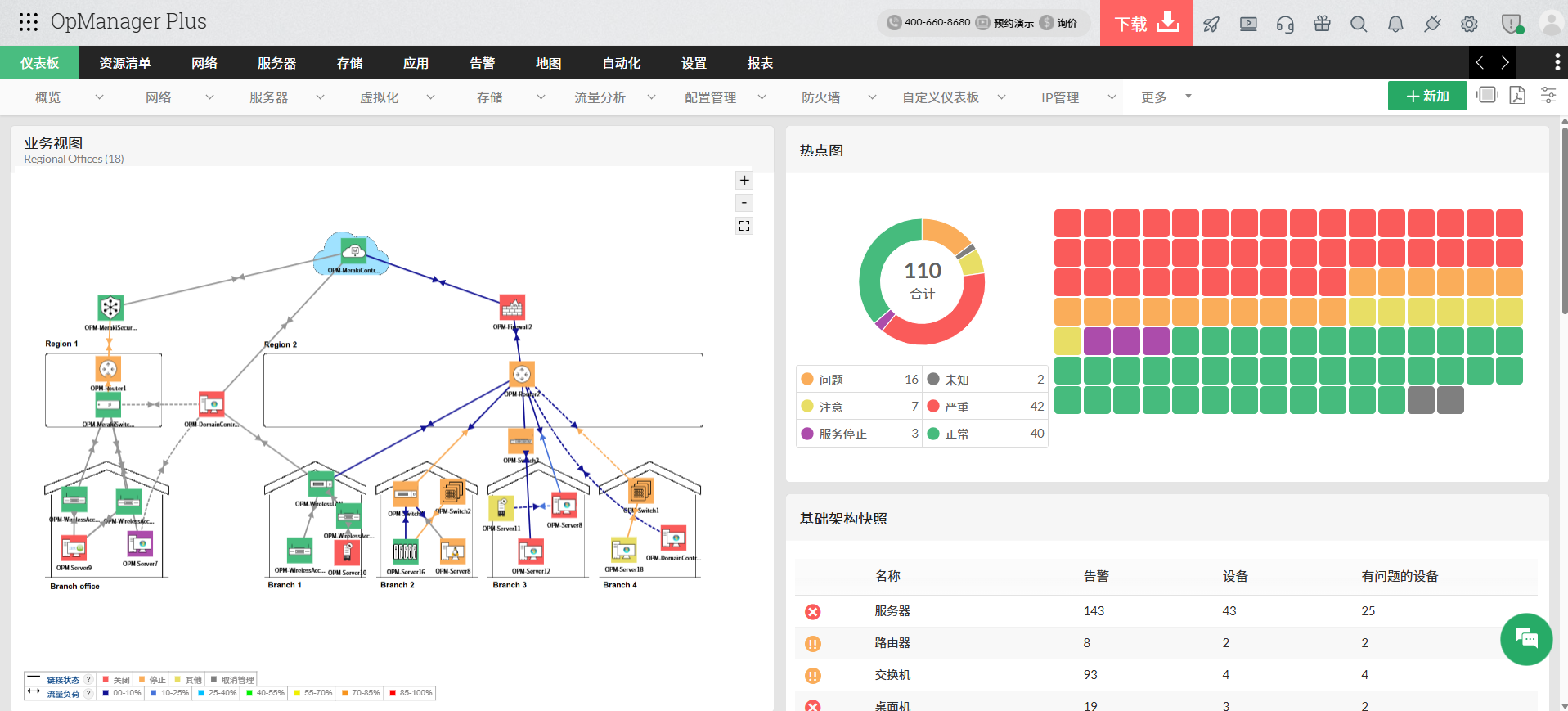
5. 网络映射与拓扑可视化
复杂网络环境最怕“看不清”。
OpManager 支持:
- 二层拓扑发现
- 业务视图映射
- 数据中心可视化
- WAN 链路展示
管理员可以通过可视化拓扑快速了解:
- 设备连接关系
- 故障影响范围
- 关键业务链路状态
相比传统文字列表,可视化管理更适合现代运维团队。
四、典型使用场景
场景 1:分支机构网络监控
很多企业拥有:
- 多办公室
- 多门店
- 多工厂
OpManager 可以统一监控:
- VPN 状态
- 分支链路质量
- 网络延迟
- 设备在线率
帮助总部实时掌握全国网络状态。
场景 2:服务器与虚拟化集群监控
对于 VMware 或 Hyper-V 环境:
OpManager 可监控:
- 虚拟机性能
- 主机资源
- 存储状态
- CPU/内存使用率
避免资源争抢导致业务异常。
场景 3:链路质量分析
很多业务问题本质是链路问题。
例如:
- 视频会议卡顿
- ERP 响应慢
- 数据同步延迟
通过带宽与流量分析,运维团队可以快速识别:
- 高峰拥塞时间
- 异常流量来源
- WAN 性能瓶颈
五、相比 Nagios、Cacti、Zabbix,OpManager 有哪些优势?
很多企业在选择网络故障监控平台时,都会对比开源方案。
虽然 Nagios、Cacti、Zabbix 功能强大,但在企业级落地中往往存在:
- 部署复杂
- 配置门槛高
- 可视化不足
- 报表能力有限
- 长期维护成本高
相比之下,OpManager 更强调:
1. 更强的可视化能力
OpManager 提供:
- 拓扑图
- 地图视图
- 业务仪表盘
- 实时状态面板
更适合企业统一展示。
2. 更低的学习成本
很多运维团队并不希望:
- 编写大量脚本
- 手工配置监控模板
OpManager 提供更成熟的 GUI 管理体验。
即使是中小型 IT 团队,也能快速上手。
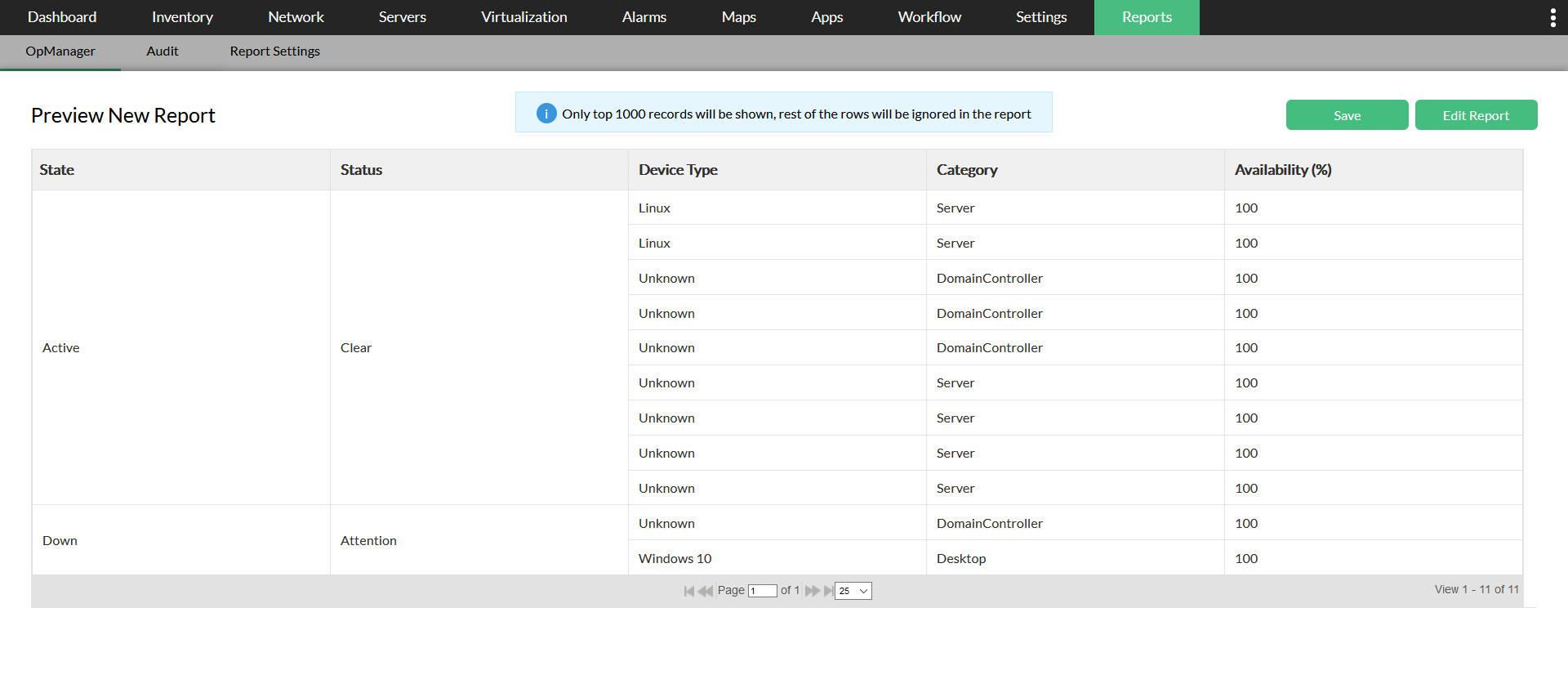
3. 更完善的报表体系
企业管理层往往需要:
- SLA 报表
- 可用性统计
- 容量趋势分析
- 带宽利用率报告
OpManager 可以自动生成可视化报表,方便汇报与审计。
六、为什么越来越多企业重视网络故障监控?
过去,网络监控更多被视为“运维工具”。
但如今,它已经成为企业稳定运营的重要基础设施。
因为很多安全与业务问题,最早都会体现在:
- 网络延迟异常
- 带宽波动
- 设备状态异常
- 流量突增
通过持续监测与智能分析,企业不仅能提升网络稳定性,更能降低潜在业务风险。
而这,也正是现代网络管理的发展方向。
七、总结
在数字化业务不断扩张的背景下,传统被动式运维已经无法满足现代企业需求。
企业真正需要的,是一套能够实现:
- 全局可视化
- 实时性能监控
- 智能告警
- 网络故障监控
- 自动化分析
的统一网络管理平台。
OpManager 正是在这样的趋势下,为企业提供了更高效、更智能的运维方式。
对于希望提升网络稳定性、降低故障恢复时间、优化 IT 运维效率的企业来说,构建现代化网络管理体系已经不再是“可选项”,而是“必选项”。
互动话题
你的企业是否也经历过因网络中断导致的重大损失?你是如何从被动救火转向主动预防的?欢迎分享你的故事。
想亲身体验OpManager如何引领智能运维新纪元?它支持30天免费试用(全功能开放),现有用户更新到最新版本即可使用;还能预约1对1演示,看看如何为你的企业构建智能网络监控体系~
- 即刻开始体验!免费下载安装并享30天全功能开放!
- 需要深入交流?预约产品专家一对一定制化演示!
- 获取报价?填写信息获取官方专属报价!
- 想了解更多?点击进入OpManager官网并查看更多内容!
- 倾向云版本?Site24*7云上一体化解决方案!
常见问题(FAQs)
- OpManager主要解决哪些网络管理难题?
答:OpManager解决传统运维中手动监控效率低、多厂商设备管理复杂、故障定位慢等难题。通过自动发现、实时性能监控、智能告警、根本原因分析和拓扑可视化,帮助IT团队快速发现并定位网络问题,降低MTTR 70%以上。
- OpManager如何实现网络故障的根本原因分析?
答:OpManager通过关联上下游设备状态、分析网络路径和识别核心异常节点,层层追溯故障源头。例如,业务系统慢可能源于核心交换机拥塞、WAN链路抖动或防火墙接口异常,RCA功能可快速定位真正根因。
- 相比Zabbix等开源工具,OpManager的优势是什么?
答:OpManager提供更强的可视化能力(拓扑图、业务仪表盘)、更低的学习成本(GUI操作,无需脚本)、更完善的报表体系(SLA、可用性、容量趋势)。企业落地更快,长期维护成本更低。
- OpManager可以监控哪些类型的设备?
答:支持路由器、交换机、防火墙、服务器(物理/虚拟)、无线设备、虚拟机、存储设备等,通过SNMP、WMI、CLI等多协议统一采集,适配多厂商环境(Cisco、华为、HPE、Juniper等)。
- 企业如何快速部署OpManager实现网络故障监控?
答:OpManager提供自动发现功能,扫描IP范围即可自动添加设备并生成拓扑图。内置预定义监控模板,支持阈值告警、多级通知,通常数小时内即可完成基础监控配置,大幅缩短部署周期。



