局域网性能监控实战 — 带宽占满、延迟飙升、流量异常的快速定位三法
AI 摘要
本文提供局域网性能监控实战指南,针对带宽占满、延迟飙升、流量异常三大高频故障,给出快速定位三法。OpManager通过实时带宽监控与Top N排行、流量趋势对比、NetFlow协议级分析定位带宽问题;利用多层级延迟基线、逐跳路径分析和根因关联定位延迟飙升;通过流量基线学习、协议分布分析和Top会话分析识别异常流量。同时解析了常见误区和选型指标,帮助IT运维团队在分钟级内完成故障根因定位与恢复。
“网又卡了”——这是IT运维团队每天听到最多的一句话。然而,“网卡”只是一个用户感知层面的笼统描述,背后可能隐藏着截然不同的根因:可能是某台服务器在跑大文件备份吃光了整条链路的带宽,可能是核心交换机的某个端口存在双工模式不匹配导致延迟异常,也可能是某台终端被恶意软件感染后产生大量异常流量。
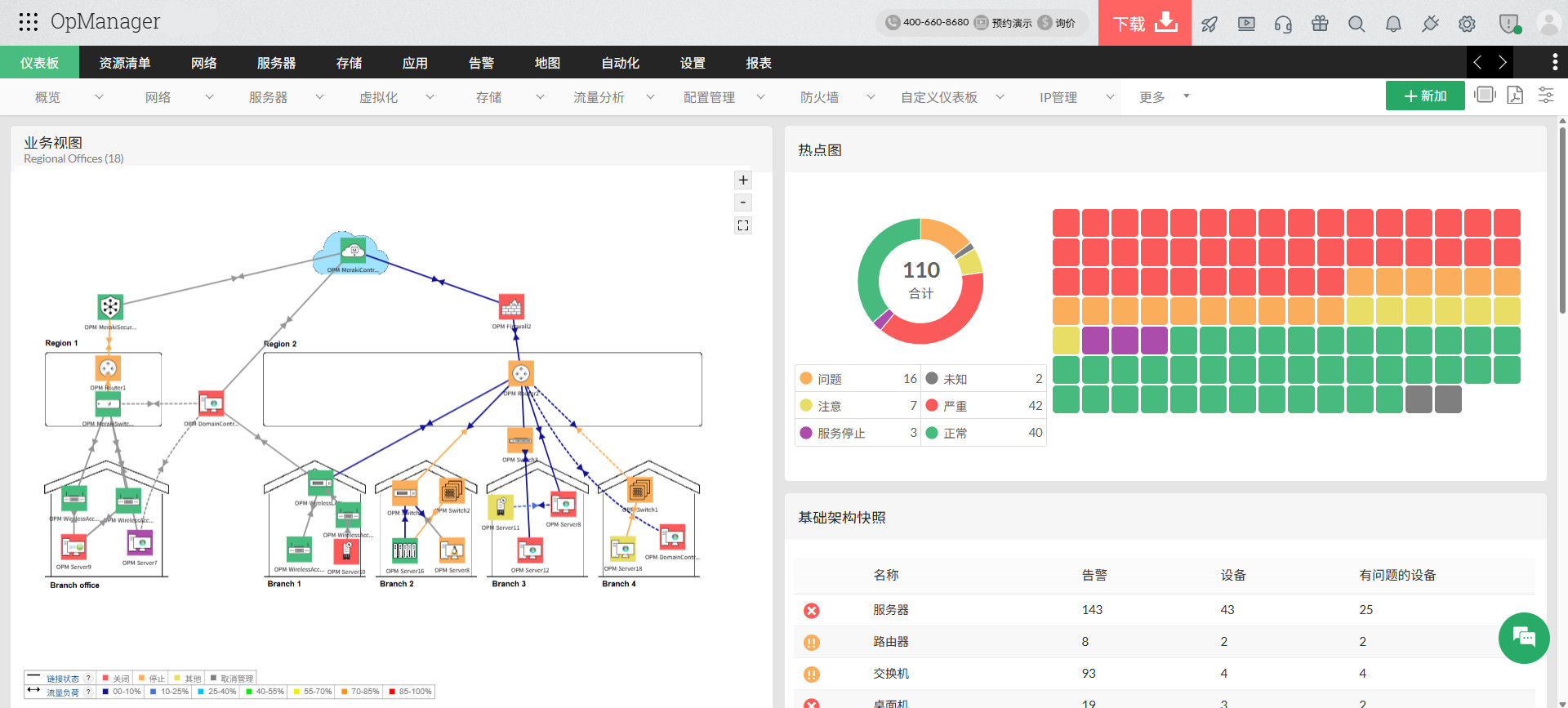
在没有系统化局域网监控手段的企业中,运维团队面对“网卡”投诉时往往陷入“逐设备排查”的低效循环:先登交换机看端口流量,再登路由器看路由表,再查防火墙日志——一趟排查下来可能已经过去了两三个小时,而用户的不满情绪已经升级。
ManageEngine OpManager作为深耕网络性能监控超过十五年的平台,将局域网三大高频故障的排查路径标准化为“快速定位三法”。本文将从带宽占满、延迟飙升和流量异常三个维度,为企业提供可落地的故障定位实战指南。



一、故障场景一:带宽占满 --- 从“谁的流量最大”到“谁的流量不合理”
带宽占满是局域网中最常见的性能问题。当一条链路的带宽利用率持续超过80%时,延迟会显著增加、丢包率上升、业务应用响应变慢。问题的关键在于:占满带宽的流量究竟是合理的业务负载,还是某台设备或某个进程的异常行为?
第一步:实时带宽监控与Top N排行。 OpManager对每个网络接口的入站和出站流量进行持续监控,实时展示带宽利用率。当链路利用率超过预设阈值时,系统自动生成告警,并同步输出该接口的Top N流量贡献者排行。运维人员无需手动逐台排查,一眼即可看到“是谁在吃带宽”。
第二步:流量趋势对比分析。 仅看实时数据容易产生误判——业务高峰期的带宽占满可能是正常现象。OpManager提供流量趋势对比功能,将当前带宽曲线与历史同期基线叠加对比。如果当前带宽利用率远超历史同期(如工作日上午10点的带宽比过去30天同期高出200%),系统自动标记为“异常流量”并告警。
第三步:基于NetFlow/sFlow的协议级分析。 当OpManager与支持NetFlow或sFlow的网络设备配合使用时,运维团队可将分析粒度从“哪台设备”细化到“哪个协议、哪个端口”。例如,发现某台研发服务器通过445端口(SMB)在非工作时间传输大量数据——这可能是配置不当的定时备份任务,也可能是安全事件。关于异常流量检测与安全分析的深度融合,敬请期待本系列第四篇《网络监控与安全融合:从态势感知到零信任网络的运维演进》。
二、故障场景二:延迟飙升 --- 从“延迟很高”到“延迟在哪一跳”
延迟是网络性能的另一个核心指标。用户感知到的“网慢”往往表现为延迟升高,但延迟升高的根因可能跨越多个网络层级:可能是接入层交换机端口双工不匹配,可能是核心交换机的MAC地址表溢出导致广播风暴,也可能是某个VLAN内的环路产生大量重复帧。
第一步:多层级延迟基线与异常检测。 OpManager对每对设备之间的网络延迟进行持续监测,并基于机器学习建立每个链路的延迟基线。不同链路有着截然不同的正常延迟范围——机房内两台交换机之间的延迟通常在亚毫秒级,而通过多级路由的跨楼层链路可能在数毫秒级。OpManager的自适应阈值能够区分这种差异,当某条链路延迟偏离自身基线超过容限时才触发告警,而非使用一刀切的固定阈值。关于自适应阈值的技术原理,详见本系列第一篇《AIOps平台落地指南:2026智能运维从告警关联到根因定位》。
第二步:逐跳路径延迟分析。 OpManager的网络路径分析功能可逐跳测量从源端到目的端的延迟分布。当端到端延迟升高时,运维人员可以快速定位延迟瓶颈发生在哪一跳。例如:总延迟从2ms飙升到50ms,路径分析显示第3跳(接入层交换机到汇聚层交换机之间)延迟从0.5ms升至45ms——根因锁定在这一段链路,无需排查其他节点。
第三步:根因关联与拓扑定位。 OpManager的告警关联引擎在延迟告警场景中提供关键价值:当延迟飙升同时伴随端口错误率升高、CPU利用率飙升或MAC地址表异常增长等关联告警时,系统自动将多类告警归并为单一故障事件,并输出根因分析结果。例如:“接入层交换机A的端口12双工模式降级为半双工,导致该端口下所有终端延迟升高”。
三、故障场景三:流量异常 --- 从“流量波动”到“谁在干什么”
流量异常是三种场景中最具隐蔽性的。带宽占满通常有明确的阈值告警,延迟飙升可通过路径分析快速定位,而流量异常可能表现为:某台终端突然产生大量对外连接(可能是恶意软件C&C通信),某个VLAN内出现了不该有的协议流量(可能是员工私接设备),或者某台服务器的流量模式与历史基线存在显著偏差。
第一步:流量基线学习与异常检测。 OpManager持续学习每个接口、每个设备的流量模式基线,包括日均/周均流量曲线、协议分布比例和源/目的IP分布。当实际流量偏离基线超过预设容限时,系统自动触发异常告警。这种基于机器学习的异常检测能够发现传统规则引擎无法识别的“低振幅但持续”的异常行为。
第二步:协议分布与对话分析。 通过NetFlow/sFlow数据,OpManager可展示每个接口的协议分布(如HTTP占60%、HTTPS占25%、DNS占10%、其他5%)。当某种协议的占比出现异常偏离时——例如DNS请求量突然增长了10倍——系统自动标记并告警。这可能意味着DNS隧道攻击、僵尸网络活动或配置不当的DNS轮询任务。
第三步:Top会话与Top通信对分析。 OpManager提取流量最大的通信对(源IP-目的IP对)和会话列表,帮助运维人员快速识别异常的通信模式。例如:发现某台终端同时与数百个外部IP建立连接——这几乎一定是恶意软件活动或被攻陷的信号。运维人员可在异常确认后,通过OpManager的自动化工作流直接执行响应动作:隔离受感染终端、修改交换机端口配置或联动防火墙阻断异常流量。
关于网络可视化如何帮助运维团队直观呈现流量异常的传播路径,敬请期待本系列第五篇《网络运维可视化三层论》。
四、局域网性能监控的三个常见误区
误区一:只看带宽利用率就够了。 很多运维团队将带宽利用率作为唯一的性能指标,忽略了延迟、丢包率、错误率和抖动等同样关键的指标。高带宽利用率不等于性能问题(可能是正常的业务高峰),低带宽利用率也不等于没有问题(可能是微秒级的延迟抖动导致实时应用异常)。OpManager建议对关键链路同时监控延迟、丢包率、带宽利用率和错误率四大核心指标。
误区二:所有链路都用相同的监控阈值。 不同链路的性能基线差异巨大:服务器接入端口可能常年维持在50%以上的带宽利用率,而管理VLAN的链路利用率可能低于5%。一刀切的固定阈值要么导致大量误报(对高负载链路),要么漏掉真正的异常(对低负载链路)。OpManager的自适应阈值机制为每条链路生成个性化的动态基线,从根本上解决了这个问题。
误区三:发现流量异常后手动处理就够了。 流量异常的处理时效直接影响安全事件的损失程度。从发现异常到手动定位再到手动响应,整个过程可能需要数小时。OpManager的工作流自动化引擎支持在流量异常告警触发后自动执行预设响应动作——从发现到响应的时间可从小时级压缩到分钟级。
五、局域网监控工具选型的四个关键指标
企业在评估局域网监控工具时,建议重点关注:
- 设备兼容性: 确认平台是否支持企业现有的全部网络设备厂商和型号。OpManager支持200+厂商的300+设备型号,预置300个设备模板
- 流量分析深度: 确认是否支持NetFlow/sFlow等流量协议,能否提供协议级和会话级的分析能力
- 告警关联能力: 确认平台能否自动关联多类告警并输出根因分析,避免运维人员手动排查
- 自动化响应深度: 确认平台是否支持在告警触发后自动执行响应动作(如端口隔离、配置修改、通知升级)
关于如何从六大维度系统化评估网络监控平台,包括功能覆盖、扩展架构和成本结构,详见《企业网络监控软件选型指南:2026六大决策维度》。
互动话题
你的企业是否也经历过因网络中断导致的重大损失?你是如何从被动救火转向主动预防的?欢迎分享你的故事。
想亲身体验OpManager如何引领智能运维新纪元?它支持30天免费试用(全功能开放),现有用户更新到最新版本即可使用;还能预约1对1演示,看看如何为你的企业构建智能网络监控体系~
- 即刻开始体验!免费下载安装并享30天全功能开放!
- 需要深入交流?预约产品专家一对一定制化演示!
- 获取报价?填写信息获取官方专属报价!
- 想了解更多?点击进入OpManager官网并查看更多内容!
- 倾向云版本?Site24*7云上一体化解决方案!
常见问题(FAQs)
- OpManager能否监控无线局域网(WLAN)的性能?
答:可以。OpManager支持对主流无线接入点(AP)和无线控制器(WLC)的监控,包括信号强度、客户端数量、频段利用率、信道干扰和无线漫游性能。无线监控数据与有线网络监控数据在统一平台中呈现,帮助运维团队全面掌握局域网性能。
- 如何判断局域网带宽占满是正常业务负载还是异常行为?
答:通过OpManager的流量趋势对比功能,将当前带宽曲线与历史同期基线叠加分析。如果当前带宽利用率显著超出历史同期范围,或流量模式出现异常变化(如非工作时间出现大量传输),系统自动标记为“异常流量”。运维团队可进一步通过NetFlow分析查看具体流量来源和协议。
- OpManager的网络路径分析功能是否支持多协议环境?
答:支持。OpManager的网络路径分析基于ICMP、SNMP和NetFlow/sFlow数据,可跨多种网络协议和设备类型进行逐跳延迟测量。无论网络设备是Cisco、Huawei、H3C还是Juniper,均可在统一界面中查看端到端路径性能。
- 局域网延迟波动应该设置多大的告警阈值?
答:不建议使用固定阈值。OpManager的自适应阈值功能基于机器学习为每条链路生成个性化的动态基线,当延迟偏离基线超过容限时触发告警。对于关键业务链路,建议将容限设为基线的1.5-2倍;对于一般链路,可设为2-3倍。
- OpManager能否识别局域网中的环路?
答:可以。OpManager通过监控STP(生成树协议)状态和广播流量模式,可识别因STP配置不当导致的二层环路。当检测到广播风暴(广播包数量异常增长)时,系统自动告警并在拓扑图上标记可疑的环路路径。



