【2026最新】又一次全球宕机:90%企业都忽略的5个运维致命问题(附解决方案)
AI 摘要
全球宕机频发的背后,90%企业存在5大运维致命问题:监控无效、配置变更失控、拓扑不可视、告警滞后、工具割裂。解决方案需构建统一网络监控平台,实现自动拓扑可视化、智能告警、变更监控与运维闭环。OpManager作为一体化平台,提供统一监控、自动拓扑、智能告警、快速根因分析与自动化运维,帮助企业从被动救火转向主动预防,真正避免反复踩坑。
在过去几年里,"全球宕机"已经不再是偶发事件,而是频繁登上热搜的行业常态。
从云服务异常,到大规模网站不可访问,再到企业内部系统瘫痪——这些问题背后,并不是技术不够先进,而是一个更现实的问题:
👉 大多数企业的运维体系,仍停留在"表面监控"阶段
那么问题来了:
为什么企业总是在同一个地方反复跌倒?
为什么已经部署了网络监控软件,依然无法避免系统宕机?
这篇文章,将从真实运维问题出发,拆解5大核心原因 + 企业可落地的解决方案。



一、为什么"全球宕机"越来越频繁?
在传统IT架构中,系统结构相对简单,故障往往是"单点问题"。
但在今天:
- 多云架构成为主流
- 微服务数量爆炸增长
- 网络依赖关系极度复杂
👉 一个微小问题,就可能引发连锁反应
这就是典型的:
👉 级联故障(Cascading Failure)
二、90%企业忽略的5大运维致命问题
1️⃣ 监控很多,但没有"有效监控"
很多企业已经部署了网络监控软件,但依然存在:
- 告警数量过多(告警风暴)
- 数据分散(多个系统割裂)
- 无法判断问题优先级
👉 结论:监控≠可用的监控
常见表现:
- 故障发生后才发现异常
- 运维人员需要人工筛选告警
2️⃣ 配置变更失控(最大隐患)
大量真实事故表明:
👉 超过70%的故障源于人为变更
包括:
- 网络设备配置错误
- 权限策略调整
- 系统升级问题
但大多数企业却缺乏:
- 变更记录
- 实时监控
- 风险评估机制
3️⃣ 网络拓扑不可视(定位靠猜)
企业常见问题:
- 网络结构靠文档维护
- 设备关系不清晰
- 故障路径不可追踪
👉 结果:故障定位时间大幅延长
4️⃣ 告警机制滞后(只能"事后报警")
传统监控策略:
- CPU 90% 才报警
- 链路中断才通知
👉 这意味着:
系统已经出问题,才开始处理
5️⃣ 运维工具割裂(没有统一平台)
企业常见现状:
| 模块 | 工具 |
|---|---|
| 网络监控 | A系统 |
| 服务器监控 | B系统 |
| 应用监控 | C系统 |
👉 结果:
- 数据孤岛
- 无法联动
- 故障处理效率低
三、解决方案:如何构建"不会反复踩坑"的运维体系?
要避免系统宕机,关键不是"增加工具",而是升级体系👇
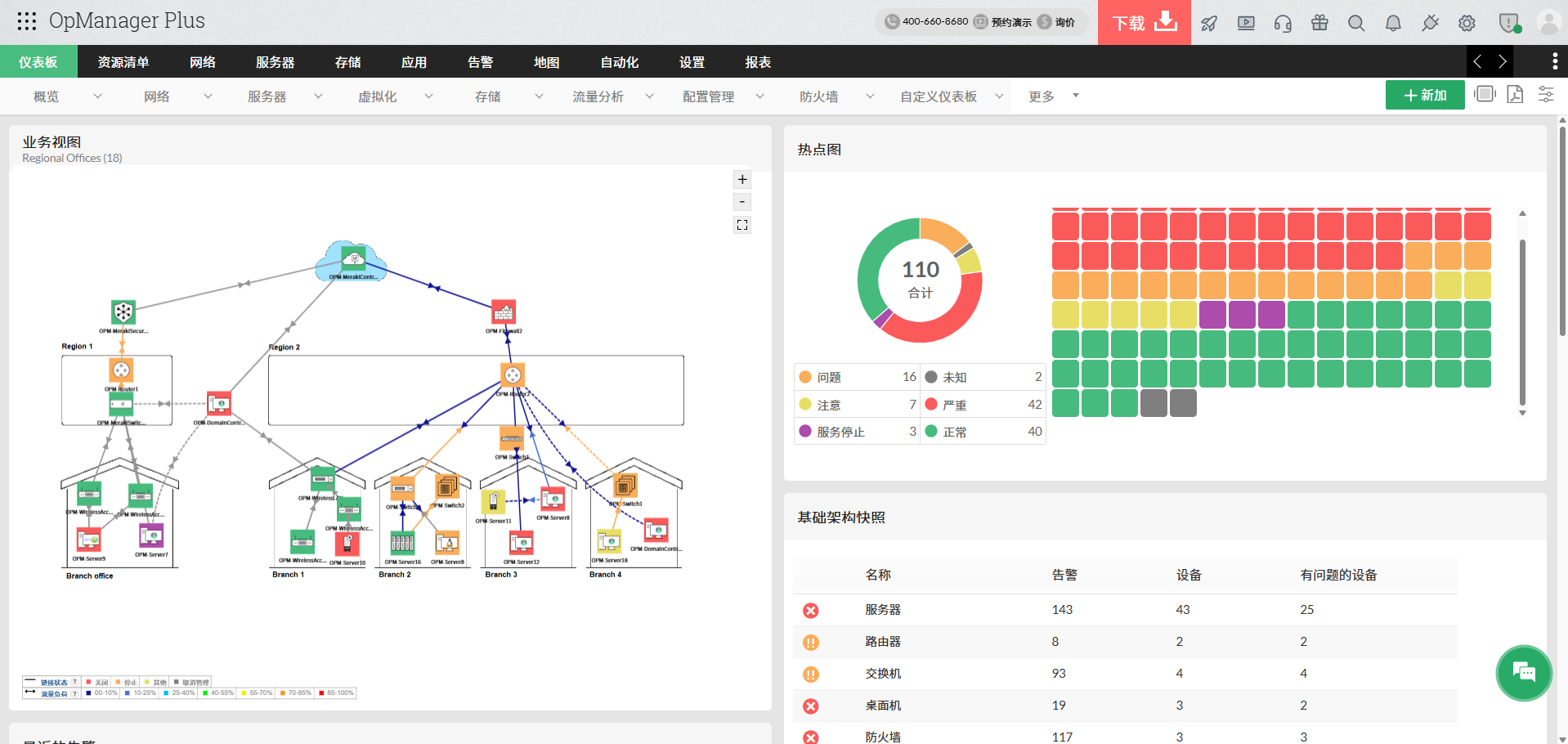
✅ 1. 建立统一的网络监控工具
核心能力:
- 全设备统一监控
- 跨环境管理(本地+云)
- 多协议支持(SNMP、Flow等)
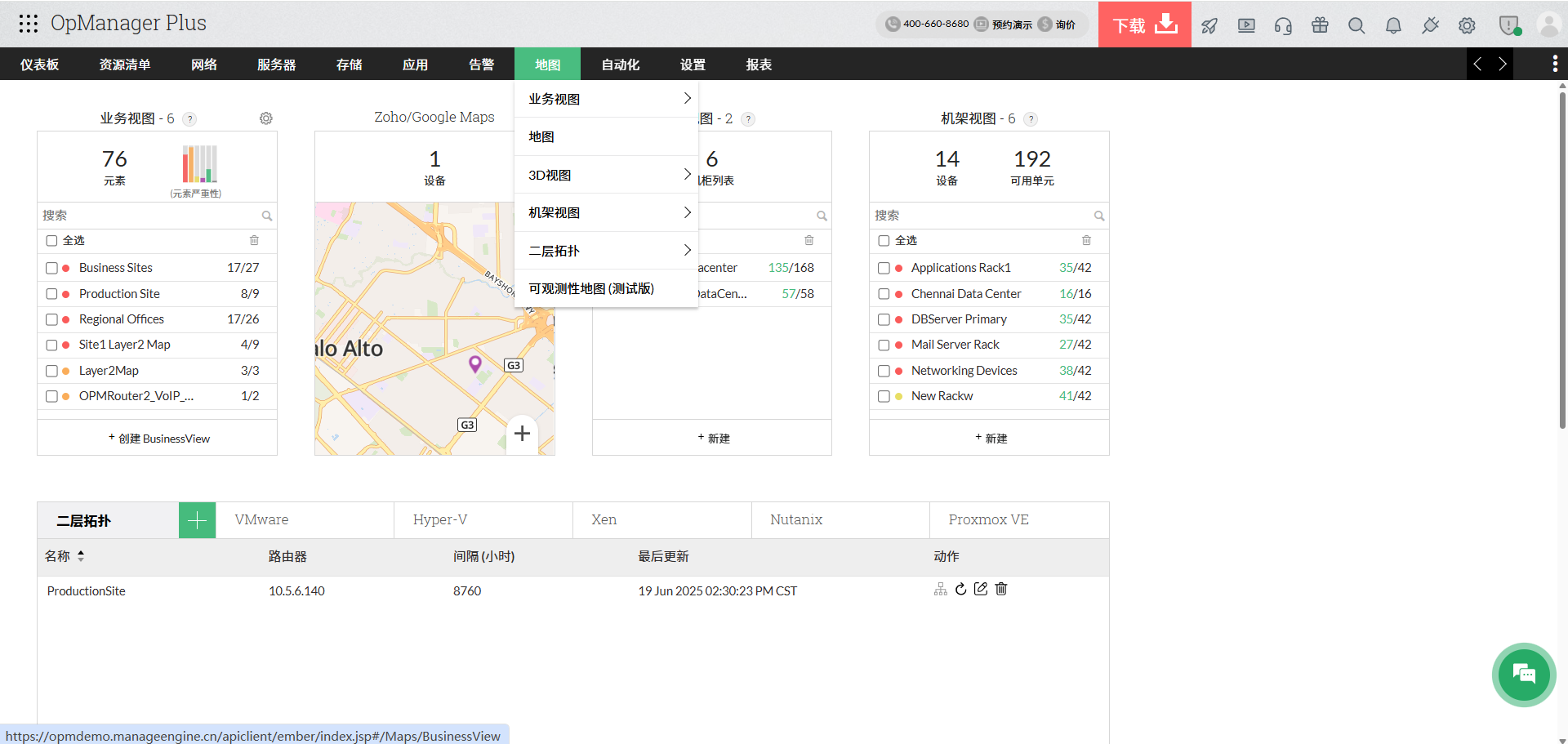
✅ 2. 实现网络拓扑自动可视化
通过自动发现:
- 实时生成网络拓扑
- 展示设备依赖关系
- 标记关键节点
👉 故障定位效率提升数倍
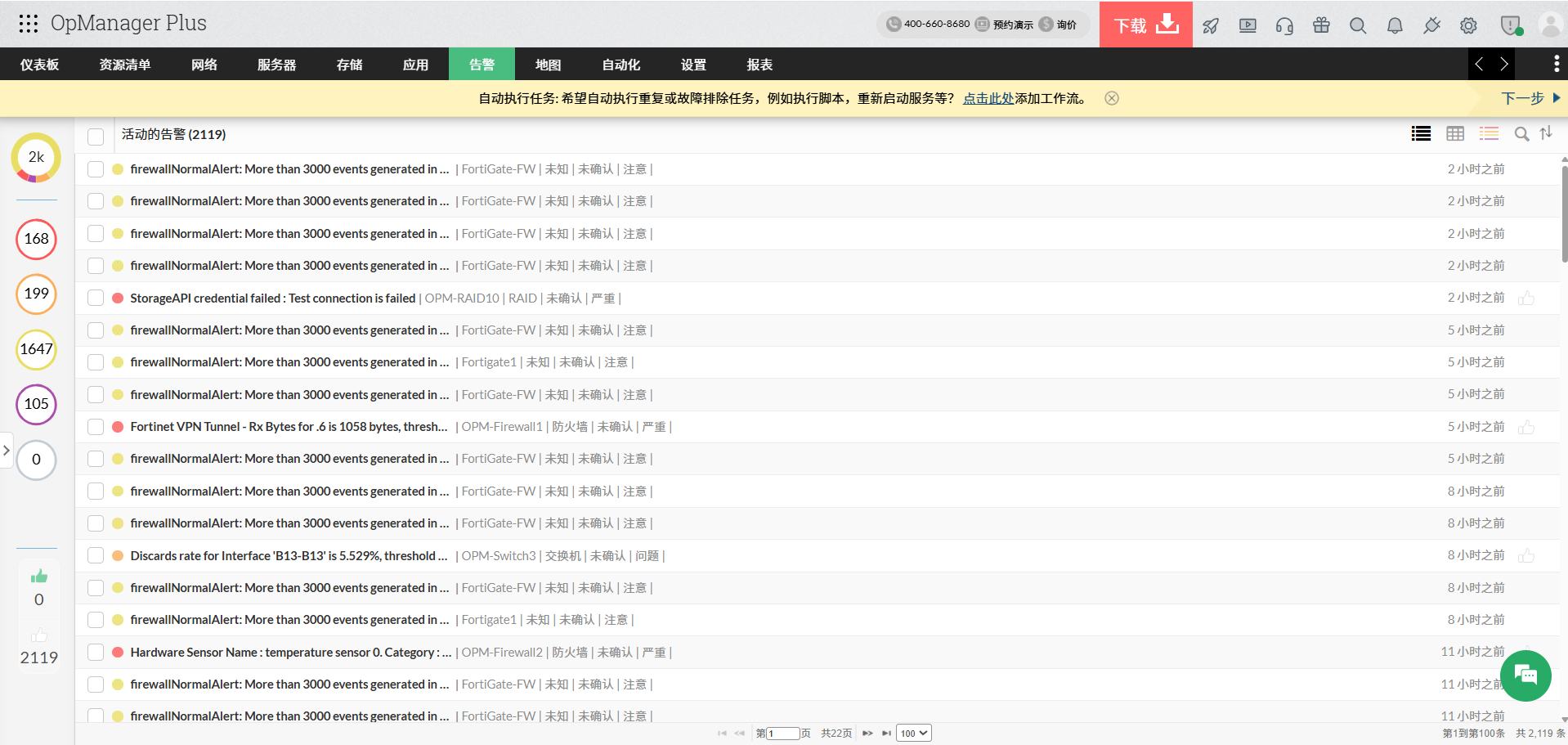
✅ 3. 引入智能告警(减少90%无效告警)
现代网络监控软件应具备:
- 动态阈值
- 告警合并
- 告警关联分析
👉 从"告警泛滥"到"精准告警"
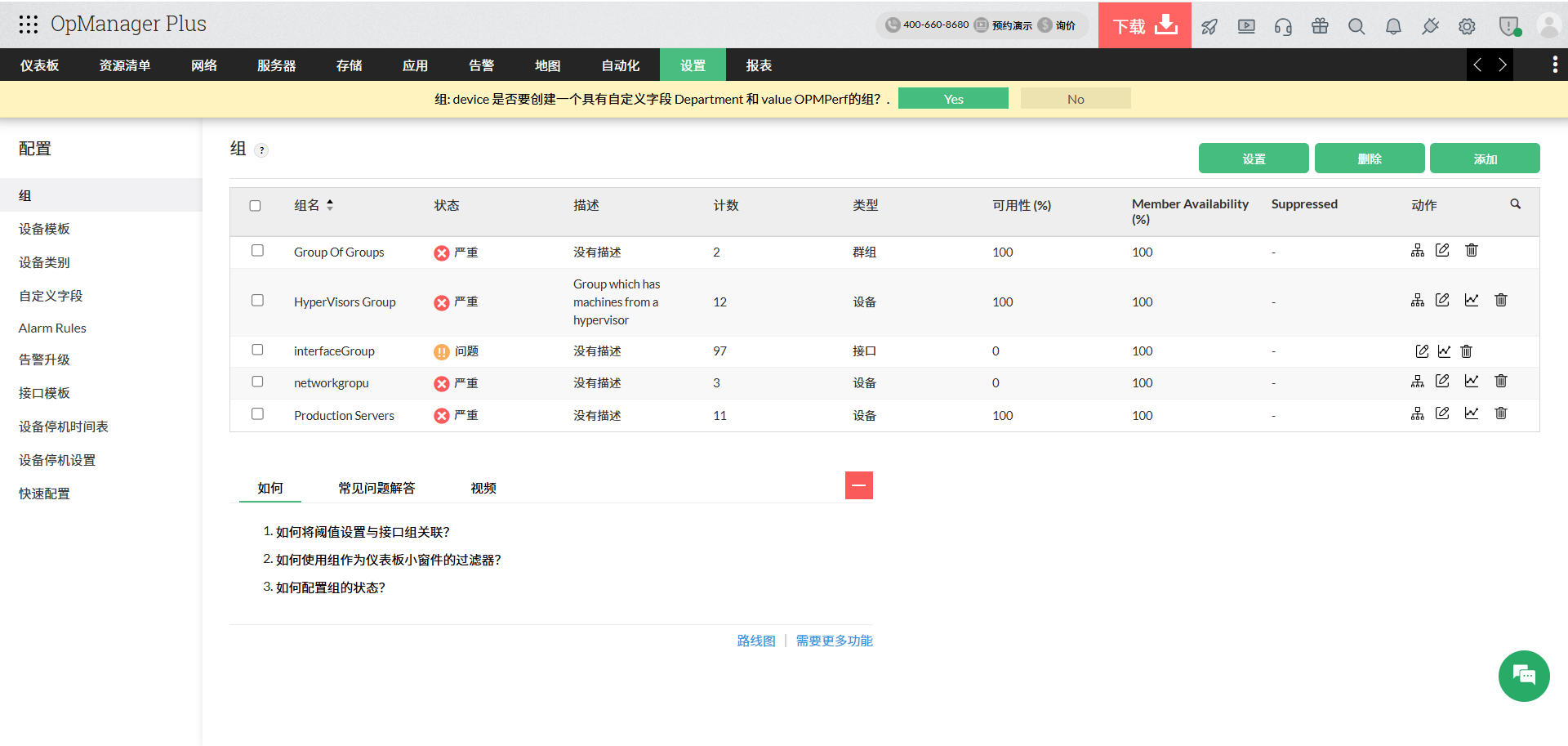
✅ 4. 强化变更监控机制
关键能力:
- 配置变更记录
- 实时异常检测
- 自动回滚支持
👉 避免人为错误扩大
✅ 5. 打造运维闭环(监控 → 处理)
完整流程:
监控 → 告警 → 工单 → 修复 → 复盘
👉 实现真正的运维自动化
四、为什么越来越多企业选择 OpManager?
在众多网络监控软件中,OpManager 之所以受到企业青睐,核心在于:
👉 一体化 + 易落地 + 高性价比
⭐ 核心优势一:统一监控平台
- 网络设备、服务器统一纳管
- 支持多厂商设备
- 集中化运维管理
⭐ 核心优势二:自动拓扑与可视化
- 自动发现设备
- 实时生成网络拓扑图
- 快速定位故障路径
⭐ 核心优势三:智能告警系统
- 多条件触发
- 告警升级机制
- 多渠道通知
⭐ 核心优势四:快速故障定位(降低MTTR)
通过:
- 性能数据
- 拓扑分析
- 历史记录
👉 实现精准根因分析
⭐ 核心优势五:支持自动化运维
- API集成
- 自动化脚本
- ITSM联动
👉 构建完整运维体系
五、企业必须完成的3个转变(重点总结)
🔁 转变1:被动运维 → 主动运维
- 从"事后处理"
- 到"提前预警"
🔁 转变2:工具运维 → 平台运维
- 从多个工具
- 到统一网络监控平台
🔁 转变3:经验驱动 → 数据驱动
- 减少人为判断
- 提高决策准确性
六、结尾总结
每一次"全球宕机",看似是偶发事件,本质上却是:
👉 运维体系不完善的必然结果
如果企业仍然依赖:
- 分散的监控工具
- 被动的告警机制
- 人工经验排障
那么下一次宕机,只是时间问题。
而通过部署专业的网络监控软件,构建统一的网络监控平台,并逐步实现自动化运维与可观测性体系,企业才能真正做到:
👉 提前发现问题、快速定位问题、彻底解决问题
这不仅是技术升级,更是企业IT管理能力的升级。
互动话题
你的企业是否也经历过因网络中断导致的重大损失?你是如何从被动救火转向主动预防的?欢迎分享你的故事。
想亲身体验OpManager如何引领智能运维新纪元?它支持30天免费试用(全功能开放),现有用户更新到最新版本即可使用;还能预约1对1演示,看看如何为你的企业构建智能网络监控体系~
- 即刻开始体验!免费下载安装并享30天全功能开放!
- 需要深入交流?预约产品专家一对一定制化演示!
- 获取报价?填写信息获取官方专属报价!
- 想了解更多?点击进入OpManager官网并查看更多内容!
- 倾向云版本?Site24*7云上一体化解决方案!
常见问题(FAQs)
- 为什么全球宕机事件越来越频繁?
答:现代IT架构呈现多云、微服务、复杂依赖等特点,一个微小问题可能引发级联故障。许多企业的运维体系仍停留在"表面监控"阶段,缺乏有效的统一监控平台和主动预警机制,导致问题被放大。
- 90%企业忽略的5大运维致命问题是什么?
答:包括:①监控多但无效(告警风暴、数据割裂);②配置变更失控(超70%故障源于人为变更);③网络拓扑不可视(定位靠猜);④告警机制滞后(事后报警);⑤运维工具割裂(数据孤岛、无法联动)。
- 如何构建"不会反复踩坑"的运维体系?
答:需要建立统一网络监控平台,实现自动拓扑可视化、智能告警(减少90%无效告警)、强化变更监控与自动回滚、打造运维闭环(监控→告警→工单→修复→复盘),从被动响应转向主动预防。
- OpManager如何帮助企业避免宕机?
答:OpManager提供统一监控平台、自动拓扑与可视化、智能告警系统、快速根因分析、自动化运维能力。通过提前发现问题、精准定位故障、自动执行修复,显著降低MTTR,防止小问题演变成全局宕机。
- 企业实现运维升级需要完成哪三个转变?
答:①被动运维→主动运维(从事后处理到提前预警);②工具运维→平台运维(从多个分散工具到统一网络监控平台);③经验驱动→数据驱动(减少人为判断,提高决策准确性)。



