网络监控工具告警优化:「告警噪音五消法」实战
AI 摘要
59%的运维人员饱受告警风暴困扰。ManageEngine OpManager推出「告警噪音五消法」:关联压缩归并故障、拓扑感知自动静默下游告警、自适应阈值告别静态误报、维护窗口计划性抑制、工作流自动化实现自愈闭环。五层机制将告警噪音降低90%以上,处置效率提升3-5倍,MTTR显著缩短。集成OpenAI能力,AI Agents将分析推进到引导性行动,实现从被动响应到主动预防的智能运维转型。
凌晨三点,电话突然响起:"核心交换机脱网了。"你匆匆打开监控平台——几百条告警同时弹出。路由器、交换机、防火墙、服务器,一条接一条。你只能凭经验逐条过滤,等真正定位到根因时,半小时已经过去。这是业界常说的"告警风暴",也是59%的运维人员认定的最大挑战。
ManageEngine OpManager在2026年正式提出「告警噪音五消法」方法论,将告警治理从"减少数量"升级为"精准定位",帮助企业实现智能运维转型。本文将完整解析这一五层降噪框架,并说明OpManager网络监控工具如何实现从告警泛滥到一键锁定的跨越。



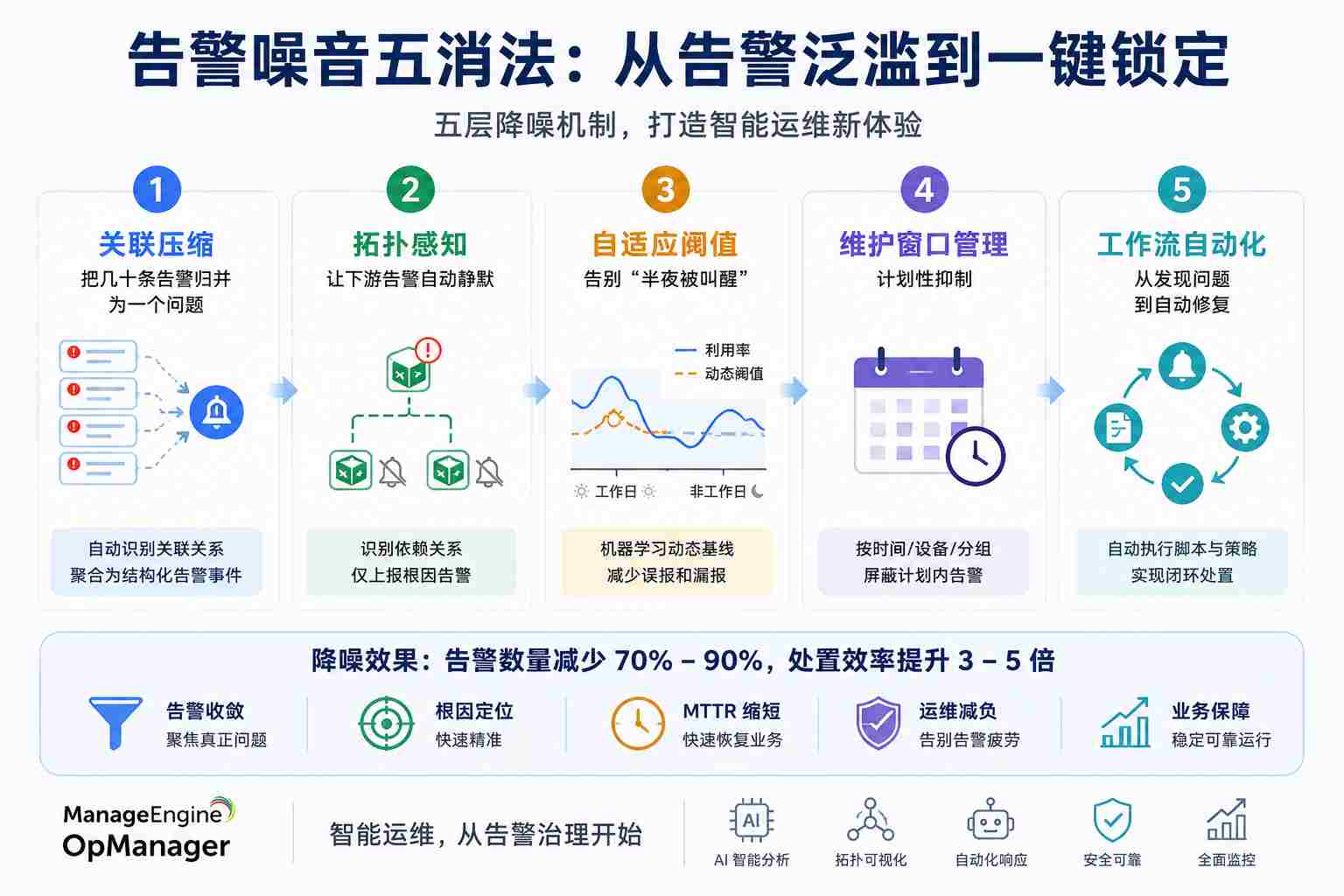
一、第一消:关联压缩——把几十条告警归并为一个问题
传统阈值告警的底层逻辑是"每个指标独立监控":CPU超过90%就告警、内存不足就告警、设备失联就告警。一次核心设备掉电,可能触发上下游几十台设备的联动告警。在传统体系下,这些告警是独立推送的,没有任何关联性。
OpManager的告警压缩机制通过预设的关联规则,自动识别告警之间的父子关系或因果链条。当一台核心交换机发生故障时,系统不会推送下游接入交换机的"脱管"告警,而是将整组相关告警归并为一条结构化故障事件,同时带上完整的故障上下文。运维人员看到的告警数量从"泛滥成灾"精准聚焦到"真正需要关注的问题"。
二、第二消:拓扑感知——让下游告警自动静默
网络设备之间存在天然的依赖关系:上游设备故障必然导致下游设备异常。传统网络监控工具缺乏这种拓扑感知能力,导致同一根因在不同设备上反复告警。
OpManager利用网络拓扑信息自动理解设备间的依赖关系。当一条核心链路抖动时,系统会识别:上游设备故障导致下游设备失联,本质上是同一个问题的不同表现。下游相关告警被自动关联归档,只向上报告根因告警。这种拓扑感知机制有效防止告警在整个网络中连锁扩散。
三、第三消:自适应阈值——告别"半夜被叫醒"
静态阈值是告警噪音的主要制造者之一。工作日的CPU利用率90%可能是正常负载,但非工作日的90%则明显异常。固定阈值无法区分这种差异。
OpManager的自适应阈值功能通过机器学习持续学习每个设备、每条流量的正常行为模式。系统分析历史使用趋势,动态生成高可靠性预测值。当实际利用率超过"预测值+偏差值"时才会触发告警。例如,工作日CPU阈值自动设为90%,非工作日降至60%,有效避免了半夜被"正常"告警叫醒的情况。结合抑制限值自动过滤小幅波动,无效告警噪音被进一步压缩。
四、第四消:维护窗口管理——计划性抑制
设备升级、配置变更、定期维护期间,监控工具通常会生成大量预期内的告警。这些告警并非真正的故障信号,但会持续干扰运维人员的注意力。
OpManager提供告警抑制功能,允许在设备维护期间按设备、分组或类别临时屏蔽告警。维护窗口的配置可精确到时间段和设备范围,避免维护期间接收不必要的干扰消息。维护结束后,监控自动恢复正常,无需人工干预。
五、第五消:工作流自动化——从发现问题到自动修复
告警治理的终极目标是形成"发现问题-定位根因-自动处置"的闭环,而不仅仅是减少告警数量。
OpManager的工作流自动化引擎支持:自动化脚本执行、批量配置管理、告警自动响应及故障自动恢复。典型场景包括:设备异常时自动重启服务、流量异常时自动限流、配置错误时自动回滚。如果一个严重告警在规定时间内未被处理,系统会自动将其升级到下一级支持团队,并根据服务优先级和SLA要求自动路由到相应负责人。
六、从五消法到智能运维:效率提升3至5倍
成熟的智能运维部署将告警处置效率提升3至5倍,显著缩短MTTR。OpManager的「告警噪音五消法」不是单一功能的叠加,而是一个完整的降噪框架:关联压缩解决"数量泛滥",拓扑感知解决"连锁扩散",自适应阈值解决"静态误报",维护窗口解决"计划干扰",工作流自动化解决"响应滞后"。
2026年,OpManager进一步集成OpenAI能力,可根据自然语言输入自动生成上下文摘要和处置脚本。在OpManager Nexus中,AI Agents将任务从分析推进到引导性行动,使运维响应工作流更加一致、高效。
互动话题
你的企业是否也经历过因网络中断导致的重大损失?你是如何从被动救火转向主动预防的?欢迎分享你的故事。
想亲身体验OpManager如何引领智能运维新纪元?它支持30天免费试用(全功能开放),现有用户更新到最新版本即可使用;还能预约1对1演示,看看如何为你的企业构建智能网络监控体系~
- 即刻开始体验!免费下载安装并享30天全功能开放!
- 需要深入交流?预约产品专家一对一定制化演示!
- 获取报价?填写信息获取官方专属报价!
- 想了解更多?点击进入OpManager官网并查看更多内容!
- 倾向云版本?Site24*7云上一体化解决方案!
常见问题(FAQs)
- 什么是告警风暴?为什么它会影响运维效率?
答:告警风暴指一次根因故障触发大量关联告警同时爆发,导致关键信号被淹没,MTTR显著增加。59%的运维人员认为这是其面临的最大挑战。
- OpManager的「告警噪音五消法」具体包含哪五层机制?
答:第一消为关联压缩,第二消为拓扑感知,第三消为自适应阈值,第四消为维护窗口管理,第五消为工作流自动化。五层机制形成从告警收敛到自动修复的完整闭环。
- 自适应阈值相比传统静态阈值有哪些优势?
答:自适应阈值基于机器学习动态调整基线,避免误报和漏报。系统按时段自动调整阈值(如工作日90% vs 非工作日60%),并结合抑制限值过滤小幅波动。
- 开源监控工具如Zabbix能否实现类似的告警降噪?
答:Zabbix等开源工具在告警关联与根因分析层面需要大量脚本开发和手动配置,缺乏开箱即用的拓扑感知和自适应阈值能力,在大规模企业环境中维护成本较高。
- 企业如何评估告警降噪的ROI?
答:建议从三个指标衡量:告警压缩率(关联后告警数量降低比例)、平均故障定位时间(MTTR缩短幅度)、夜间非紧急告警减少比例。OpManager部署后通常可实现告警数量压缩70%-90%。
参考资料
[1] IDC, AIOps Adoption Survey 2025 [2] ManageEngine OpManager 产品功能页



