OpManager 中的自适应阈值

自适应阈值通过使用 OpManager 基于机器学习的预测算法,动态修改关键监视器的阈值,帮助用户优化告警效率。它通过分析数据模式并调整阈值,以减少误报,同时确保关键问题能够被检测到,从而消除手动干预的需要。
随着时间推移,它会学习识别每小时、每天、每周甚至每月的周期,并自动调整阈值以匹配这些重复出现的模式。这样可以确保诸如每日流量高峰、每周维护活动或月末处理负载等可预测的波动不会产生不必要的告警,同时仍然能够突出真正的异常情况。
OpManager 的自适应阈值如何工作?
启用自适应阈值后,OpManager 会从所有监视器采集必要的性能数据,并将其输入到先进的预测算法中。数据采集的最短周期为 14 天。
- 算法会分析记录的数据,并在考虑每一个数值和模式的情况下生成相应的阈值。
- 当 OpManager 至少拥有所选监视器 14 天的数据后,就会最终确定数据模式,并开始对这些监视器应用预测阈值。
- 在启用自适应阈值时,OpManager 会从用户处获取所谓的“偏差值”。这些值决定在触发告警前,被轮询到的数值可以偏离多少。
- 共有三个偏差值,分别对应三个严重性级别:注意、故障和严重。这些值可以配置为百分比或固定值,并可按增大或减小方向配置。
动态自适应
传统上,OpManager 使用最近 14 天的数据来开始生成告警。当首次启用自适应阈值功能时,这可能会在触发告警方面造成轻微延迟。但随着 OpManager 运行时间越长,它会收集到足够的历史数据,用于检测和适应周期性出现的每周和每月模式。这使得 OpManager 能够自动调整那些按照固定计划发生的活动(如每周维护窗口或月末交易高峰)的阈值。
- OpManager 会针对每小时与每日的变化动态调整阈值,例如在业务高峰时段 CPU 使用率较高,或在非工作时间活动量较低的情况。
- 如果每周会发生周期性活动,例如每周五晚的计划维护,或每周一下午 CPU 利用率升高,OpManager 会针对该特定时间窗口相应调整阈值。
- 随着数据采集时间的延长,OpManager 能检测到每月的业务高峰并自动调整阈值。
示例: 对于企业而言,网络使用情况在一周内通常会有所变化:周末活动较少,而周一上午负载较高。起初,这些波动可能会被误判为异常并触发误报。观察到这些历史数据后,OpManager 会自动进行自适应调整,使阈值匹配这些可预测的变化。
在自适应阈值模式下如何计算阈值?
对于每一个小时,OpManager 的预测算法都会基于此前观察到的数据模式和行为给出预测值,并在此基础上应用用户配置的偏差值。例如,考虑以下偏差值。
请注意,偏差既可以用具体数值表示,也可以用百分比表示。我们通过一个示例进行说明。
| 注意 | 故障 | 严重 |
|---|---|---|
| 5 | 8 | 15 |
我们可以按如下所述,通过数值或百分比来配置偏差值。
1. 按数值配置偏差:如果某设备在当天第一个小时(0:00 - 1:00)的 CPU 利用率预测值为 34,那么触发“注意”级别告警的对应数值为 34+5=39(预测值 + 注意级偏差值)。同样,故障和严重级别的数值也会在每个小时被计算出来。对于 5 个连续小时,在不同预测值下计算得到的数值如下:
| 时间段 | 预测值 | 注意值 | 故障值 | 严重值 |
|---|---|---|---|---|
| 0:00 - 1:00 | 34 | 39 | 42 | 49 |
| 1:00 - 2:00 | 36 | 41 | 44 | 51 |
| 2:00 - 3:00 | 44 | 49 | 52 | 59 |
| 3:00 - 4:00 | 58 | 63 | 66 | 73 |
| 4:00 - 5:00 | 54 | 59 | 62 | 69 |
2. 按百分比配置偏差:如果某设备在当天第一个小时(0:00 - 1:00)的 CPU 利用率预测值为 34,那么触发“注意”级别告警的对应数值为 34 + (34 的 5%) = 36(预测值 + 预测值的注意级偏差百分比)。同样,故障和严重级别的数值也会在每个小时被计算出来。对于 5 个连续小时,在不同预测值下计算得到的数值如下:
| 时间段 | 预测值 | 注意值 | 故障值 | 严重值 |
|---|---|---|---|---|
| 0:00 - 1:00 | 34 | 36 | 37 | 39 |
| 1:00 - 2:00 | 36 | 38 | 39 | 41 |
| 2:00 - 3:00 | 44 | 46 | 48 | 51 |
| 3:00 - 4:00 | 58 | 61 | 63 | 67 |
| 4:00 - 5:00 | 54 | 57 | 58 | 62 |
3. 高级配置:除了偏差值之外,OpManager 还提供以下选项以定制告警行为。
抑制上限:配置一个数值,低于该数值的告警会被自动抑制,从而避免因轻微偏差产生不必要的告警。
示例: 如果 CPU 利用率配置的自适应阈值为 50,同时你配置了一个 52 的抑制上限,那么任何实际值低于 52 时都不会触发告警。
静态上限:定义一个固定的上限阈值,一旦被突破,无论当前配置的自适应阈值为何,都会触发告警。
示例: 如果你为 CPU 利用率设置了 90 的静态上限,当使用率达到或超过 90 时,会立即触发告警,即便此时的自适应阈值更高。
配置步骤:
- 导航至 Settings > Monitoring > Adaptive Threshold。
- 选择 Enabled Monitors 选项。
- 在对应监视器或性能组的 Action 列中,点击 Edit 图标。
- 设置所需的 Suppress Limits、Static Limits 和 Deviation Values。
启用自适应阈值
在启用自适应阈值选项之前,请注意:
- 该功能目前适用于 OpManager 中的所有性能监视器。
- OpManager 需要至少 14 天的性能数据,才能成功建立数据模式并生成模型。如果你添加了新设备并希望立即开始监控,可以在此期间使用手动阈值。
- 必须先在全局范围启用自适应阈值功能,它才会在其他页面作为可用选项出现。如果在全局范围被禁用,则在整个 OpManager 中只能配置手动阈值。
- 此外,如果从设备模板中启用了自适应阈值,那么之后按照该设备模板发现的所有设备,其监视器默认都会启用自适应阈值。
可通过 Settings -> Monitoring -> Adaptive Threshold 页面在整个 OpManager 中全局启用自适应阈值。前往该页面并启用“Enable Adaptive Threshold”选项。你也可以在各自的性能监视器、性能组或设备模板中单独启用自适应阈值,并将偏差级别定义为数值或百分比。
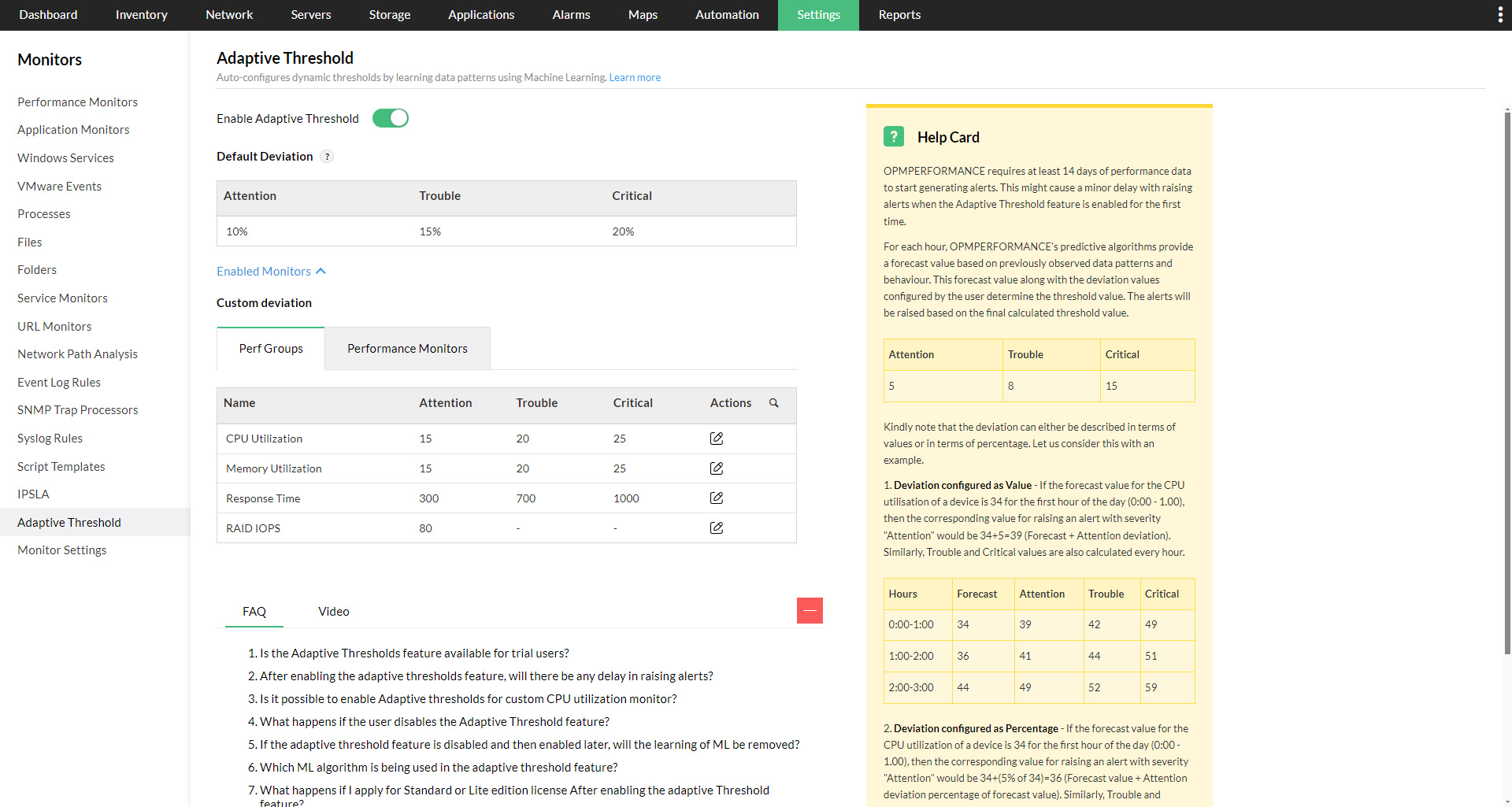
启用后,可以根据需求在不同层级进行控制:
- 在 OpManager 全局的监视器或性能组层级启用:
- 你也可以为在 OpManager 中使用的某个特定监视器启用自适应阈值。只需前往 Settings > Monitoring 下的 Performance Monitors 页面,找到你希望启用自适应阈值的监视器,然后点击 Edit。
- 启用 Adaptive Thresholds 选项,配置偏差值,然后点击 OK 保存。
- 通过设备模板启用:
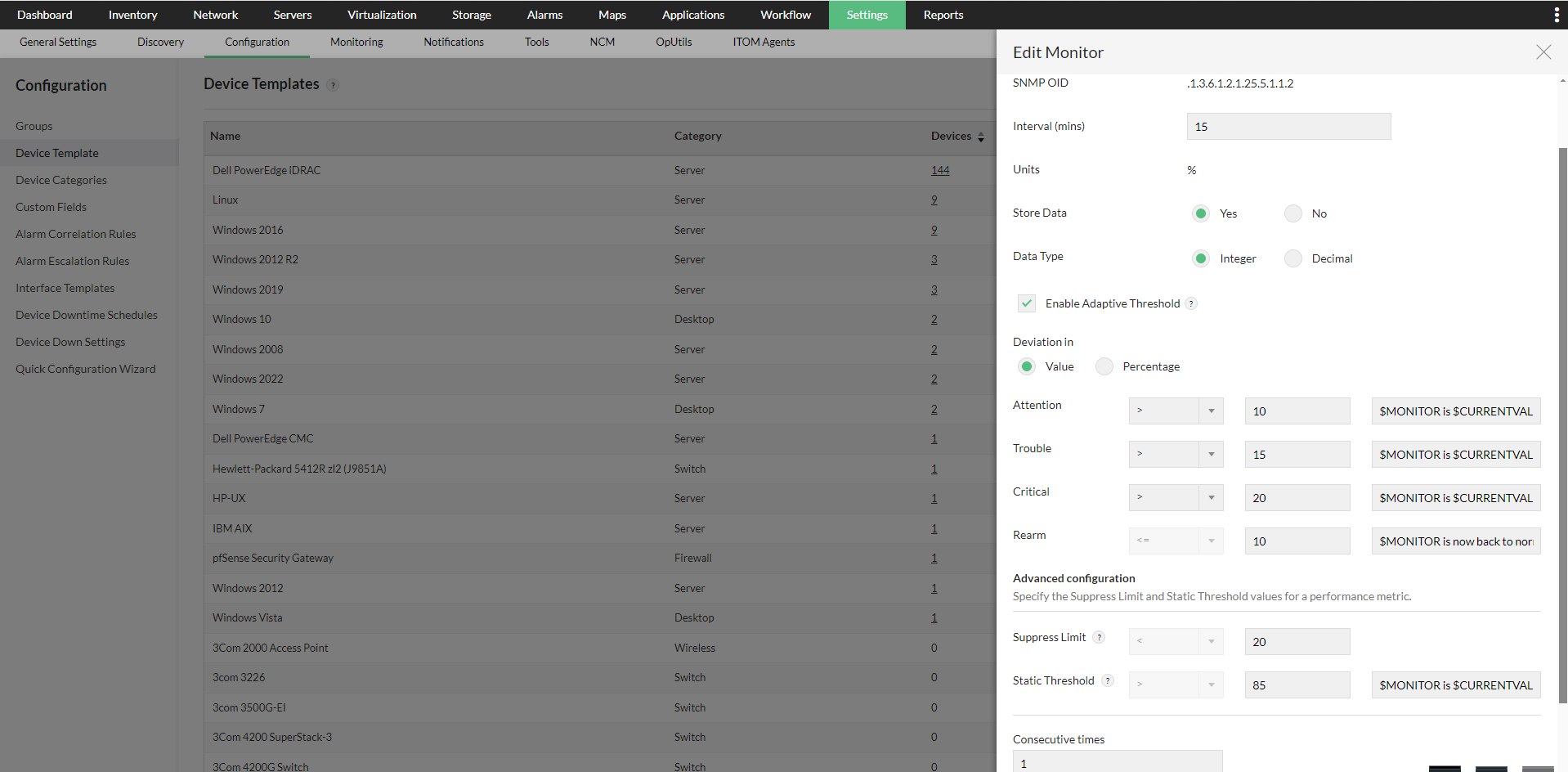
- 我们也可以通过设备模板为监视器启用自适应阈值,其步骤与在监视器层级配置类似。
- 前往 Settings -> Configuration -> Device Templates,选择合适的模板,然后点击任一受支持的监视器以启用自适应阈值。配置偏差值后,点击 OK 保存更改。
- 若要将此更改直接应用到该模板下的设备,请点击 Save and Associate。选择你要应用更改的设备,然后点击 Associate and Overwrite 以应用这些更改。
- 如果只希望将该阈值变更应用到将来新发现的设备,仅需点击“Save”即可。
- 在设备快照页面启用自适应阈值:
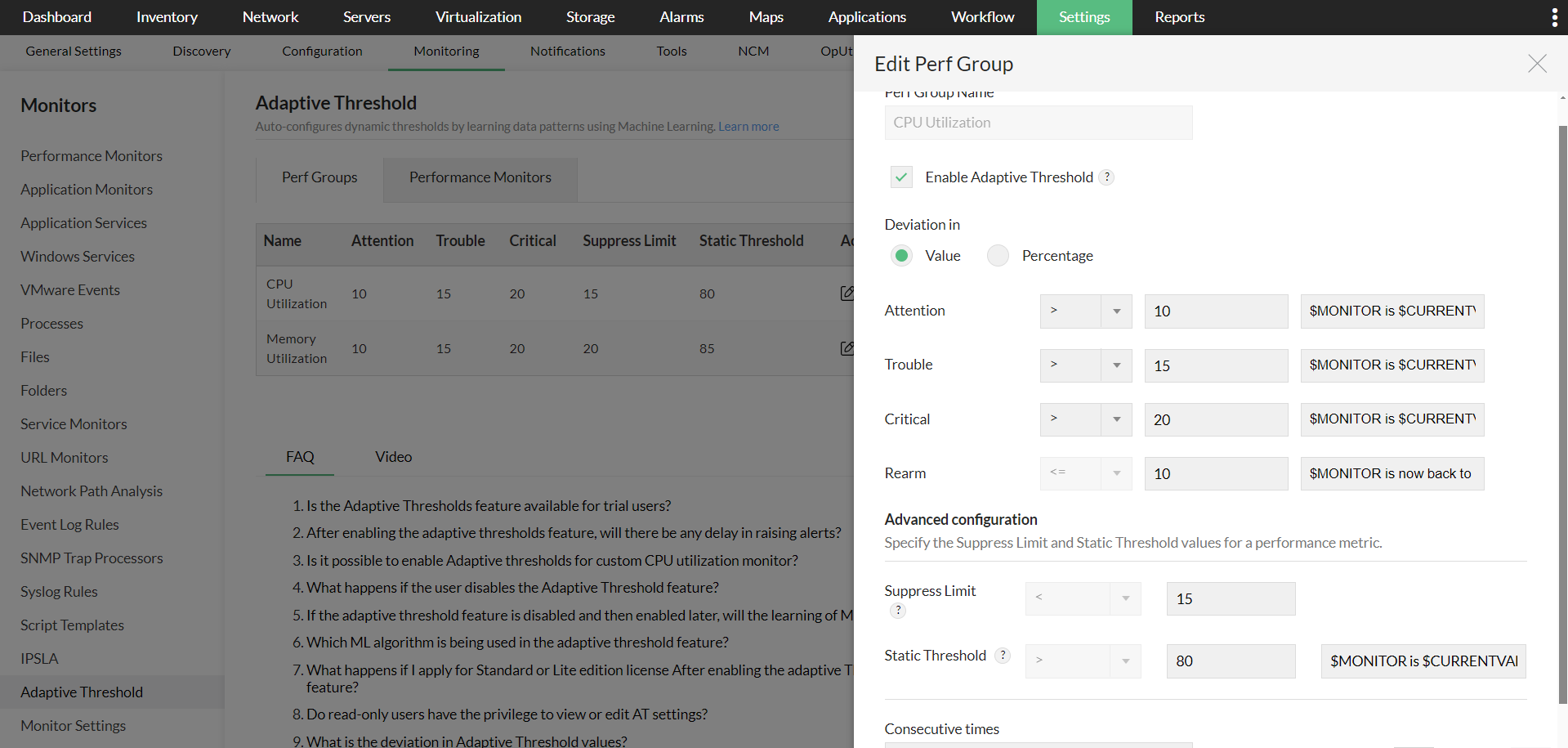
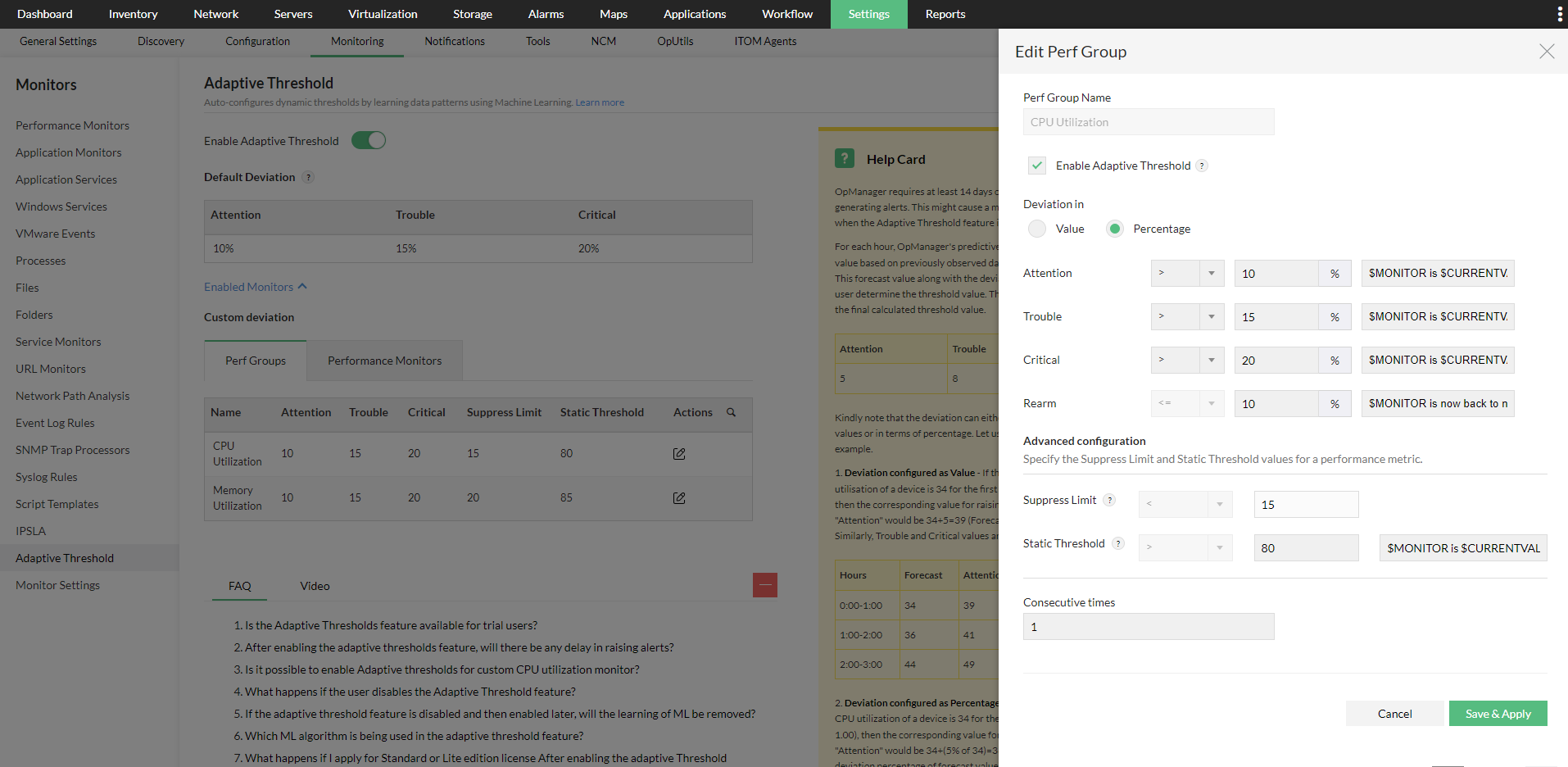
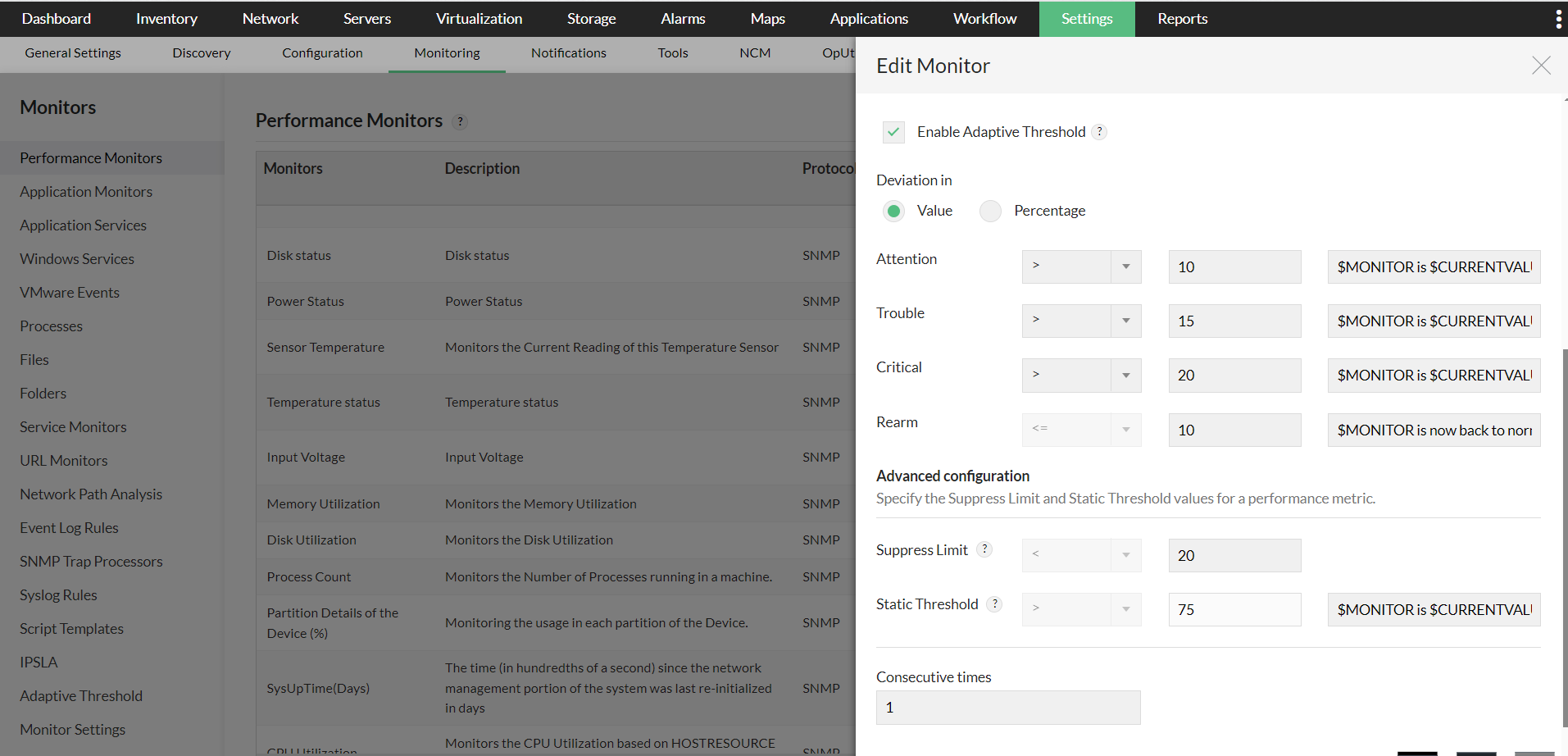
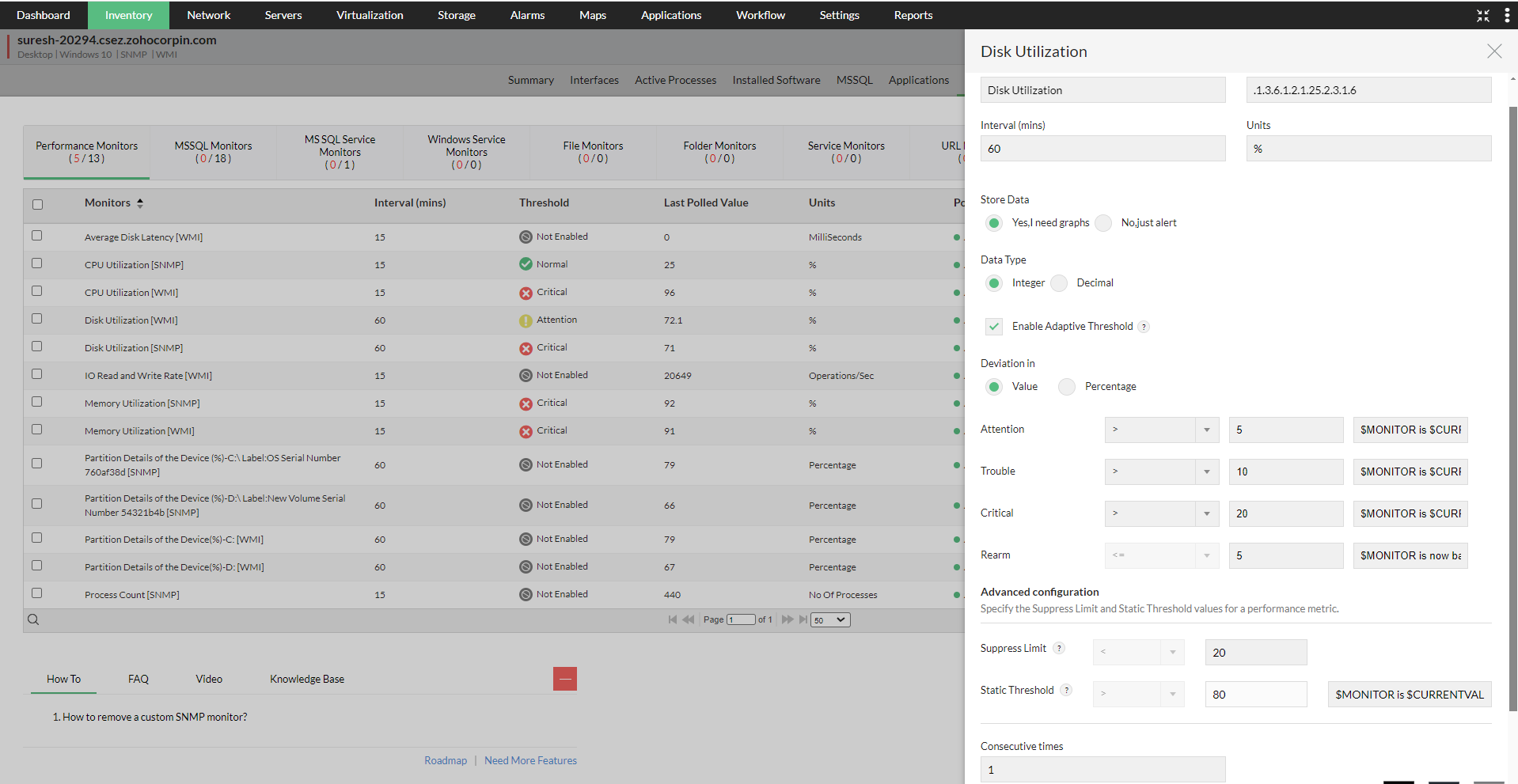
- 当只需为少量设备启用/禁用自适应阈值时,此方法非常实用。
- 只需进入相应设备的 Device Snapshot 页面,导航到任一受支持的监视器,点击 Edit 并启用 Adaptive Thresholds 选项。
- 在 Deviation 标题下选择数值或百分比(value 或 percentage)单选按钮,然后输入相应的数值。
- 点击 Save 将更改应用到你的监视器。OpManager 在拥有足够供算法使用的数据(至少 14 天)后,会开始预测阈值。
感谢您的反馈!