统一基础设施可观测性
端到端基础设施监控与遥测关联
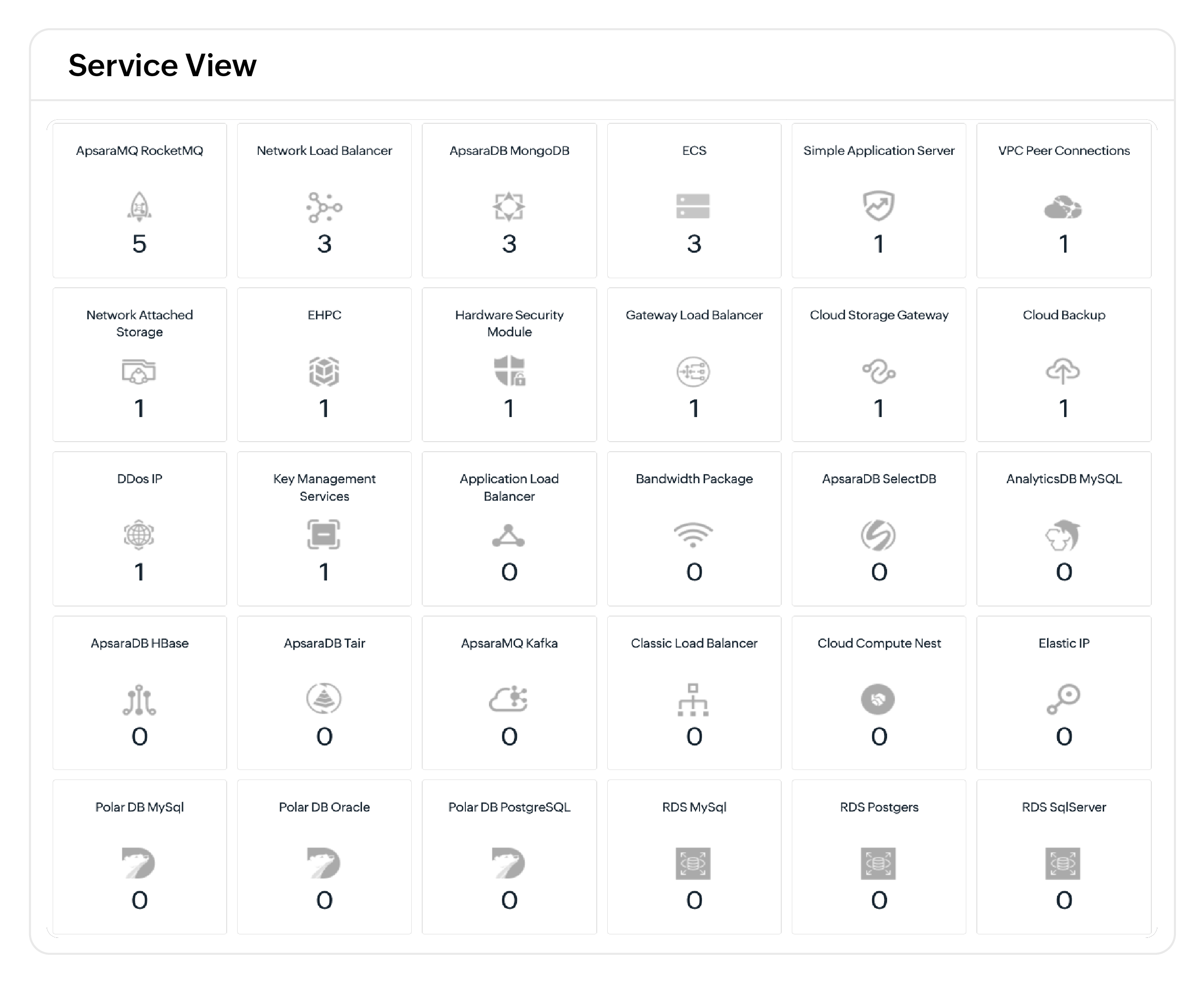
ManageEngine 在资源上线的第一时间即开始映射您的阿里云环境。无需代理,无需手动发现,仅需通过单一控制台即可立即获得每一服务层的完整可见性,自动发现资源并提供即时可见性。
- 跨层统一可见性:统一监控计算、网络、存储和托管服务,关联指标和事件,了解问题如何影响您的环境。
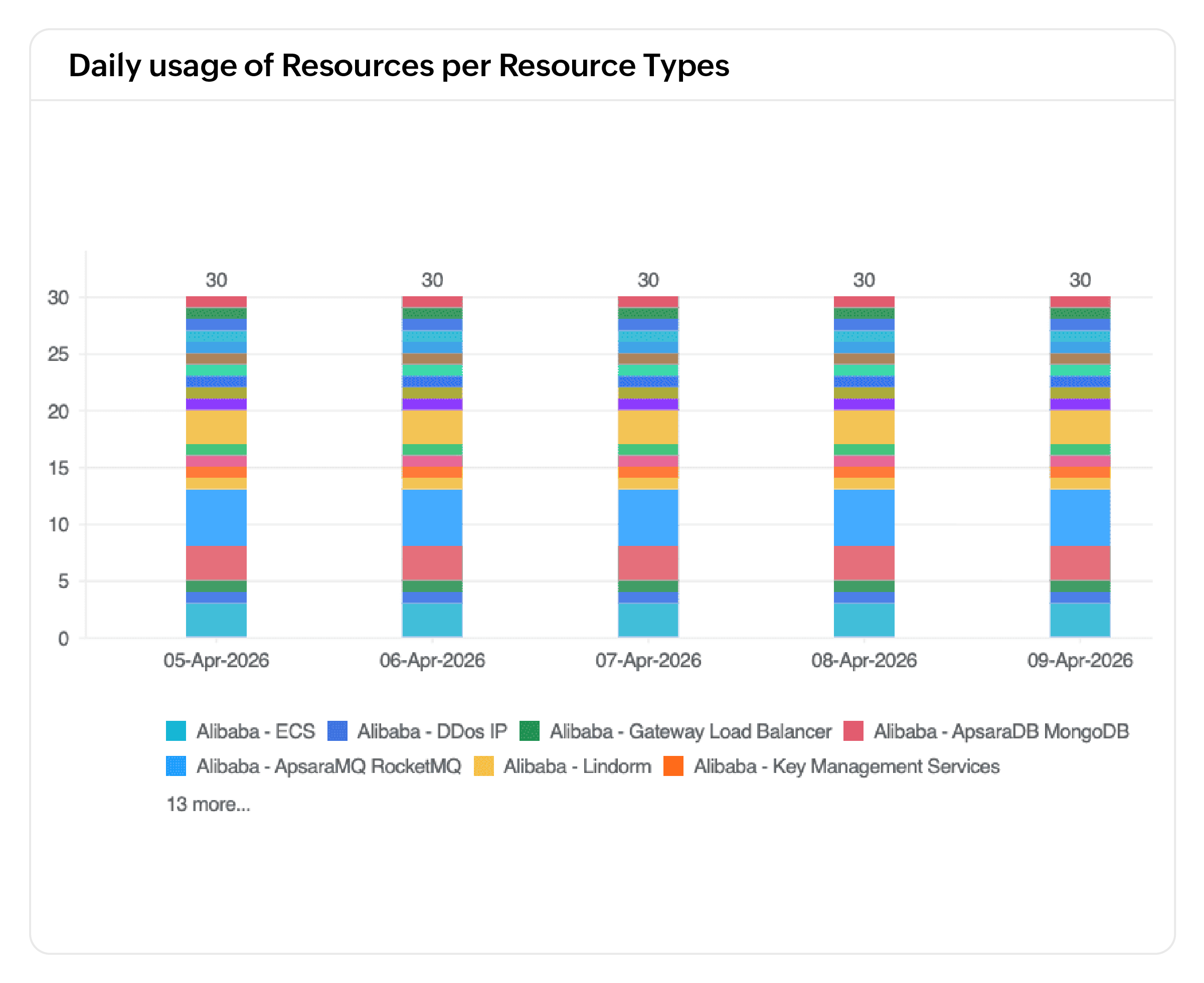
- 性能与可用性跟踪:跟踪 ECS 实例的 CPU、内存、磁盘 I/O 和网络吞吐量。监控 NLB、ALB 和 CLB 的请求速率和连接数、VPC 流量以及托管服务可用性,及早发现瓶颈和中断。
- 加速根因分析:追踪请求从 NLB 和 ALB 到后端 ECS 实例的路径,并分析历史数据,精确定位故障根源。
事故智能
借助 AI 更快解决阿里云事故
阿里云事故很少局限于单一服务边界内。数据库变慢会导致负载均衡器超时,进而引发应用程序故障。ManageEngine 运用 AI 驱动的分析关联这些事件,在影响范围扩大之前浮出根因。
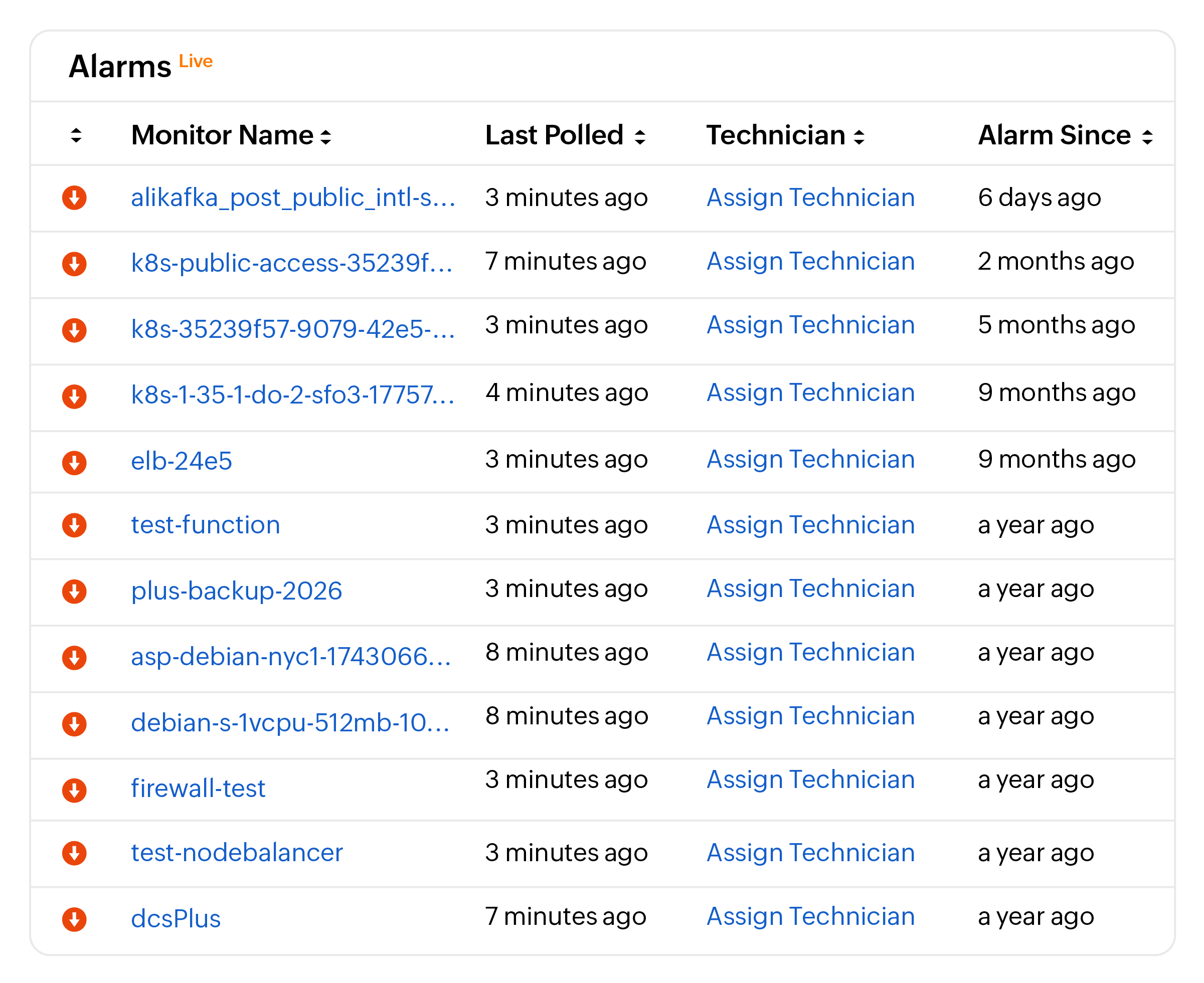
- 基于阈值的告警 : 为 ECS CPU 和内存、NLB 和 ALB 连接数以及 RDS 查询性能设置告警阈值,在问题升级之前将其捕获。
- 自动化事故工作流: 当检测到任何阿里云服务中的问题时,自动通知值班团队并触发运行手册。
- 跨服务影响分析: 识别受影响的 ECS 实例、RDS 数据库、PolarDB 集群和 WAF 策略,并与 ITSM 工具集成以自动化工单流程,加速解决。
资源管理
合理调整和优化阿里云基础设施
在阿里云上运行跨计算、网络和数据库的 40 余项服务时,资源蔓延是实实在在的成本驱动因素。ManageEngine 为团队提供利用率背景信息,以做出更明智的资源分配决策,而不仅仅是根据阈值发出告警。
- 从未充分利用的资源中回收预算 : 使用具有可配置 CPU、内存和吞吐量阈值的利用率报告,识别低使用率的 ECS 实例和闲置的 ApsaraDB Tair 或 Memcache 节点,以便在成本累积之前进行调整或整合。
- 在需求到来之前预测需求 : 分析 ECS、RDS 和 PolarDB 的历史利用率趋势,预测容量需求,避免临时扩展决策。
- 在正确时间获得正确视图 : 通过可定制的仪表板和定期报告跟踪 ECS 集群健康状况、负载均衡器性能和 RDS 指标,实现更快、更具数据驱动力的决策。